万字总结!Docker简介及底层关键技术剖析
Docker 简介
Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口(类似 iPhone 的 app)。几乎没有性能开销,可以很容易地在机器和数据中心中运行。最重要的是,他们不依赖于任何语言、框架或包装系统。
Docker 基于 Linux 内核的 cgroup,namespace,以及 UnionFS 等技术,对进程进行封装隔离,属于操作系统层面的虚拟化技术。由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。最初实现是基于 LXC,从 0.7 版本以后开始去除 LXC,转而使用自行开发的 libcontainer,从 1.11 版本开始,则进一步演进为使用 runC 和 containerd。
runc 是一个 Linux 命令行工具,用于根据 OCI容器运行时规范 创建和运行容器。
containerd 是一个守护程序,它管理容器生命周期,提供了在一个节点上执行容器和管理镜像的最小功能集。
Docker 与LXC 的区别
LXC的全名为Linux Container,它是一种轻量级的Linux内核容器虚拟化技术,允许在同一主机上运行多个相互隔离的Linux Container,每个容器都有自己的完整的文件系统、网络、进程和资源隔离环境。
LXC与传统的虚拟机技术不同,LXC不需要运行完整的操作系统镜像。LXC使用Linux内核提供的cgroups和命名空间(Namespaces)功能来实现容器隔离。它有效地将由单个操作系统管理的资源划分到孤立的组中,以更好地在孤立的组之间平衡有冲突的资源使用需求。
docker 出现之初,便是采用了 lxc 技术作为 docker 底层,对容器虚拟化的控制。后来随着 docker 的发展,它自己封装了 libcontainer (golang 的库)来实现 Cgroup 和 Namespace 控制,从而消除了对 lxc 的依赖。
现在Docker相较于LXC已经有了十足的发展,其生态也更加完善。主要有以下几个方面的区别。
- 抽象级别: Docker 提供了更高级别的抽象,它强调应用程序和服务的容器化,提供了易于使用的工具和接口,如 Docker CLI、Docker Compose 等, Docker 的目的是为了尽可能减少容器中运行的程序,减少到只运行单个程序,并且通过 Docker 来管理这个程序,有了 Docker,可以从底层应用程序通过 Docker 来配置,网络,存储和编排。而 LXC 更接近于操作系统级的虚拟化,需要更多的系统管理和配置工作,LXC 用正常操作系统环境回避网络、存储等问题,并且因此可以快速兼容所有应用程序和工具,以及任意管理和编制层次,来替代虚拟机。
- 镜像构建方式: Docker 使用 Dockerfile 来定义镜像的构建过程,这使得镜像的构建和管理变得非常简单和可重复。而在 LXC 中,镜像的创建和管理相对复杂,它没有类似Dockerfile的镜像构建方式,它使用基于文件系统的容器模板来创建容器。
- 资源隔离: Docker 相比于 LXC 增加了更多的资源隔离和管理功能,如 CPU、内存、网络等资源的控制。这使得 Docker 更适合于生产环境中的容器化部署。
