引言 lab3A的实验要求如下:
Your first task is to implement a solution that works when there are no dropped messages, and no failed servers.
You’ll need to add RPC-sending code to the Clerk Put/Append/Get methods in client.go, and implement PutAppend() and Get() RPC handlers in server.go. These handlers should enter an Op in the Raft log using Start(); you should fill in the Op struct definition in server.go so that it describes a Put/Append/Get operation. Each server should execute Op commands as Raft commits them, i.e. as they appear on the applyCh. An RPC handler should notice when Raft commits its Op, and then reply to the RPC.
You have completed this task when you reliably pass the first test in the test suite: “One client”.
Add code to handle failures, and to cope with duplicate Clerk requests, including situations where the Clerk sends a request to a kvserver leader in one term, times out waiting for a reply, and re-sends the request to a new leader in another term. The request should execute just once. These notes include guidance on duplicate detection. Your code should pass the go test -run 3A tests.
lab3B的实验要求如下:
Modify your kvserver so that it detects when the persisted Raft state grows too large, and then hands a snapshot to Raft. When a kvserver server restarts, it should read the snapshot from persister and restore its state from the snapshot.
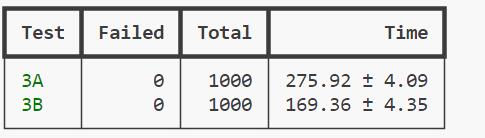
总体而言,我们需要在lab2所实现的raft系统上构建一个简单的key-value存储系统,这个系统需要支持客户端的Put/Append/Get操作,同时需要支持Raft的持久化和快照功能。本系统的要求是线性一致的,即每个动作都能被当做是在一个唯一的时刻进行原子执行的,具体一致性相关的内容,可查看之前的文章:分布式系统中的线性一致性 。https://github.com/slipegg/MIT6.824 中得到。所有代码均通过了1千次的测试。
lab3A 实现 lab3A不涉及到Raft的快照功能,主要是要完成整个系统功能的构建。在实验时测试3A时,测试代码将会不断调用客户端的Put/Append/Get操作,然后检查是否所有的操作都被正确执行。
首先通过一个map来存储key-value,如下中的KVMachine所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 type KVMachine struct {map [string ]string func (kv *KVMachine) string ) (string , Err) {if !ok {return "" , ErrNoKeyreturn value, OKfunc (kv *KVMachine) string , value string ) Err {return OKfunc (kv *KVMachine) string , value string ) Err {if !ok {return OKreturn OKfunc newKVMachine () return &KVMachine{make (map [string ]string )}
然后是Client端的实现,首先Client在初始化时会随机生成一个数字当做自己的id,同时它也专门维护每个请求的唯一id。Client的Put/Append/Get操作都是通过RPC调用Server端的Put/Append/Get操作来实现的,如果Server端返回了错误,告诉当前Server不是leader,那么Client就会重新发送请求到下一个Server去,直到找到leader并执行请求成功了为止。Client端的PutAppend/Get操作的实现如下,Get也是类似,就是错误处理稍微不同,不再赘述:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func (ck *Clerk) string , value string , op string ) {"{Clinetn-%d} try to %s {'%v': '%v'}\n" , ck.clientId, op, key, value)for {var reply PutAppendReplyif ck.servers[ck.leaderId].Call("KVServer.PutAppend" , &args, &reply) && reply.Err == OK {"{Clinetn-%d} %s {'%v': '%v'} success\n" , ck.clientId, op, key, value)break else {1 ) % int64 (len (ck.servers))100 * time.Millisecond)
每个Server端都会维护一个KVMachine,并且也连接到一个专门的raft节点,它的主要作用就是将客户端的请求转化为raft节点的日志,然后等待raft节点将日志提交后接收到raft节点的信息,将日志应用到自己的KVMachine中,然后返回给客户端。
将客户端请求转化为日志传递给raft部分的代码如下,Get请求也是类似的。注意这里对于重复执行过的Put、Append会直接进行返回,因为运行结果只会是OK,所以直接返回OK即可,而Get请求不需要判断是否重复执行,因为Get请求需要获取的实最新的数据,来一次就执行一次即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 func (kv *KVServer) defer DPrintf("{KVServer-%d} finishes %s {%s: %s}, the reply is %v\n" , kv.me, args.Op, args.Key, args.Value, reply)if kv.isDuplicate(args.ClientId, args.RequestId) {return if !isLeader {return "{KVServer-%d} try to %s {%s: %s} with logId: %d\n" , kv.me, args.Op, args.Key, args.Value, logId)select {case result := <-ch_putAppend:case <-time.After(MaxWaitTime):go func () delete (kv.notifyChs_PutAppend, logId)
