【MIT6.824】lab2B-log replication 实现笔记
引言
lab2B的实验要求如下:
Implement the leader and follower code to append new log entries, so that the go test -run 2B tests pass.
- Hint: Run git pull to get the latest lab software.
- Hint: Your first goal should be to pass TestBasicAgree2B(). Start by implementing Start(), then write the code to send and receive new log entries via AppendEntries RPCs, following Figure 2. Send each newly committed entry on applyCh on each peer.
- Hint: You will need to implement the election restriction (section 5.4.1 in the paper).
- Hint: One way to fail to reach agreement in the early Lab 2B tests is to hold repeated elections even though the leader is alive. Look for bugs in election timer management, or not sending out heartbeats immediately after winning an election.
- Hint: Your code may have loops that repeatedly check for certain events. Don’t have these loops execute continuously without pausing, since that will slow your implementation enough that it fails tests. Use Go’s condition variables, or insert a time.Sleep(10 * time.Millisecond) in each loop iteration.
- Hint: Do yourself a favor for future labs and write (or re-write) code that’s clean and clear. For ideas, re-visit our the Guidance page with tips on how to develop and debug your code.
- Hint: If you fail a test, look over the code for the test in config.go and test_test.go to get a better understanding what the test is testing. config.go also illustrates how the tester uses the Raft API.
主要的要求就是在lab2A完成领导者选举的基础上实现日志的复制,代码可以在https://github.com/slipegg/MIT6.824中得到。
测试环境
由于整个lab是在模拟环境中进行的,所以我们需要先简单连接一下实验是如何测试和运行的。
查看测试脚本可知,每次客户端提交用户请求都是通过调用leader的Start函数来实现的,故Start函数在接收到了日志后就需要主动开始日志复制的过程。
而当leader将日志复制到大多数节点后,除了各个节点自己需要标定这个日志已经提交了外,还需要将这个日志已经提交了的信息返回给客户端,这个信息的结构为ApplyMsg,它通过applyCh这个channel来实现的,实际代码中我们可能需要启用一个go协程来在需要时进行异步执行,如下所示。
1 | |
日志复制代码
在具体实现时,发现Raft论文中的代码结构图对于编写整个代码非常有帮助,所以在这里也贴出来。
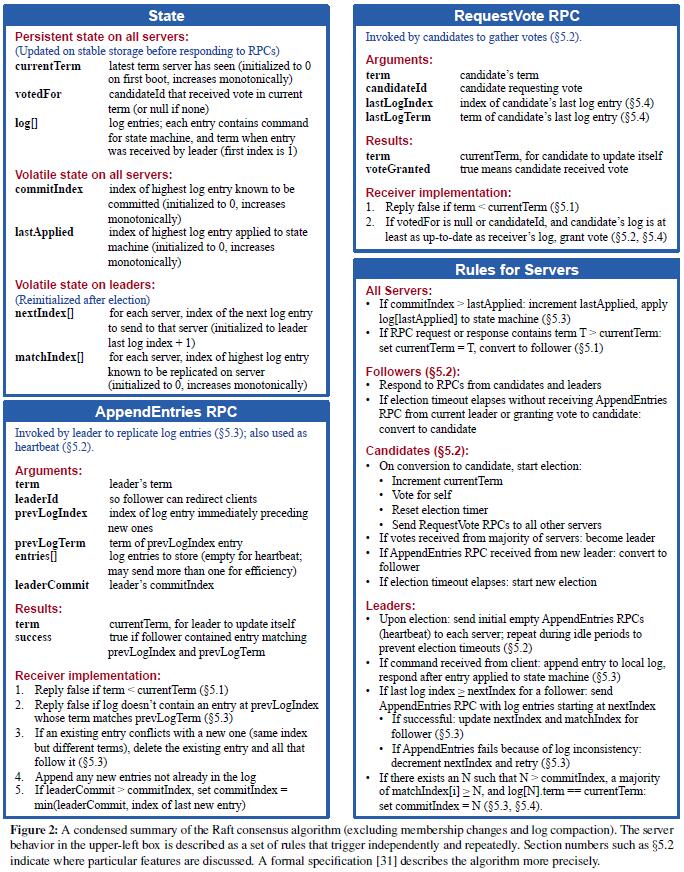
项目的整体流程及思路我整理成了如下的过程.