- 占用资源不同: 相对于LXC,Docker的容器启动速度更快,占用资源更少。这是因为Docker容器使用了更多的技术手段来优化容器启动和运行的效率,例如使用联合文件系统(UnionFS)来共享文件系统,使用镜像层缓存来加速镜像构建,使用Docker镜像仓库等。
- 生态系统: Docker 有着庞大的生态系统,包括 Docker Hub(用于分享和拉取镜像)、Docker Swarm(用于容器编排和集群管理)、Docker Compose(用于多容器应用编排)等工具和服务。相比之下,LXC 的生态系统相对较小。
Docker 与传统虚拟化的区别
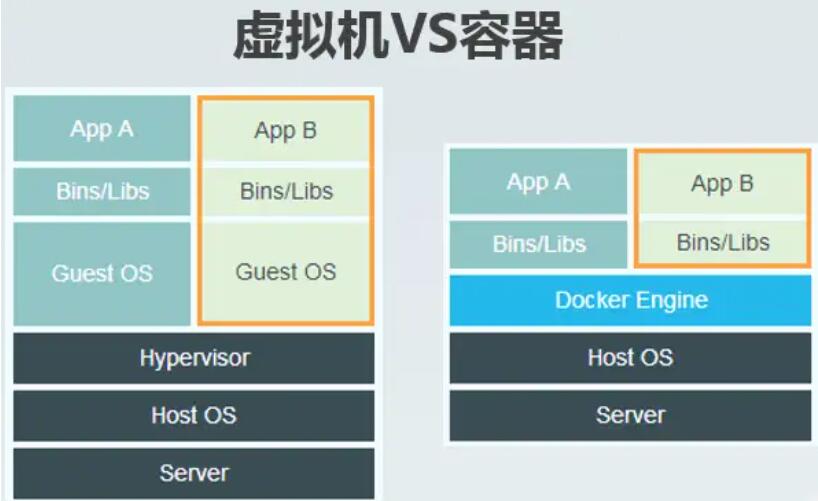
下面的图片比较了 Docker 和传统虚拟化方式的不同之处。传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便。
其区别可以从以下几点展开。
| 对比项 | Docker 容器 | 虚拟机 |
|---|---|---|
| 隔离性 | 较弱的隔离,属于进程之间的隔离,各个容器共享宿主机的内核 | 强隔离,属于系统级别的隔离,会模拟出一整个操作系统和硬件,各个虚拟机之间完全隔离 |
| 启动速度 | 秒级 | 分钟级 |
| 镜像大小 | 一般为 MB | 一般为 GB |
| 托管主体 | Docker Engine 在操作系统和 Docker 容器之间进行协调。 | 虚拟机监控器在计算机的物理硬件和虚拟机之间进行协调。 |
| 运行性能 | 接近原生(损耗小于 2%) | 损耗小于 15% |
| 镜像可移植性 | 平台无关 | 平台相关 |
| 占用资源量 | Docker 只是一个进程,只需要将应用以及相关的组件打包,在运行时占用很少的资源,单机上可支持上千个容器 | 虚拟机是一个完整的操作系统,需要占用大量的磁盘、内存和 CPU 资源,一般一个主机上只能支持几十个虚拟机 |
| 安全性 | 1. 容器内的用户从普通用户权限提升为 root 权限,就直接具备了宿主机的 root 权限。 2. 容器中没有硬件隔离,使得容器容易受到攻击。 |
1. 虚拟机租户 root 权限和主机的 root 虚拟机权限是分离的。 2. 硬件隔离技术:防止虚拟机突破和宿主机交互。 |
| 高可用性 | docker对业务的⾼可⽤⽀持是通过快速重新部署实现的。 | 虚拟化具备负载均衡,⾼可⽤,容错,迁移和数据保护等经过⽣产实践检验的成熟保障机制,VMware可承诺虚拟机99.999%⾼可⽤,保证业务连续性。 |
| 资源共享 | 按需共享,依据cgroups进行控制。 | 按固定数量共享,在虚拟机映像的配置要求中设置。 |
什么情况下只能用虚拟机
- 需要操作系统级别的隔离:虚拟机提供了更高的隔离性,每个虚拟机都有自己的操作系统,可以实现不同操作系统之间的隔离,虚拟机可以做到这一个主机上同时运行多个不同操作系统的虚拟机,且互不影响。而Docker容器调用的实际上是宿主机的内核,因此容器之间共享宿主机的内核,无法实现操作系统级的隔离,例如如果 Docker 容器中运行的应用程序存在内核漏洞或者容器内部进行了特权操作(例如修改主机文件系统),这可能会导致容器越过 Docker 的隔离性,影响到宿主机或其他容器。也是因此在一些隔离性要求较高的场景下,例如云上的多租户场景,就还是需要使用虚拟机。
