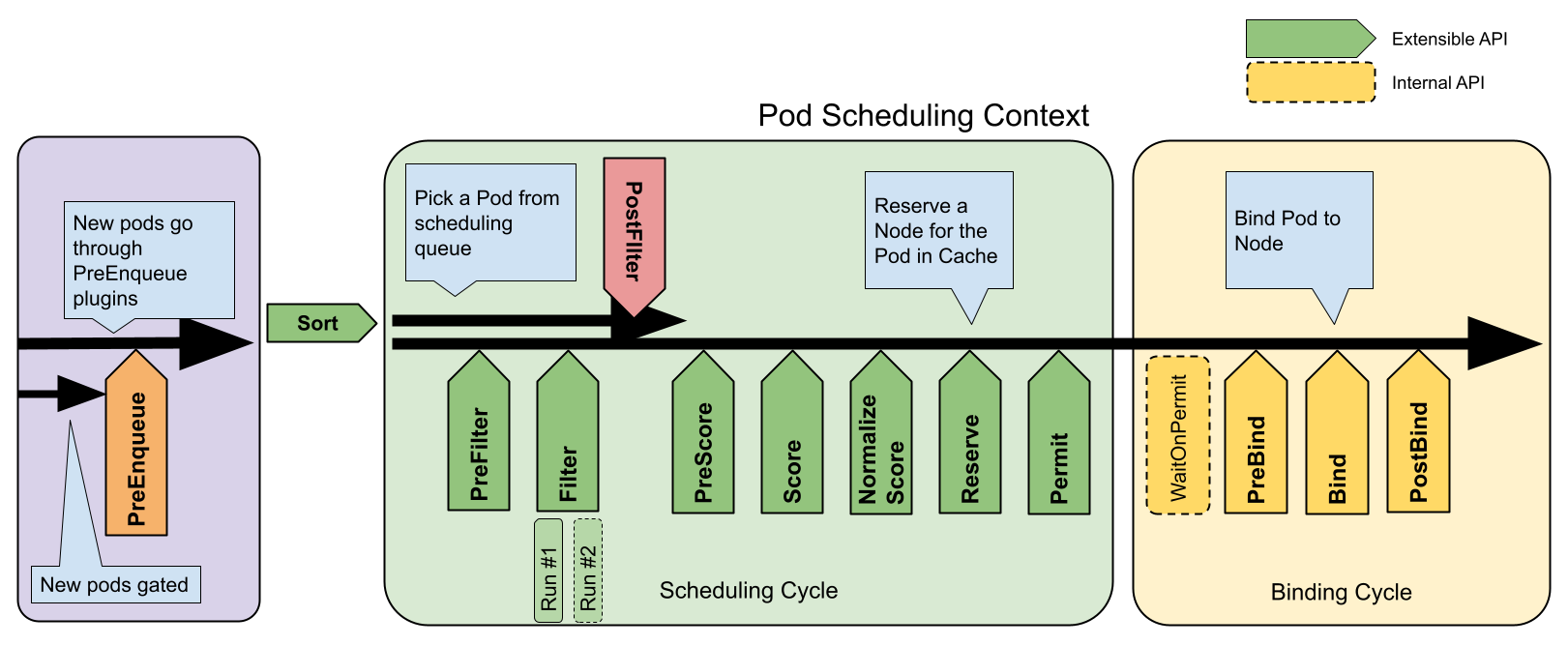
// scheduleOne does the entire scheduling workflow for a single pod. It is serialized on the scheduling algorithm's host fitting. func(sched *Scheduler) scheduleOne(ctx context.Context) { // 获取调度队列中的下一个 Pod 信息 podInfo := sched.NextPod() // 如果 podInfo 或者其包含的 Pod 为 nil,说明调度队列关闭或者没有 Pod 需要调度,直接返回 if podInfo == nil || podInfo.Pod == nil { return } // 获取 Pod 对象 pod := podInfo.Pod // 为当前 Pod 选择一个调度框架(scheduler framework) fwk, err := sched.frameworkForPod(pod) if err != nil { // 这种情况不应该发生,因为我们只接受那些指定了匹配调度器名称的 Pod 进行调度 klog.ErrorS(err, "Error occurred") return } // 如果跳过调度,则直接返回 if sched.skipPodSchedule(fwk, pod) { return }
// 记录尝试调度 Pod 的日志 klog.V(3).InfoS("Attempting to schedule pod", "pod", klog.KObj(pod))
// 开始计时,尝试为 Pod 找到合适的宿主机 start := time.Now() // 初始化调度周期状态 state := framework.NewCycleState() // 设置是否记录插件指标的随机概率 state.SetRecordPluginMetrics(rand.Intn(100) < pluginMetricsSamplePercent)
// schedulingCycle tries to schedule a single Pod. func(sched *Scheduler) schedulingCycle( ctx context.Context, // 调度上下文 state *framework.CycleState, // 调度周期状态 fwk framework.Framework, // 调度框架 podInfo *framework.QueuedPodInfo, // 待调度的 Pod 信息 start time.Time, // 调度开始时间 podsToActivate *framework.PodsToActivate, // 待激活的 Pods ) (ScheduleResult, *framework.QueuedPodInfo, *framework.Status) { // 获取待调度的 Pod pod := podInfo.Pod // 调用调度器的 SchedulePod 方法尝试调度 Pod scheduleResult, err := sched.SchedulePod(ctx, fwk, state, pod) if err != nil { // 如果没有可用节点,则返回错误状态 if err == ErrNoNodesAvailable { status := framework.NewStatus(framework.UnschedulableAndUnresolvable).WithError(err) return ScheduleResult{nominatingInfo: clearNominatedNode}, podInfo, status }
// 如果错误是 FitError 类型,则说明 Pod 无法适应任何节点 fitError, ok := err.(*framework.FitError) if !ok { klog.ErrorS(err, "Error selecting node for pod", "pod", klog.KObj(pod)) return ScheduleResult{nominatingInfo: clearNominatedNode}, podInfo, framework.AsStatus(err) }
// 如果没有 PostFilter 插件,则不执行抢占 if !fwk.HasPostFilterPlugins() { klog.V(3).InfoS("No PostFilter plugins are registered, so no preemption will be performed") return ScheduleResult{}, podInfo, framework.NewStatus(framework.Unschedulable).WithError(err) }
// 运行 PostFilter 插件,尝试使 Pod 在未来的调度周期中可调度 result, status := fwk.RunPostFilterPlugins(ctx, state, pod, fitError.Diagnosis.NodeToStatusMap) msg := status.Message() fitError.Diagnosis.PostFilterMsg = msg if status.Code() == framework.Error { klog.ErrorS(nil, "Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", msg) } else { klog.V(5).InfoS("Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", msg) }
// 获取 PostFilter 插件返回的 NominatingInfo var nominatingInfo *framework.NominatingInfo if result != nil { nominatingInfo = result.NominatingInfo } return ScheduleResult{nominatingInfo: nominatingInfo}, podInfo, framework.NewStatus(framework.Unschedulable).WithError(err) }