- Start: leader节点接受新的命令,将命令添加到自己的日志中,并向其他所有节点发送日志复制请求。
- ReplicateLog: 由于日志复制可能会失败,所以需要一个循环来不断重试,直到日志复制成功。复制时通过RPC来调度其他节点的AppendEntires函数,并在得到返回结果后调用handleAppendResponse进行处理.
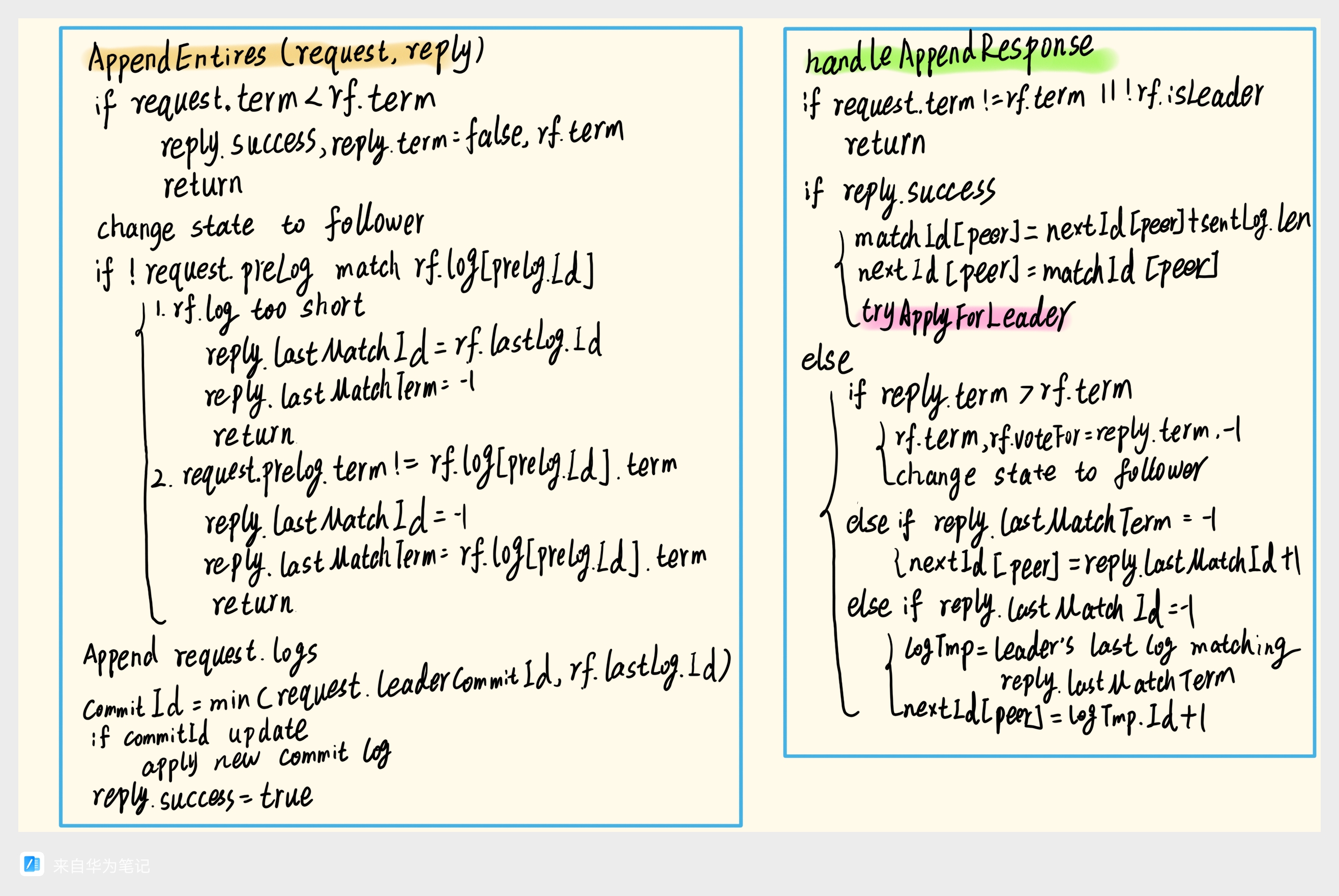
- AppendEntires: 节点接受到日志复制请求后,必须先要判定对方是不是term大于等于自己的term,如果不是就是过时的leader,直接拒绝。由于这个函数也会被当做心跳包来使用,所以收到后还需要自动转变为follower。然后再判断leader中记录的要复制的前一个日志preLog是不是和自己的一致,如果不一致,有两种可能:
- 自己的日志更短,都没复制到preLog这一步,所以直接拒绝,并主动在reply中返回自己的最后一个日志的id。
- 有preLog,但是日志的term不一致,也就是自己有冗余的错误的日志,这里是可删可不删后面的日志,论文中采取的方法是返回错误,然后一个一个往前找对得上的日志,而由于这个速度太慢了,会导致测试不通过,所以这里采取的方法是返回本节点的preLog的term,这个term肯定是比leader更小的,然后等待leader找到这个term的最后一个日志,尝试全部复制过来,这样可以加速日志的复制。
如果都一致了,就加入到自己的日志中,然后再去对比参看leader有没有新commit日志,如果有就更新自己的commitIndex,并将他们apply,返回给客户端。