当raft节点将日志分发给了大部分的节点后,就可以将日志提交,然后提醒Server端将日志应用到自己的KVMachine中。代码如下所示。注意对于Get请求,需要判断这时候节点是不是leader,Term是否还相同,以防止由于applyCh传递时间过长,这时候节点已经不是leader,没有最新的数据了。对于Put、Append操作需要判断是否已经是重复执行过的操作,如果是,直接标记为OK即可,不需要再次执行,同样也需要判断当前还是不是leader,如果是才有权限返回给客户端执行结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 func (kv *KVServer) for !kv.killed() {select {case msg := <-kv.applyCh:if msg.CommandValid {if msg.CommandIndex <= kv.lastApplied {"{KVServer-%d} reveives applied log{%v}" , kv.me, msg)continue if op.GetArgs != nil {"{KVServer-%d} apply get %v." , kv.me, op.GetArgs.Key)if currentTerm, isLeader := kv.rf.GetState(); isLeader && currentTerm == msg.CommandTerm {if ch, ok := kv.notifyChs_Get[msg.CommandIndex]; ok {else if op.PutAppendArgs != nil {var reply PutAppendReplyif kv.isDuplicate(op.PutAppendArgs.ClientId, op.PutAppendArgs.RequestId) {"{KVServer-%d} receives duplicated request{%v}\n" , kv.me, msg)else {"{KVServer-%d} apply %s {%s: %s}.\n" , kv.me, op.PutAppendArgs.Op, op.PutAppendArgs.Key, op.PutAppendArgs.Value)if op.PutAppendArgs.Op == "Put" {else if op.PutAppendArgs.Op == "Append" {if _, isLeader := kv.rf.GetState(); isLeader {if ch, ok := kv.notifyChs_PutAppend[msg.CommandIndex]; ok {else {"{KVServer-%d} receives unknown command{%v}" , kv.me, msg)if kv.isNeedSnapshot() {"{KVServer-%d} needs snapshot\n" , kv.me)
lab3B 实现 这里主要需要实现Server的持久化和快照功能,每个Server有一个自己的persister,其结构如下:
1 2 3 4 5 type Persister struct {byte byte
其中raftstate部分是raft节点存储自身持久化状态用的,而snapshot节点是用来给Server存储自身状态用的,包括了Server的KVMachine状态以及lastPutAppendId。在Server启动时,会从persister中读取raftstate和snapshot,然后根据raftstate来初始化raft节点,根据snapshot来初始化KVMachine和lastPutAppendId。代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 func (kv *KVServer) byte ) {if snapshot == nil || len (snapshot) < 1 {return var kvMachine KVMachinevar lastPutAppendId map [int64 ]int64 if d.Decode(&kvMachine) != nil ||nil {"{KVServer-%d} reloadBySnapshot failed\n" , kv.me)"{KVServer-%d} reloadBySnapshot succeeded\n" , kv.me)
当Server在apply节点时,按照要求,如果raft的日志信息过大,就触发快照功能,将Server的状态保存到snapshot中,同时让raft节点生成快照。如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 func (kv *KVServer) int ) {new (bytes.Buffer)if mr, lr := e.Encode(kv.kvMachine), e.Encode(kv.lastPutAppendId); mr != nil ||nil {"{KVServer-%d} snapshot failed. kvMachine length: %v, result: {%v}, lastPutAppendId: {%v}, result: {%v}," ,len (kv.kvMachine.KV), mr, kv.lastPutAppendId, lr)return "{KVServer-%d} snapshot succeeded\n" , kv.me)
由于快照的引入,Server也可能需要apply快照,即对上述的applier函数再多加一个msg类型的判断,如下所示:
1 2 3 4 5 6 else if msg.SnapshotValid {
相关问题 为什么Get操作不能直接读leader的本地数据? 在Raft系统中,当面临网络分区情况时,原本的leader如果位于一个小分区,那么他就不知道其实大分区中已经有了一个新leader了,这样如果client还是连接的原本的leader,并且是直接读取该leader的本地数据,那么就会面临读取到过时数据的问题,导致系统线性不一致。
所以解决这个问题的关键在于确定节点真的是leader,这里采取的是一个简单的方法,即将这个Get操作作为一个log日志放入raft系统中,直到raft系统将这个log日志提交后,才返回。实际上还有优化的空间,一个方法是在raft接受到了一个Get操作后,立刻执行心跳,如果接收到了过半的节点的心跳回复,那么就证明了这个节点是真的leader,这样就可以直接返回数据了,这就避免了将Get操作放入raft系统中的开销。还有一种方法是叫做Lease Read,它的吞吐更大,详情可参考深入浅出etcd/raft —— 0x06 只读请求优化 。
applier中是否有机会出现重复执行的put、append操作? 有机会出现。例如当客户端发送后,Server将其提交给了Raft,但是Raft没有在规定时间内返回,那么就会返回超时,然后客户端再去循环提交一轮,再一次提交给这个节点的时候,节点此时可能还是没有收到Raft的返回,所以会再次提交给Raft,这样就会出现重复提交的情况。而在applier中就会只执行第一次提交的操作,后续的提交都会被忽略。
只用lastPutAppendId记录最后一次的Put、Append操作的id是否可行? 可行。因为系统中Put、Append操作的结果只会是ok,所以不需要记录每次的Put、Append操作的id,同时由于raft系统中一旦apply了就是永久apply了,并且前面的操作也都apply了,不存在回退的情况,所以如果当前操作的id小于最新一次Put、Append操作的id,那么就说明是重复执行了,直接返回ok即可。
运行结果 代码通过了1k次的测试,如下图所示。
参考资料