// 计算并记录调度算法的延迟 metrics.SchedulingAlgorithmLatency.Observe(metrics.SinceInSeconds(start)) // 假设 Pod 已经在给定节点上运行,这样子就不用等它实际绑定就可以执行后续的操作了 assumedPodInfo := podInfo.DeepCopy() assumedPod := assumedPodInfo.Pod // 假设操作,设置 Pod 的 NodeName 为调度结果推荐的宿主机 err = sched.assume(assumedPod, scheduleResult.SuggestedHost) if err != nil { // 如果假设操作失败,这可能是重试逻辑中的一个 BUG // 报告错误以便重新调度 Pod return ScheduleResult{nominatingInfo: clearNominatedNode}, assumedPodInfo, framework.AsStatus(err) }
// schedulePod tries to schedule the given pod to one of the nodes in the node list. // If it succeeds, it will return the name of the node. // If it fails, it will return a FitError with reasons. func(sched *Scheduler) schedulePod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) { trace := utiltrace.New("Scheduling", utiltrace.Field{Key: "namespace", Value: pod.Namespace}, utiltrace.Field{Key: "name", Value: pod.Name}) defer trace.LogIfLong(100 * time.Millisecond)
if err := sched.Cache.UpdateSnapshot(sched.nodeInfoSnapshot); err != nil { return result, err } trace.Step("Snapshotting scheduler cache and node infos done")
if sched.nodeInfoSnapshot.NumNodes() == 0 { return result, ErrNoNodesAvailable }
// When only one node after predicate, just use it. iflen(feasibleNodes) == 1 { return ScheduleResult{ SuggestedHost: feasibleNodes[0].Name, EvaluatedNodes: 1 + len(diagnosis.NodeToStatusMap), FeasibleNodes: 1, }, nil }
// Filters the nodes to find the ones that fit the pod based on the framework // filter plugins and filter extenders. func(sched *Scheduler) findNodesThatFitPod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) ([]*v1.Node, framework.Diagnosis, error) { // 初始化诊断信息,用于记录调度过程中的详细信息 diagnosis := framework.Diagnosis{ NodeToStatusMap: make(framework.NodeToStatusMap), UnschedulablePlugins: sets.NewString(), }
// 获取所有节点的信息 allNodes, err := sched.nodeInfoSnapshot.NodeInfos().List() if err != nil { returnnil, diagnosis, err } // 运行 "prefilter" 插件 preRes, s := fwk.RunPreFilterPlugins(ctx, state, pod) if !s.IsSuccess() { if !s.IsUnschedulable() { returnnil, diagnosis, s.AsError() } // 如果 PreFilter 插件返回的状态是不可调度的,记录相关信息 msg := s.Message() diagnosis.PreFilterMsg = msg klog.V(5).InfoS("Status after running PreFilter plugins for pod", "pod", klog.KObj(pod), "status", msg) // 如果有插件失败,记录失败的插件名称 if s.FailedPlugin() != "" { diagnosis.UnschedulablePlugins.Insert(s.FailedPlugin()) } returnnil, diagnosis, nil }
// numFeasibleNodesToFind returns the number of feasible nodes that once found, the scheduler stops // its search for more feasible nodes. func(sched *Scheduler) numFeasibleNodesToFind(percentageOfNodesToScore *int32, numAllNodes int32) (numNodes int32) { if numAllNodes < minFeasibleNodesToFind { // 如果所有节点的数量小于预设的最小可行节点数,则返回所有节点的数量 return numAllNodes }
// 使用框架(profile)中设置的百分比,如果没有设置,则使用全局的百分比 var percentage int32 if percentageOfNodesToScore != nil { percentage = *percentageOfNodesToScore } else { percentage = sched.percentageOfNodesToScore }
// Until is a wrapper around workqueue.ParallelizeUntil to use in scheduling algorithms. // A given operation will be a label that is recorded in the goroutine metric. func(p Parallelizer) Until(ctx context.Context, pieces int, doWorkPiece workqueue.DoWorkPieceFunc, operation string) { goroutinesMetric := metrics.Goroutines.WithLabelValues(operation) withMetrics := func(piece int) { goroutinesMetric.Inc() doWorkPiece(piece) goroutinesMetric.Dec() }