- handleAppendResponse: 这个函数是用来处理AppendEntires的返回结果的,首先需要判定自己还是不是leader,term有没有变,如果不是leader或者term变了,就不继续处理。如果返回成功,那么就更新自身记录的对应节点的matchId和nextId,如果返回失败,则对应有几种可能:
- 发现比自己term还高的节点,说明自己的term过时了,需要转变为follower。
- 对方的日志比自己以为的要短,需要将该节点nextId往前移动到对应的位置。
- 对方的preLog的term不一致,那么就需要找到perLog的term对应的最后一个日志,然后将nextId移动到这个位置的下一个位置。

- TryApplyForLeader: 这里把所有的matchId倒序排序,然后查看中间这个位置的matchId是不是变化了,如果变化了,就去查看这个最新的newCommitId对应的term是不是等于自己的term,如果不是,还是不处理,这对应了论文中的5.4.2节中的规则;如果是,就更新自己的commitIndex,并将这个日志apply。
- Vote: 如果投票的请求的term比自己的term小,那么就是过时的请求,直接拒绝。如果相同,同时自己已经投票给了其他节点,那么也拒绝。如果请求的term比自己的term大,那么就转变为follower,并更新term。(这一步是为了处理有些时候有的节点进入了网络分区,term不断变大,新接入之后发起投票,这是否应该大伙都转为follower,但是可能受限于日志不符合,不能成为leader,然后大家在新的term中重新选举,统一得到一个leader。)