- 需要更强的资源隔离和控制:虚拟机可以对 CPU、内存、磁盘空间等以固定的单位进行分配,而Docker 容器的资源隔离和控制较为简单,通常是通过限制容器的 CPU 使用率、内存限制等来实现。
总的来说,Docker或者说容器技术和虚拟机并非简单的取舍关系,如果你希望一个完全隔离的和资源有保障的环境,那么虚拟机是你的不二选择;如果你只希望进程之间相互隔离,同时拥有轻量化的属性,那么linux容器技术或者Docker,才是更好的选择。
Docker的重要概念
镜像(Image)
当我们使用docker容器时,首先需要首先先下载一个对应的镜像,镜像相比于虚拟机的进行更加轻量,原因在于它实际上主要只是一个rootfs(当然还包括一些额外的配置文件)。对于一个精简的 OS ,rootfs 可以很小,只需要包括最基本的命令、工具和程序库即可,因为底层直接共用 Host 主机的 kernel。
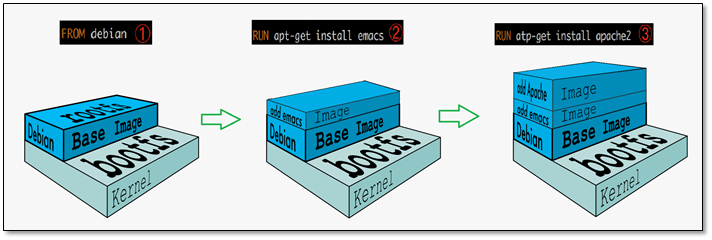
镜像中的rootfs采取的是分层存储的方式,即每个镜像都是由多个只读层叠加而成。这种分层存储的特性使得镜像的复用、定制、共享变的更为容易。同时,每一层都可以被容器读取,容器的文件系统就是这些层的叠加。镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。
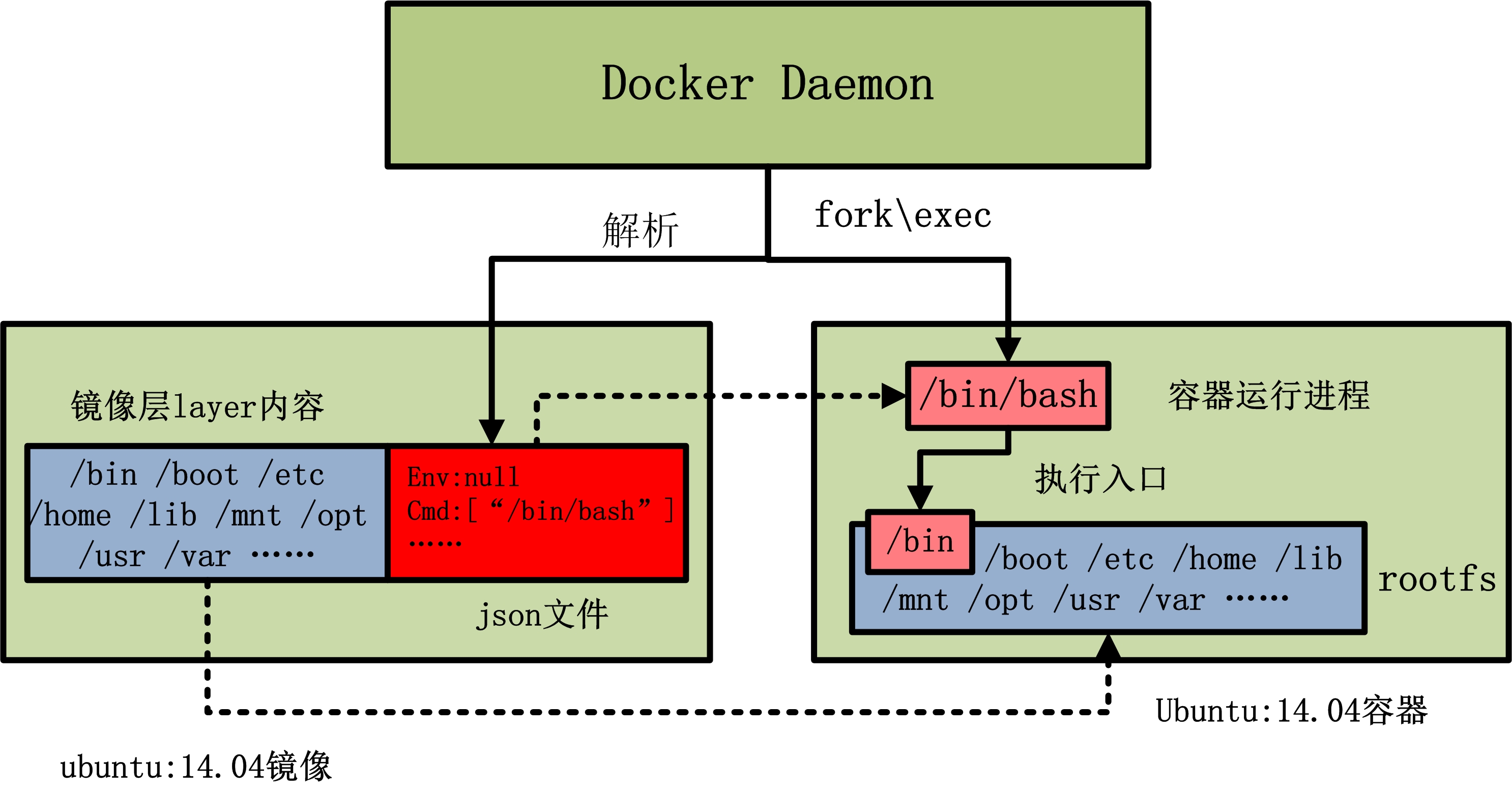
从上图中我们可以看到,当由 ubuntu:14.04 镜像启动容器时,ubuntu:14.04 镜像的镜像层内容将作为容器的 rootfs;而 ubuntu:14.04 镜像的 json 文件,会由 docker daemon 解析,并提取出其中的容器执行入口 CMD 信息,以及容器进程的环境变量 ENV 信息,最终初始化容器进程。当然,容器进程的执行入口来源于镜像提供的 rootfs。
rootfs
rootfs代表了一个系统中的根文件系统,在传统的 Linux 操作系统内核启动时,首先挂载一个只读的 rootfs,当系统检测其完整性之后,再将其切换为读写模式。
在docker容器中,rootfs是docker容器在启动时内部进程可见的文件系统,即docker容器的根目录。rootfs通常包含一个操作系统运行所需的文件系统,例如可能包含典型的类 Unix 操作系统中的目录系统,如 /dev、/proc、/bin、/etc、/lib、/usr、/tmp 及运行docker容器所需的配置文件、工具等。
docker实现rootfs依靠的实联合挂载技术。
联合挂载(UnionFS)
最新的docker采用的联合挂载技术为overlay2。对于overlay2,它的主要作用就是将一堆目录下的内容联合挂载到一个目录下,它包含以下几个目录:
- LowerDir:只读层,包含镜像的各个层。
- UpperDir:可读写层,容器运行时的写入操作都会在这个目录下进行。
- WorkDir:工作基础目录,挂载后内容会被清空,且在使用过程中其内容用户不可见。
- MergeDir:合并目录,是 LowerDir 和 UpperDir 的合并结果,本身没有任何文件,只是一个挂载点。