workqueue.ParallelizeUntil(ctx, p.parallelism, pieces, withMetrics, workqueue.WithChunkSize(chunkSizeFor(pieces, p.parallelism))) } // ParallelizeUntil is a framework that allows for parallelizing N // independent pieces of work until done or the context is canceled. funcParallelizeUntil(ctx context.Context, workers, pieces int, doWorkPiece DoWorkPieceFunc, opts ...Options) { if pieces == 0 { return } o := options{} for _, opt := range opts { opt(&o) } chunkSize := o.chunkSize if chunkSize < 1 { chunkSize = 1 }
chunks := ceilDiv(pieces, chunkSize) toProcess := make(chanint, chunks) for i := 0; i < chunks; i++ { toProcess <- i } close(toProcess)
var stop <-chanstruct{} if ctx != nil { stop = ctx.Done() } if chunks < workers { workers = chunks } wg := sync.WaitGroup{} wg.Add(workers) for i := 0; i < workers; i++ { gofunc() { defer utilruntime.HandleCrash() defer wg.Done() for chunk := range toProcess { start := chunk * chunkSize end := start + chunkSize if end > pieces { end = pieces } for p := start; p < end; p++ { select { case <-stop: return default: doWorkPiece(p) } } } }() } wg.Wait() }
func(f *frameworkImpl) RunFilterPluginsWithNominatedPods( ctx context.Context, // 调度上下文 state *framework.CycleState, // 当前周期状态 pod *v1.Pod, // 待调度的 Pod info *framework.NodeInfo, // 节点信息 ) *framework.Status { var status *framework.Status
podsAdded := false // We run filters twice in some cases. If the node has greater or equal priority // nominated pods, we run them when those pods are added to PreFilter state and nodeInfo. // If all filters succeed in this pass, we run them again when these // nominated pods are not added. This second pass is necessary because some // filters such as inter-pod affinity may not pass without the nominated pods. // If there are no nominated pods for the node or if the first run of the // filters fail, we don't run the second pass. // We consider only equal or higher priority pods in the first pass, because // those are the current "pod" must yield to them and not take a space opened // for running them. It is ok if the current "pod" take resources freed for // lower priority pods. // Requiring that the new pod is schedulable in both circumstances ensures that // we are making a conservative decision: filters like resources and inter-pod // anti-affinity are more likely to fail when the nominated pods are treated // as running, while filters like pod affinity are more likely to fail when // the nominated pods are treated as not running. We can't just assume the // nominated pods are running because they are not running right now and in fact, // they may end up getting scheduled to a different node. // 我们可能需要两次运行过滤插件。如果节点上有优先级更高或相等的被提名的 Pods, // 我们会在这些 Pods 被添加到 PreFilter 状态和 nodeInfo 时运行它们。 // 如果所有过滤插件在这一轮通过,我们会在这些被提名的 Pods 没有被添加的情况下再次运行它们。 // 第二轮运行是必要的,因为一些过滤插件(如 Pod 亲和性)可能在没有被提名的 Pods 的情况下无法通过。 // 如果节点没有被提名的 Pods 或者第一轮过滤插件失败,我们不会进行第二轮。 // 我们只考虑第一轮中优先级相等或更高的 Pods,因为当前的 "pod" 必须为它们让路,而不是占用为它们运行而开放的空间。 // 如果当前的 "pod" 占用了为低优先级 Pods 释放的资源,这是可以的。 // 要求新的 Pod 在这两种情况下都是可调度的,确保我们做出的是保守的决定: // 像资源和 Pod 反亲和性这样的过滤器在将被提名的 Pods 视为运行时更有可能失败, // 而像 Pod 亲和性这样的过滤器在将被提名的 Pods 视为未运行时更有可能失败。 // 我们不能仅仅假设被提名的 Pods 正在运行,因为它们现在并没有运行,事实上, // 它们最终可能会被调度到一个不同的节点上。 for i := 0; i < 2; i++ { stateToUse := state nodeInfoToUse := info if i == 0 { // 第一轮:添加被提名的 Pods 到周期状态和节点信息 var err error podsAdded, stateToUse, nodeInfoToUse, err = addNominatedPods(ctx, f, pod, state, info) if err != nil { return framework.AsStatus(err) } } elseif !podsAdded || !status.IsSuccess() { break }
// 运行过滤插件 status = f.RunFilterPlugins(ctx, stateToUse, pod, nodeInfoToUse) if !status.IsSuccess() && !status.IsUnschedulable() { return status } }
// RunFilterPlugins runs the set of configured Filter plugins for pod on // the given node. If any of these plugins doesn't return "Success", the // given node is not suitable for running pod. // Meanwhile, the failure message and status are set for the given node. func(f *frameworkImpl) RunFilterPlugins( ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo, ) *framework.Status { for _, pl := range f.filterPlugins { if state.SkipFilterPlugins.Has(pl.Name()) { continue } metrics.PluginEvaluationTotal.WithLabelValues(pl.Name(), metrics.Filter, f.profileName).Inc() if status := f.runFilterPlugin(ctx, pl, state, pod, nodeInfo); !status.IsSuccess() { if !status.IsUnschedulable() { // Filter plugins are not supposed to return any status other than // Success or Unschedulable. status = framework.AsStatus(fmt.Errorf("running %q filter plugin: %w", pl.Name(), status.AsError())) } status.SetFailedPlugin(pl.Name()) return status } }
// 如果启用了详细日志记录,记录每个插件对每个节点的打分 klogV := klog.V(10) if klogV.Enabled() { for _, nodeScore := range nodesScores { for _, pluginScore := range nodeScore.Scores { klogV.InfoS("Plugin scored node for pod", "pod", klog.KObj(pod), "plugin", pluginScore.Name, "node", nodeScore.Name, "score", pluginScore.Score) } } }
// 如果有扩展器并且有节点,运行扩展器 iflen(extenders) != 0 && nodes != nil { allNodeExtendersScores := make(map[string]*framework.NodePluginScores, len(nodes)) var mu sync.Mutex var wg sync.WaitGroup // 并发运行每个扩展器的优先级函数 for i := range extenders { if !extenders[i].IsInterested(pod) { continue } wg.Add(1) gofunc(extIndex int) { defer wg.Done() metrics.SchedulerGoroutines.WithLabelValues(metrics.PrioritizingExtender).Inc() metrics.Goroutines.WithLabelValues(metrics.PrioritizingExtender).Inc() deferfunc() { metrics.SchedulerGoroutines.WithLabelValues(metrics.PrioritizingExtender).Dec() metrics.Goroutines.WithLabelValues(metrics.PrioritizingExtender).Dec() }() prioritizedList, weight, err := extenders[extIndex].Prioritize(pod, nodes) if err != nil { klog.V(5).InfoS("Failed to run extender's priority function. No score given by this extender.", "error", err, "pod", klog.KObj(pod), "extender", extenders[extIndex].Name()) return } mu.Lock() defer mu.Unlock() for i := range *prioritizedList { nodename := (*prioritizedList)[i].Host score := (*prioritizedList)[i].Score klogV.InfoS("Extender scored node for pod", "pod", klog.KObj(pod), "extender", extenders[extIndex].Name(), "node", nodename, "score", score) // 