【论文阅读】In Search of an Understandable Consensus Algorithm
引言
共识一致性算法常用在分布式系统中,一个系统会有一个领导者,如GFS,我们需要有多个领导者副本来提高系统的容错性。但是之前的共识性算法经常采用Paxos,但是该算法很难理解。所以本文的作者重点面向可理解性提出了一个新的共识性算法Raft。主要做法是将大步骤分解成小步骤,然后尽量降低复杂度。
在具体关注其实现之前强烈建议去raft可视化中去学习一下基本的流程,以对其有个大概的印象,然后还可以参考这部分的介绍来学习动画中的内容:看动画轻松学会 Raft 算法
实现细节
基本概念
raft系统中各个成员有3种状态:leader, follower, or candidate
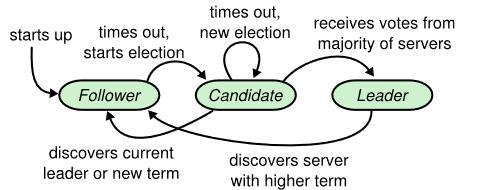
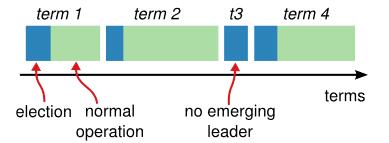
每一次开始选举leader到下一次为止都是一个term,一个term开始选举时也可能因为平分选票而导致选举leader失败,这样就会进入下一term的选举
服务器采用RPC进行通信,主要有两种信息:
- RequestVote,选举投票
- AppendEntries,复制日志条目(也当做心跳使用)
leader选举
每一个服务器在一定范围内随机生成一个等待时间,如果在该时间内没有收到leader的心跳,那么就认为leader下线了,就给自己的term+1,然后发起投票,希望自己成为leader。所以这也就需要保证让等待时间大于心跳信息发送的间隔时间。
服务器发起投票后有以下3种结果:
- 获得包括自己在内超过所有服务器半数的投票,自己成为leader
- 收到其他term>=自己的leader的信息,说明已经有leader了,自己变为follower
- 由于平分选票,谁都不能成为leader,再次等待随机时间后,再发起一轮投票
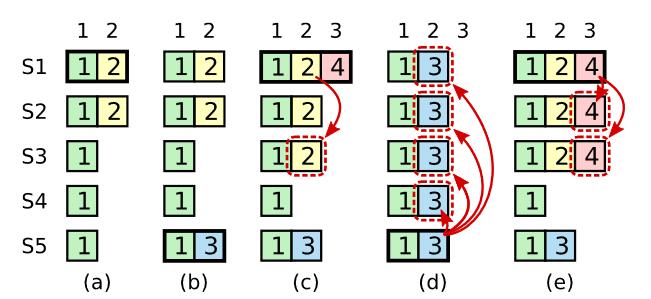
为了防止选举到的leader没有全部的commit的日志,规定:
- 发起投票的服务器如果没有自己拥有的日志新,则不给它投票。因为已经commit的日志肯定在超过半数的服务器上有留存,那么一个没有全部commit的日志的服务器就必然不能拿到超过半数的同意票。
- 新leader上台时,不会去尝试复制旧的日志,然后提交,它只会去专注于提交新的日志,并在将新的日志复制给了大半的服务器后,将之前所有的可能没提交的一并提交。这样子就避免了下图中(d)可能出现的错误情况。
日志复制
leader会接收用户发来的请求,并生成日志,然后将日志发送给各个follower,如果有包括自己在内超一半的服务器拥有了改日志,就将日志(也包含之前可能未提交的日志)commit,然后返回给用户执行结果。
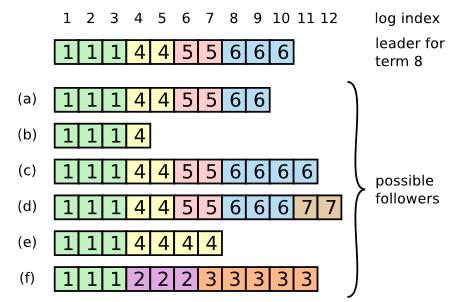
raft还通过以下特性来保持日志的一致性:
- 相同term相同index的日志内容相同
- 如果两个服务器某处日志的term和index都相同,那么他们之前的所有日志也相同
第一条的保证是来自于每个leader创建了日志之后不会再修改。
第二条的保证使用的是归纳法的思想,每次发送的AppendEntries都包含前一个日志的信息,必须要前一个日志信息相同才可以接受,否则就拒绝,然后leader会不断尝试依次递减发送上一个日志(leader会为每一个follower维护一个nextIndex,代表其需要发送的日志id),直到找到相同的为止,然后将往后的日志都发送过去。当然这部分匹配可以进行优化。
各个主机上的log条目可能千奇百怪,但是注意到只有超过一半的服务器拥有的日志才是可能提交的日志,才需要永久性保存,其他都是没有提交的日志,可以进行删除更新即可分析清楚。
成员变更
当集群中成员需要进行改变的,一个方式是停掉集群,然后各自修改配置,这时安全的,但是会导致部分时间集群服务不可用。另一种方法是在线修改,但是直接的在线修改可能会导致如下的问题,即加入server4、5之后,由于部分主机1,,还不知道,所以会导致出现两个leader。