在合并的目录中进行操作时,各个目录之间有上下顺序,上层目录的同名文件会遮盖住下层的文件。如果对LowerDir中的文件进行了修改,那么实际的文件是不会改变的,而是会在UpperDir中对其进行拷贝,然后在UpperDir中进行修改,这也称为写时复制技术。如果对LowerDir中的文件进行删除,那么实际的文件也不会被删除,而是在UpperDir中创建一个同名文件,并将其标记为删除状态。
docker镜像的完整分层
一个容器完整的层应由三个部分组成:
- 镜像层:也称为rootfs,提供容器启动的文件系统。rootfs也就是image中提供的文件。
- init层: 用于修改容器中一些文件如/etc/hostname,/etc/hosts,/etc/resolv.conf等。需要这一层的原因是当容器启动时候,这些本该属于image层的文件或目录,比如hostname,用户需要修改,但是image层又不允许修改,所以启动时候通过单独挂载一层init层,通过修改init层中的文件达到修改这些文件目的。
- 容器层:使用联合挂载统一给用户提供的可读写目录。当不对容器进行任何操作时,容器层是空的,当容器中有文件写入时,这些文件会被写入到容器层。
容器
容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的命名空间、文件系统、网络配置等。
如上所述,容器在运行时会添加一层可读写的容器层,其生命周期与docker一致。按照 Docker 最佳实践的要求,容器不应该向其存储层内写入任何数据,容器存储层要保持无状态化。所有的文件写入操作,都应该使用 数据卷(Volume)、或者 绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。
厂库
为了便于镜像的上传和下载,我们就需要一个集中的存储、分发镜像的服务,Docker Registry 就是这样的服务。一个 Docker Registry 中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 <仓库名>:<标签> 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。
仓库名经常以 两段式路径 形式出现,比如 jwilder/nginx-proxy,前者往往意味着 Docker Registry 多用户环境下的用户名,后者则往往是对应的软件名。
最常使用的 Registry 公开服务是官方的 Docker Hub,这也是默认的 Registry,并拥有大量的高质量的官方镜像。除此以外,还有 Red Hat 的 Quay.io;Google 的 Google Container Registry,Kubernetes 的镜像使用的就是这个服务;代码托管平台 GitHub 推出的 ghcr.io。
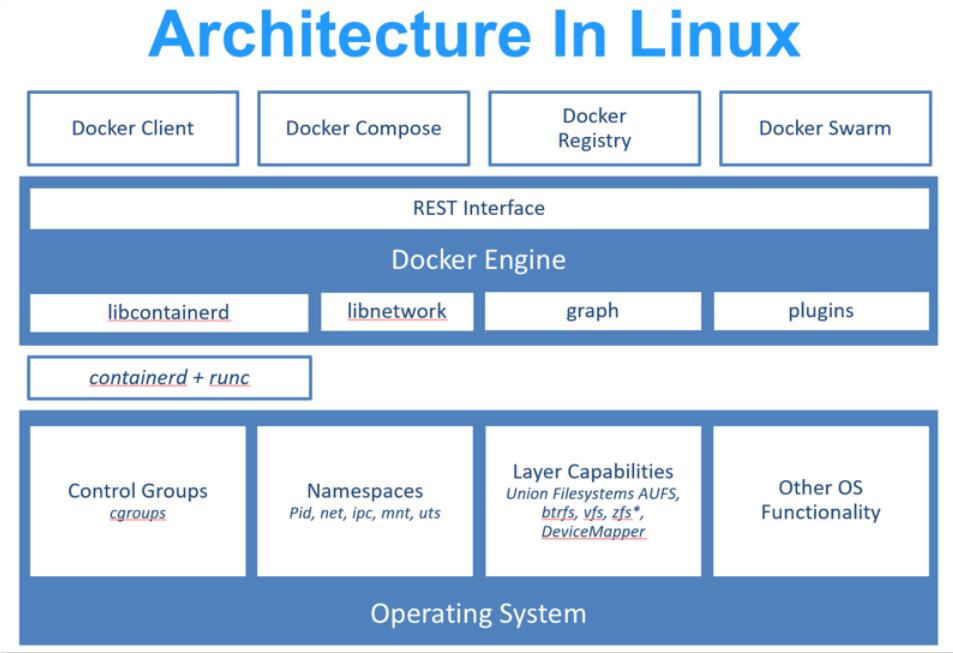
Docker 程序架构
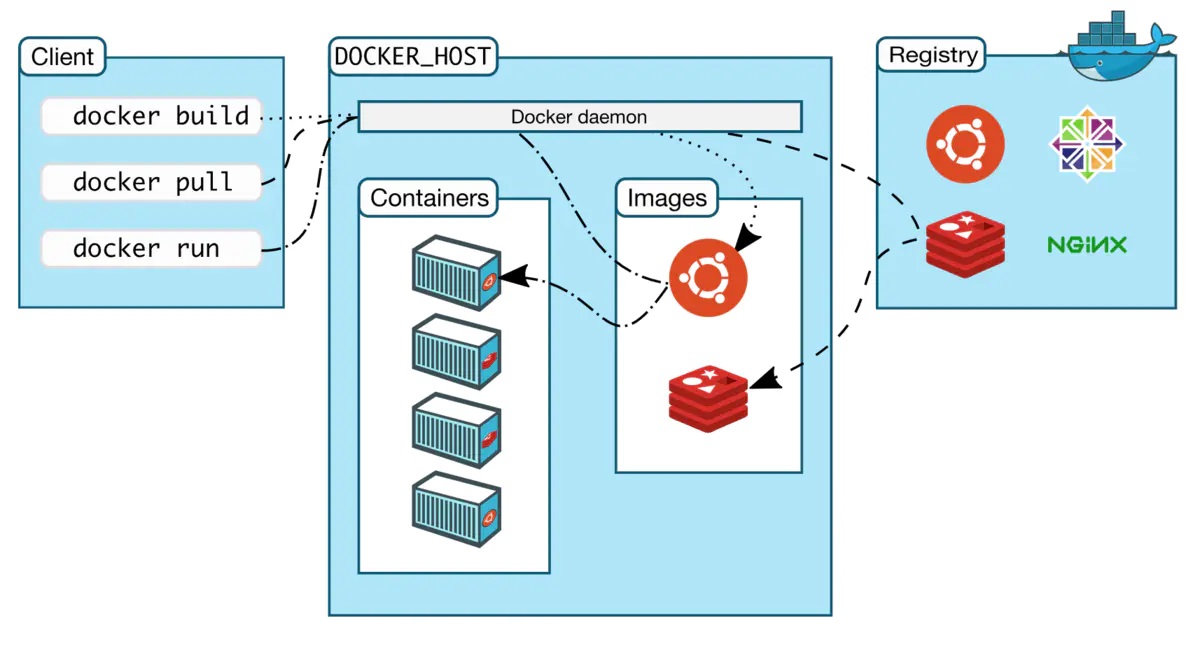
Docker 是一个客户端-服务器(C/S)架构程序。Docker 客户端只需要向 Docker 服务器或者守护进程发出请求,服务器或者守护进程将完成所有工作并返回结果。Docker 提供了一个命令行工具以及一整套 RESTful API。你可以在同一台宿主机上运行 Docker 守护进程和客户端,也可以从本地的 Docker 客户端连接到运行在另一台宿主机上的远程 Docker 守护进程。