将扩展器的分数转换为调度器使用的分数范围 finalscore := score * weight * (framework.MaxNodeScore / extenderv1.MaxExtenderPriority) if allNodeExtendersScores[nodename] == nil { allNodeExtendersScores[nodename] = &framework.NodePluginScores{ Name: nodename, Scores: make([]framework.PluginScore, 0, len(extenders)), } } allNodeExtendersScores[nodename].Scores = append(allNodeExtendersScores[nodename].Scores, framework.PluginScore{ Name: extenders[extIndex].Name(), Score: finalscore, }) allNodeExtendersScores[nodename].TotalScore += finalscore } }(i) } wg.Wait() // 等待所有扩展器完成 // 将扩展器的分数添加到节点分数中 for i := range nodesScores { if score, ok := allNodeExtendersScores[nodes[i].Name]; ok { nodesScores[i].Scores = append(nodesScores[i].Scores, score.Scores...) nodesScores[i].TotalScore += score.TotalScore } } }
// 记录每个节点的最终分数 if klogV.Enabled() { for i := range nodesScores { klogV.InfoS("Calculated node's final score for pod", "pod", klog.KObj(pod), "node", nodesScores[i].Name, "score", nodesScores[i].TotalScore) } } return nodesScores, nil }
// NodePluginScores is a struct with node name and scores for that node. type NodePluginScores struct { // Name is node name. Name string // Scores is scores from plugins and extenders. Scores []PluginScore // TotalScore is the total score in Scores. TotalScore int64 }
// PluginScore is a struct with plugin/extender name and score. type PluginScore struct { // Name is the name of plugin or extender. Name string Score int64 }
// RunPostFilterPlugins runs the set of configured PostFilter plugins until the first // Success, Error or UnschedulableAndUnresolvable is met; otherwise continues to execute all plugins. func(f *frameworkImpl) RunPostFilterPlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, filteredNodeStatusMap framework.NodeToStatusMap) (_ *framework.PostFilterResult, status *framework.Status) { startTime := time.Now() deferfunc() { metrics.FrameworkExtensionPointDuration.WithLabelValues(metrics.PostFilter, status.Code().String(), f.profileName).Observe(metrics.SinceInSeconds(startTime)) }()
// `result` records the last meaningful(non-noop) PostFilterResult. var result *framework.PostFilterResult var reasons []string var failedPlugin string for _, pl := range f.postFilterPlugins { r, s := f.runPostFilterPlugin(ctx, pl, state, pod, filteredNodeStatusMap) if s.IsSuccess() { return r, s } elseif s.Code() == framework.UnschedulableAndUnresolvable { return r, s.WithFailedPlugin(pl.Name()) } elseif !s.IsUnschedulable() { // Any status other than Success, Unschedulable or UnschedulableAndUnresolvable is Error. returnnil, framework.AsStatus(s.AsError()).WithFailedPlugin(pl.Name()) } elseif r != nil && r.Mode() != framework.ModeNoop { result = r }
reasons = append(reasons, s.Reasons()...) // Record the first failed plugin unless we proved that // the latter is more relevant. iflen(failedPlugin) == 0 { failedPlugin = pl.Name() } }