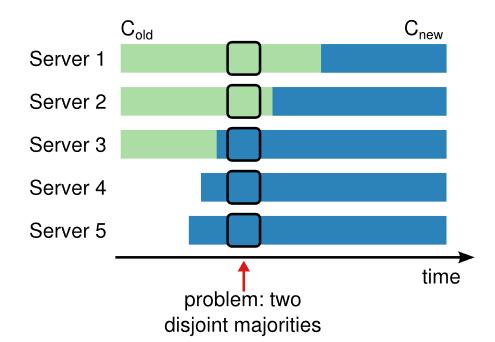
Raft提出的解决方案是采用两阶段的方法执行成员变更。
首先集群配置进行更新的时候,会将原本的配置Cold和新配置Cnew联合起来形成Cold,new,leader会将其复制给原本记录的其他人,一旦服务器收到了,就会把最新的配置设置为当前使用的,提交必须要要保证new和old中都有过半的服务器被使用了,然后再将Cnew复制给其他new中的服务器,一旦Cnew也被过半的new中的服务器收到了,就提交,然后整体配置就转为了Cnew。如下图所示,就避免了Cold和Cnew都能同时做决策的情况。
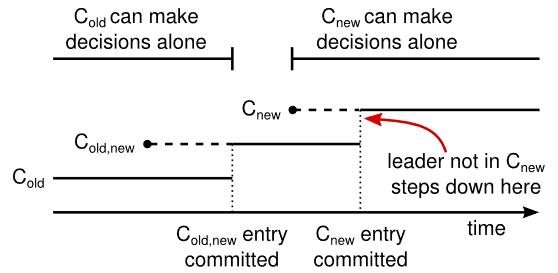
但是仍然还有几个问题需要解决:
- 新加入的服务器难以快速跟上进度。Raft将其先作为非投票的成为加入到集群中,赶上后再转为正常。
- leader可能不是new中的一部分。在Cnew提交后再进行将leader下线,所以在前面一段时间,其实leader在管理不属于他的集群。
- 不在Cnew被删除的服务器可能会影响集群可用性,因为他们不会再收到心跳,然后就会不断发起投票。Raft的解决办法是如果服务器认为leader还存在,即还没有等待超时,就会忽略投票请求,不会更新其term和给他投票。
日志压缩
长时间的运行会导致日志的堆积,可以通过生成快照将状态拷贝下来,然后再将不需要的日志删除,如下图所示。
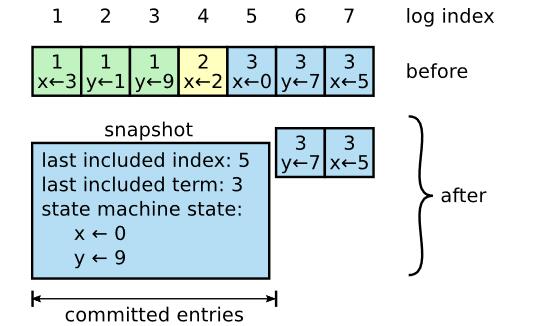
注意快照需要包含最后一个日志的信息,以让下一个日志生成的时候进行检查。
每个服务器独立进行快照生成,而不是由leader统一生成和发送,这是为了降低网络带宽消耗,降低系统复杂度。
新加入的服务器,或者特殊情况下的follower可能会需要leader将快照整个发送给它来初始化状态,follower在接收到到快照后会把快照最后一项之前的所有log删除。
此外还需要注意快照生成的频率,简单的方法是快照到一定大小后就进行生成。还需要避免写入快照对系统的影响,这可以通过写时复制的方法进行支持。
客户交互
客户端启动时,随机选择服务器,如果不是leader,该服务器会返回相关信息来帮助客户找到leader。如果leader宕机,客户请求会超时,然后再次尝试随机选择服务器来连接。
我们希望提供线性语义,但是raft实际上可能一个操作执行多次,例如leader在提交了之后马上宕机,然后没来得及返回给用户,然后用户可能会再次发送该请求,导致其二次执行。解决方法是让客户的每个请求都分配一个序号,如果接收到已经执行过的序号,就理解响应但是忽略执行。
对于只读操作,如果返回请求的leader马上被其他服务器替换,那么就面临返回过时信息的问题。所以raft需要保证新上台的leader知道哪些是已经执行了的,所以新上台的leader需要提交一个无操作的条目,来同步。raft也让leader在处理只读请求时与大多数成员交换心跳信息来处理此问题。
参考资料
- https://raft.github.io/
- https://raft.github.io/raft.pdf
- https://mit-public-courses-cn-translatio.gitbook.io/mit6-824/lecture-06-raft1
- https://willzhuang.github.io/2018/03/04/Raft%E8%AE%BA%E6%96%87%E7%BF%BB%E8%AF%91/
- https://thesecretlivesofdata.com/raft/
- https://www.cnblogs.com/Finley/p/14467602.html
- https://acehi.github.io/thesecretlivesofdata-cn/raft/
- https://zhuanlan.zhihu.com/p/32052223