Docker 服务端是 Docker 所有后台服务的统称。其中 dockerd 是一个非常重要的后台管理进程,它负责响应和处理来自 Docker 客户端的请求,然后将客户端的请求转化为 Docker 的具体操作。例如镜像、容器、网络和挂载卷等具体对象的操作和管理。
Docker 从诞生到现在,服务端经历了多次架构重构。起初,服务端的组件是全部集成在 docker 二进制里。但是从 1.11 版本开始, dockerd 已经成了独立的二进制,此时的容器也不是直接由 dockerd 来启动了,而是集成了 containerd、runC 等多个组件。
Docker 关键底层技术
Linux 命名空间、控制组和 UnionFS 三大技术支撑了目前 Docker 的实现,也是 Docker 能够出现的最重要原因,此外Docker网络、Docker存储也尤为重要。UnionFS前面已经介绍过了,不再赘述。
Linux 命名空间(namespace)
命名空间是 是 Linux 提供的一种内核级别环境隔离的方法,本质就是对全局系统资源的一种封装隔离。每个容器都有自己单独的命名空间,运行在其中的应用都像是在独立的操作系统中运行一样。命名空间保证了容器之间彼此隔离,互不影响。
目前linux内核支持以下6种命名空间:
- PID命名空间: 使得容器内的进程拥有独立的进程空间。在容器中运行ps -ef,只能看到容器内的进程,而看不到宿主机上的进程。
- net命名空间: pid 命名空间将进程pid情况进行了隔离,但是网络端口还是共享 host 的端口。网络隔离是通过 net 命名空间实现的, 每个 net 命名空间有独立的网络设备,IP 地址,路由表,/proc/net 目录。这样每个容器的网络就能隔离开来。Docker 默认采用 veth 的方式,将容器中的虚拟网卡同 host 上的一 个Docker 网桥 docker0 连接在一起。
- ipc 命名空间: ipc全称interprocess communication,指的是一种进程间的交互方法,包括信号量、消息队列和共享内存等。Docker 默认会为每个容器创建一个独立的 IPC 命名空间,这样容器内的进程就可以在一个隔离的 IPC 环境中运行,不会影响到其他容器或者宿主机的进程。
- mnt 命名空间: mnt 命名空间用于隔离文件系统挂载点,每个容器拥有自己独立的挂载点视图。挂载主要指的是将宿主机的某个目录挂载到自己容器内的某个目录下,通过命名空间的隔离,就可以本本命名空间内记录自己的挂载点,而不会影响到其他容器。
- uts 命名空间: UTS(“UNIX Time-sharing System”) 命名空间允许每个容器拥有独立的 hostname 和 domain name, 使其在网络上可以被视作一个独立的节点,从而避免在网络传输过程中在依靠主机名进行信息传递时出现冲突。
- user 命名空间: 每个容器可以有不同的用户和组 id, 也就是说可以在容器内用容器内部的用户执行程序而非主机上的用户。
控制组(Cgroup)
控制组是linux内核的一个特性,主要用来对共享资源进行隔离、限制,审计等。避免多个容器同时运行时的系统资源竞争,它最早是由 Google 的程序员 2006 年起提出,Linux 内核自 2.6.24 开始支持。