// RunReservePluginsReserve runs the Reserve method in the set of configured // reserve plugins. If any of these plugins returns an error, it does not // continue running the remaining ones and returns the error. In such a case, // the pod will not be scheduled and the caller will be expected to call // RunReservePluginsUnreserve. func(f *frameworkImpl) RunReservePluginsReserve(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (status *framework.Status) { startTime := time.Now() deferfunc() { metrics.FrameworkExtensionPointDuration.WithLabelValues(metrics.Reserve, status.Code().String(), f.profileName).Observe(metrics.SinceInSeconds(startTime)) }() for _, pl := range f.reservePlugins { status = f.runReservePluginReserve(ctx, pl, state, pod, nodeName) if !status.IsSuccess() { err := status.AsError() klog.ErrorS(err, "Failed running Reserve plugin", "plugin", pl.Name(), "pod", klog.KObj(pod)) return framework.AsStatus(fmt.Errorf("running Reserve plugin %q: %w", pl.Name(), err)) } } returnnil }
// RunPermitPlugins runs the set of configured permit plugins. If any of these // plugins returns a status other than "Success" or "Wait", it does not continue // running the remaining plugins and returns an error. Otherwise, if any of the // plugins returns "Wait", then this function will create and add waiting pod // to a map of currently waiting pods and return status with "Wait" code. // Pod will remain waiting pod for the minimum duration returned by the permit plugins. func(f *frameworkImpl) RunPermitPlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (status *framework.Status) { startTime := time.Now() // 记录permit插件开始运行的时间 deferfunc() { // 记录permit插件的运行时间和最终状态 metrics.FrameworkExtensionPointDuration.WithLabelValues(metrics.Permit, status.Code().String(), f.profileName).Observe(metrics.SinceInSeconds(startTime)) }() pluginsWaitTime := make(map[string]time.Duration) // 存储每个插件的等待时间 statusCode := framework.Success // 初始化状态码为成功 for _, pl := range f.permitPlugins { // 运行当前permit插件 status, timeout := f.runPermitPlugin(ctx, pl, state, pod, nodeName) if !status.IsSuccess() { if status.IsUnschedulable() { // 如果插件返回不可调度的状态,则记录日志并返回该状态 klog.V(4).InfoS("Pod rejected by permit plugin", "pod", klog.KObj(pod), "plugin", pl.Name(), "status", status.Message()) status.SetFailedPlugin(pl.Name()) // 设置失败的插件名称 return status } if status.IsWait() { // 如果插件返回等待的状态,则记录等待时间,但不立即返回 // 允许的最长等待时间由 maxTimeout 限制 if timeout > maxTimeout { timeout = maxTimeout } pluginsWaitTime[pl.Name()] = timeout statusCode = framework.Wait // 更新状态码为等待 } else { // 如果插件返回错误状态,则记录错误日志并返回错误状态 err := status.AsError() klog.ErrorS(err, "Failed running Permit plugin", "plugin", pl.Name(), "pod", klog.KObj(pod)) return framework.AsStatus(fmt.Errorf("running Permit plugin %q: %w", pl.Name(), err)).WithFailedPlugin(pl.Name()) } } } if statusCode == framework.Wait { // 如果任何插件返回等待状态,则创建并添加等待中的 Pod 到映射中,并返回等待状态 waitingPod := newWaitingPod(pod, pluginsWaitTime) f.waitingPods.add(waitingPod) msg := fmt.Sprintf("one or more plugins asked to wait and no plugin rejected pod %q", pod.Name) klog.V(4).InfoS("One or more plugins asked to wait and no plugin rejected pod", "pod", klog.KObj(pod)) return framework.NewStatus(framework.Wait, msg) } // 如果所有插件都成功或返回等待,且没有插件拒绝 Pod,则返回 nil 表示没有错误 returnnil }