然后检查请求的前一个日志是否是最新的,最新的规则是要么这个前一个日志的term比自己的term大,要么term相同但是index相同或者更大,如果不是,就拒绝。最后如果都通过了,就投票给对方。
实验结果
使用了之前写的自动测试实验脚本的测试结果如下,可以看到它通过了1000次的测试。

测试实例-TestBackup2B分享
测试过程中被TestBackup2B困扰了很久这里分享一下这个测试示例。
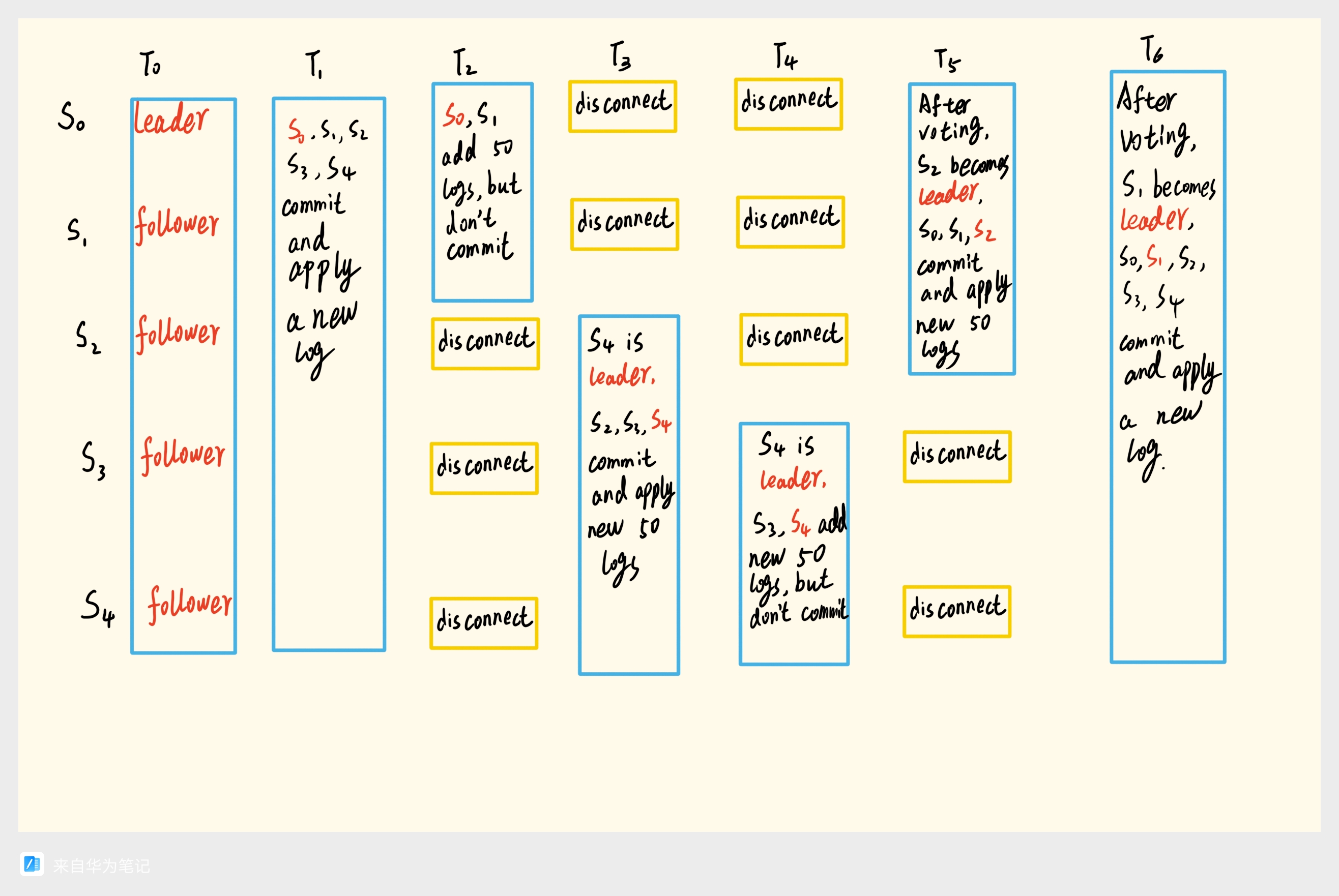
可以看到测试主要是通过网络中断来进行测试的。一开始这个测试没通过,经过查看日志得知是在T5时刻没有选举出正确的leader,两个原因:
- 在选举时判断每个节点最后的日志是不是最新的时候写错了,只比较自己的最后的日志相较于Candidate的最后的日志是不是一样长,而没有比较Candidate的最后的日志的term是不是比自己的大,这就导致了在T5时刻本来应该只有S2才能被选举出来,但是我确认S0和S1也可以被选举出来。
- 在比较最后的日志前没有提前先判断对方的term是不是比自己的term大,由于S1在disconnect阶段一直在尝试重新选举,所以其term会很大,如果其他节点在接收到S1投票请求后没有转变为follower,并更新term会导致S1一直拒绝其他人的选举投票,而自己又由于日志不够新,被S2拒绝,导致选举一直无法完成。
【MIT6.824】lab2B-log replication 实现笔记
http://example.com/2024/03/19/MIT6-824lab2B/