Cgroup 可以限制一个进程组的资源使用,包括 CPU、内存、磁盘IO、网络带宽等。在 Docker 中,Cgroup 主要用来限制容器的相关资源使用。
Cgroups 分 v1 和 v2 两个版本:
- v1 实现较早,功能比较多,但是由于它里面的功能都是零零散散的实现的,所以规划的不是很好,导致了一些使用和维护上的不便。
- v2 的出现就是为了解决 v1 的问题,在最新的 4.5 内核中,Cgroups v2 声称已经可以用于生产环境了,但它所支持的功能还很有限。
Cgroups 主要包括下面几部分:
*** cgroups 本身:** cgroup 是对进程分组管理的一种机制,一个 cgroup 包含一组进程。
- subsystem: 一个 subsystem 就是一个内核模块,可以调度、限制和监控特定资源的使用情况,他被关联到一颗 cgroup 树之后,就会在树的每个节点(进程组)上做具体的操作。到目前为止,Linux 支持 12 种 subsystem,比如限制 CPU 的使用时间,限制使用的内存,统计 CPU 的使用情况,冻结和恢复一组进程等。
- hierarchy: 一个 hierarchy 可以理解为一棵 cgroup 树,树的每个节点就是一个进程组,每棵树都会与零到多个 subsystem 关联,也就是可以对树上的每个节点(进程组)做一些对应的subsystem提供的操作,一个 subsystem 只能附加到 一 个 hierarchy 上面。系统中可以有很多颗 cgroup 树,每棵树都和不同的 subsystem 关联,一个进程可以属于多颗树,即一个进程可以属于多个进程组。当一颗 cgroup 树不和任何 subsystem 关联的时候,意味着这棵树只是将进程进行分组,至于要在分组的基础上做些什么,将由应用程序自己决定,systemd 就是一个这样的例子。
个人理解:
- cgroup 用于对进程进行分组。
- hierarchy 将多个 cgroup 组成一棵树,并提供控制的相关功能,提供了一个控制模板。
- subsystem 则负责资源限制的工作,将 subsystem 和 hierarchy 绑定后,该 hierarchy 上的所有 cgroup 下的进程都会被 subsystem 给限制,但是限制的值可以自定义。
- 子 cgroup 会继承父 cgroup 的 subsystem,但是子 cgroup 之后可以自定义自己的配置。
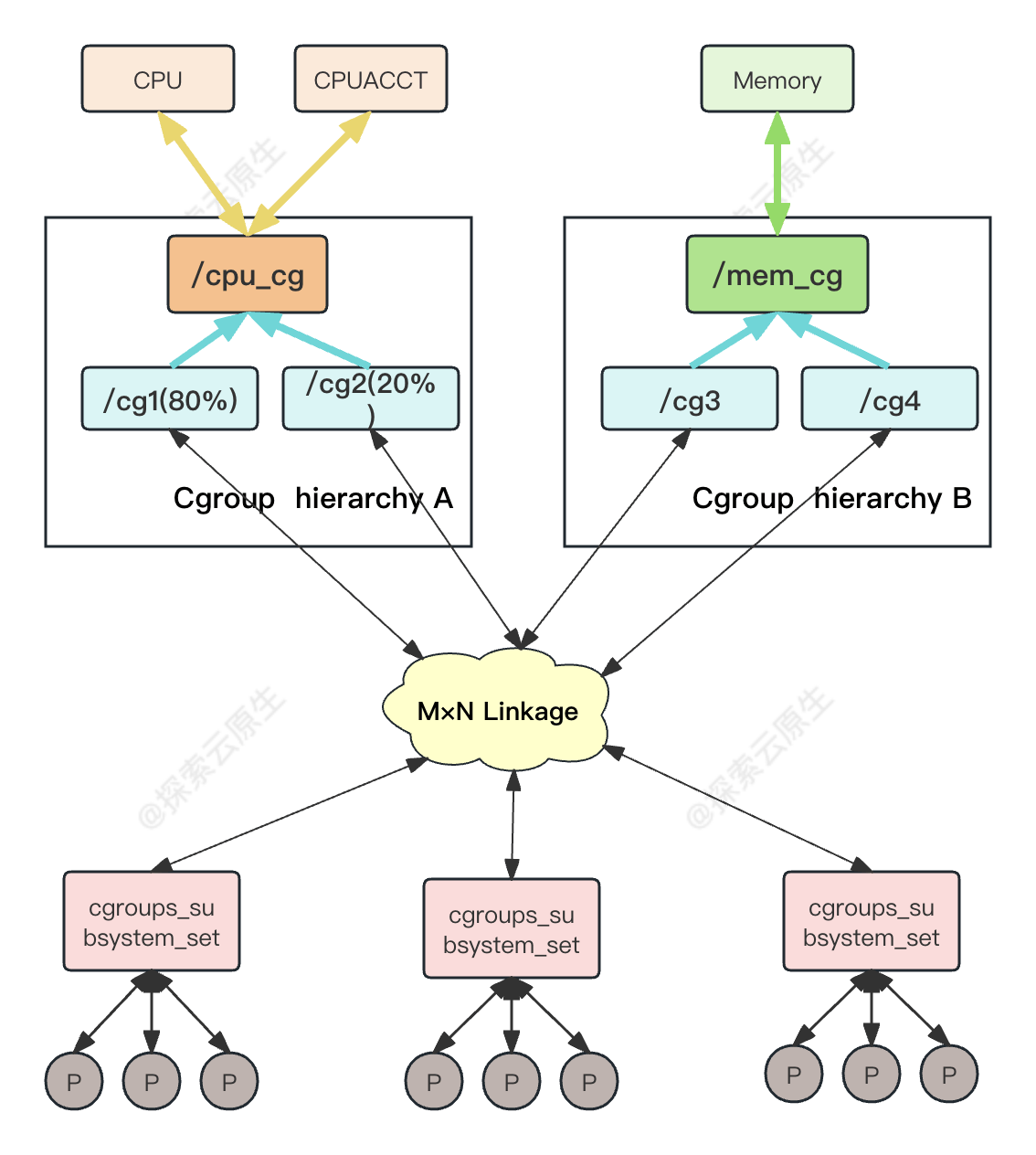
比如上图表示两个 hierarchiy,每一个 hierarchiy 中是一颗树形结构,树的每一个节点是一个 cgroup (比如 cpu_cgrp, memory_cgrp)。
- 第一个 hierarchiy attach 了 cpu 子系统和 cpuacct 子系统, 因此当前 hierarchiy 中的 cgroup 就可以对 cpu 的资源进行限制,并且对进程的 cpu 使用情况进行统计。
- 第二个 hierarchiy attach 了 memory 子系统,因此当前 hierarchiy 中的 cgroup 就可以对 memory 的资源进行限制。
在每一个 hierarchiy 中,每一个节点(cgroup)可以设置对资源不同的限制权重(即自定义配置)。比如上图中 cgrp1 组中的进程可以使用 60%的 cpu 时间片,而 cgrp2 组中的进程可以使用 20%的 cpu 时间片。
Docker 网络
Docker的网络模式主要有以下几种:
| 模式 | 描述 |
|---|---|
| bridge | 为每一个容器分配、设置 IP 等,并将容器连接到一个 docker0 虚拟网桥,默认为该模式。 |
| host | 容器将不会虚拟出自己的网卡,配置自己的 IP 等,而是使用宿主机的 IP 和端口。 |
| none | 容器有独立的 Network namespace,但并没有对其进行任何网络设置,如分配 veth pair 和网桥连接,IP 等。 |
| container | 新创建的容器不会创建自己的网卡和配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。 |
bridge 模式
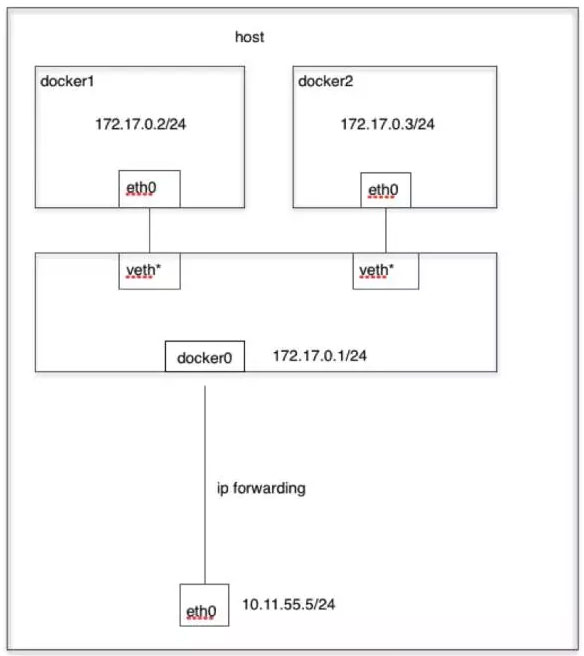
bridge 模式是 Docker 默认的网络模式。在Docker服务启动后,会在主机上创建一个名为 docker0 的虚拟网桥,当我们创建一个bridge网络模式的容器时,首先容器会新建一个网络命名空间,然后它会连接到这个虚拟网桥上。连接的方法是创建一对虚拟网卡veth pair设备,其中一个端口连接到容器内部,命名为eth0,另一个端口连接到docker0上,命名为vethxxx模式的名字。这种虚拟网卡利用内存从来进行数据包的收发,当一端收到数据包后会自动转发给另一端,并对外表现为一个独立的网络设备。同时也会从docker0子网中分配一个 IP 给容器使用,并设置 docker0 的 IP 地址为容器的默认网关。
当容器需要对外通信时,数据包会先被容器内的 veth 网卡接收,然后通过 veth pair 传递给 docker0,再由 docker0 转发给宿主机的物理网卡,然后会对数据包进行Net包装,表现的就像是主机自己发出的数据包一样,最终到达目的地。
如果需要同一个主机下的容器之间通信,那么需要设置–link参数来允许容器之间的通信,注意默认情况下,容器之间是无法通信的。而随着Docker 1.9版本的发布,Docker官方推荐使用用户自定义的网络来代替–link参数。
这种模式下的一个大缺点就在于容器都没有一个公有IP,即和宿主机不处于同一个网段。导致的结果是宿主机以外的世界不能直接和容器进行通信。
host 模式
host模式相当于Vmware中的NAT模式,与宿主机在同一个网络中,但没有独立IP地址。启动容器使用host模式,容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。
使用host模式的容器可以直接使用宿主机的IP地址与外界通信,容器内部的服务端口也可以使用宿主机的端口,不需要进行NAT,host最大的优势就是网络性能比较好,docker host上已经使用的端口就不能再用了,网络的隔离性不好。

none 模式
使用none模式,Docker 容器拥有自己的 Network Namespace,但是,并不为Docker 容器进行任何网络配置。也就是说,这个 Docker 容器没有网卡、IP、路由等信息。需要我们自己为 Docker 容器添加网卡、配置 IP 等。 None模式示意图:

container 模式
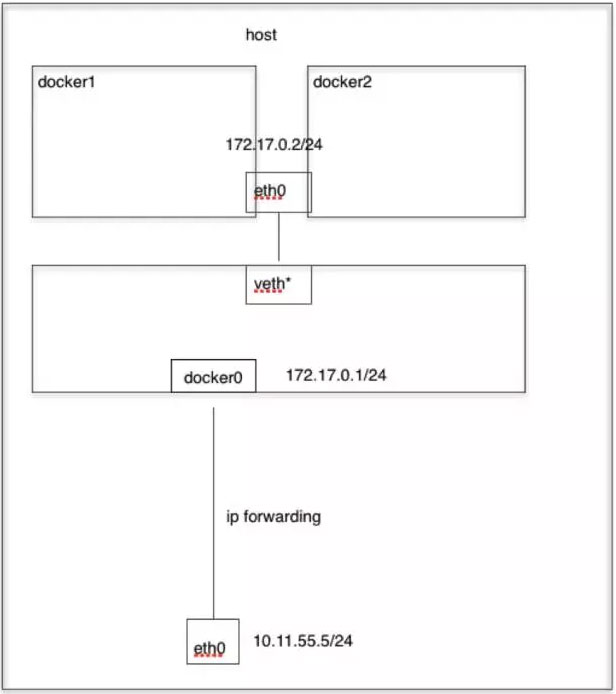
这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备进行高效通信。 Container模式示意图:
Docker 存储
根据前面的UnionFS的介绍我们可知,在默认情况下在Docker容器内创建和修改的所有文件都在可写层,只能在容器内部使用,难以被其他服务共享。且容器删除后,数据也跟着删除。同时写入容器的可写层需要Docker存储驱动管理文件系统。存储驱动使用Linux内核提供的联合文件系统,其性能不如直接写入主机文件系统的Docker卷。所以docker也提供了一些存储持久化的功能,主要可以分为:volume、bind mount和tmpfs。
Volume
Volumes 是Docker推荐的挂载方式,它在主机中创建一个数据卷,并对应到容器中的一个目录。与把数据存储在容器的可写层相比,使用Volume可以避免增加容器的容量大小,还可以使存储的数据与容器的生命周期独立。Volumes存储在主机文件系统中由Docker管理的位置,在Linux主机上该位置默认就是/var/lib/docker/volumes目录,其他非docker进程不能修改该路径下的文件,完全由docker引擎来管理。Volumes支持使用Volumes驱动,可以让用户将数据存储在远程主机或云提供商处等。可以以命名方式或匿名方式挂载卷:
- 匿名卷(Anonymous Volumes):首次挂载容器未指定名称,Docker为其随机指定一个唯一名称。
- 命名卷(Named Volumes):指定明确名称,和匿名卷其他特性相同。
卷由Docker创建并管理,卷适合以下应用场景。
- 在多个正在运行的容器之间共享数据。(数据共享)
- 当Docker主机不能保证具有特定目录结构时,卷有助于将Docker主机的配置与容器运行时解耦。(构建新目录与主机不同)
- 当需要将容器的数据存储到远程主机或云提供商处,而不是本地时。(可以远程挂载卷,公有云、灾备等场景)
- 当需要在两个Docker主机之间备份、恢复或迁移数据时。(主机间备份迁移)
Bind mount
Bind mount 模式下可以存储在宿主机器任何一个地方,但是会依赖宿主机器的目录结构,不能通过docker CLI 去直接管理,并且非docker进程和docker进程都可以修改该路径下的文件。
它的特点:
- 主机上进程或容器可以随时修改。
- 相比Volumes,功能更受限、性能更高。
- 绑定挂载运行访问敏感文件。
绑定挂载适合以下应用场景。
- 在主机和容器之间共享配置文件。
- 在Docker主机上的开发环境和容器之间共享源代码或构建工件。
- 当Docker主机上的目录结构保证与容器要求的绑定挂载一致时。
tmpfs
tmpfs挂载仅限于运行Linux操作系统的Docker主机使用,它只存储在主机的内存中,不会被写到主机的文件系统中,因此不能持久保存容器的应用数据。
在不需要将数据持久保存到主机或容器中时,tmpfs挂载最合适。
如果容器产生了非持久化数据,那么可以考虑使用tmpfs挂载避免将数据永久存储到任何位置,并且通过避免写入容器的可写层来提高容器的性能。