【K8s源码分析(六)】-K8s中Pod拓扑分布约束(Pod Topology Spread Constraints)插件介绍
本次分析参考的K8s版本是v1.27.0。
前言
在 k8s 集群调度中,亲和性相关的概念本质上都是控制 Pod 如何被调度 – 堆叠或打散。podAffinity 以及 podAntiAffinity 两个特性对 Pod 在不同拓扑域(拓扑键-拓扑值构成了一个拓扑域,例如region-east)的分布进行了一些控制,podAffinity 可以将无数个 Pod 调度到特定的某一个拓扑域,这是堆叠的体现;podAntiAffinity 则可以控制一个拓扑域只存在一个 Pod,这是打散的体现。前面已经进行了介绍,详见:K8s源码分析(五)-K8s中Pod亲和性调度插件介绍
但podAffinity 以及 podAntiAffinity 这两种情况都太极端了,在不少场景下都无法达到理想的效果,例如为了实现容灾和高可用,将业务 Pod 尽可能均匀的分布在不同可用区就很难实现。
PodTopologySpread(Pod 拓扑分布约束) 特性的提出正是为了对 Pod 的调度分布提供更精细的控制,以提高服务可用性以及资源利用率,PodTopologySpread 由 EvenPodsSpread 特性门所控制,在 v1.16 版本第一次发布,并在 v1.18 版本进入 beta 阶段默认启用。
官方对其的介绍详见:Pod Topology Spread Constraints
使用规范
这一特性的定义在spec.topologySpreadConstraints下,一些可以定义的字段如下
1 | |
topologyKey:这个拓扑约束所生效的目标拓扑键,计算分布不均匀程度时以其作为单位。例如region、zone、hostName等。
maxSkew:描述了允许的最大pod的分布不均匀程度。不均匀程度由同一个拓扑键下各个拓扑值中包含的所有的node中匹配的pod的数量之和的最大值减去最小值得到。
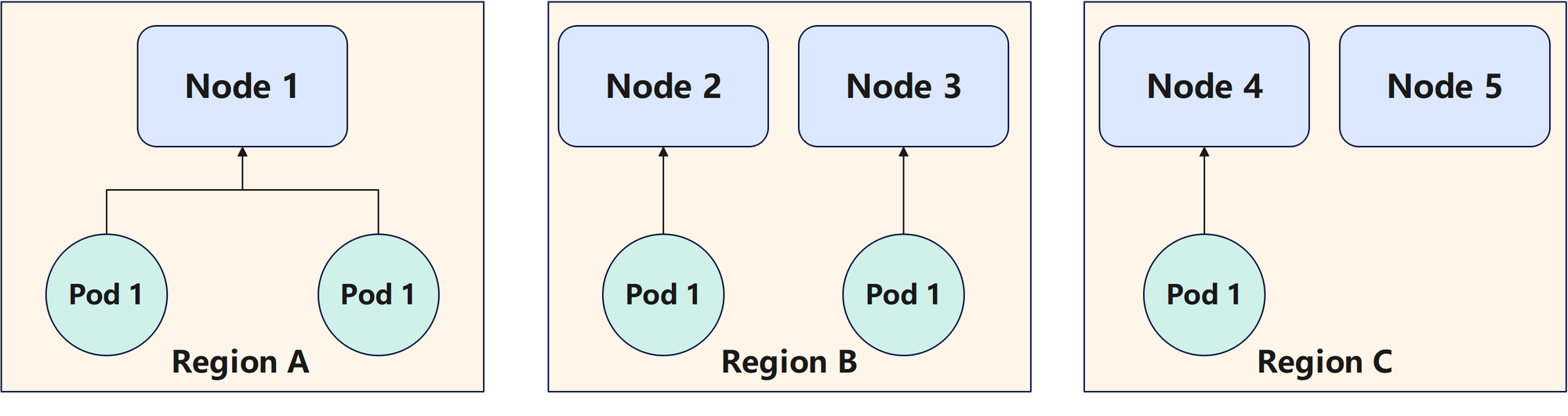
例如现在的拓扑键是region,总共有3个不同的拓扑值,分别为A、B、C,就是有3个拓扑域它们中分别有2、2、1个相匹配的pod,那么其不均匀程度就是2-1=1。如过设置maxSkew为1,那么要维持这个maxSkew,pod就得调度到Region C中的任意一个node上去。
whenUnsatisfiable:当不满足maxSkew约束的node时如何处理。值可以为:
DoNotSchedule(默认)告诉调度器不要调度。ScheduleAnyway告诉调度器仍然继续调度,只是根据如何能将偏差最小化来对节点进行排序。
labelSelector:筛选需要匹配的pod的规则。
minDomains(可选项):符合条件的拓扑域的最小值。如果小于这个值,那么就设置全局中匹配到的pod的数量的最小值为0,这时候各个拓扑域下的node相匹配的pod数量需要小于等于maxSkew。如果拓扑域的数量大于这个值,那么就不会有影响。默认值为1,设置的值必须大于0。
注意:在 Kubernetes v1.30 之前,
minDomains字段只有在启用了MinDomainsInPodTopologySpread特性门控时才可用(自 v1.28 起默认启用) 在早期的 Kubernetes 集群中,此特性门控可能被显式禁用或此字段可能不可用。matchLabelKeys(可选项,beta,v1.27启用):在labelSelector之外进行额外的pod筛选,即labelSelector筛选后的pod必须还得包含这些key。注意其要求如果没有labelSelector就不能使用这个项,并且不能和labelSelector有相同的key。默认是空,即不可能该项。
nodeAffinityPolicy(可选项,beta,v1.26启用):定义如何对待nodeAffinity和nodeSelector。
- Honor:只有匹配nodeAffinity/nodeSelector的节点才会包含在计算中。
- Ignore:nodeAffinity/nodeSelector 操作被忽略,所有节点都包含在计算中。
nodeTaintsPolicy (可选项,beta,v1.26启用):定义如何处理污点节点。
- Honor:只查看没有污点的节点,以及要调度的pod 具有容忍度的污点的节点。
- Ignore:所有节点都包含在计算中。
当一个 Pod 定义多个topologySpreadConstraint时,这些约束将使用逻辑 AND 运算进行组合。因为可以有多个约束,所以有可能会出现调度到任意节点都无法满足的情况。
源代码分析
该组件的相关代码都在pkg/scheduler/framework/plugins/podtopologyspread文件夹下,其包含的文件如下:
1 | |
plugin.go
查看其初始的部分,如下。
1 | |
可以看到与上一次分析的亲和性调度插件类似,也是定义并实现了以下接口。
- PreFilter
- Filter
- PreScore
- Score
- EnqueueExtensions
结构体中还有一些特别的额外变量,其含义如下:
- systemDefaulted:是否使用了系统默认的拓扑约束
- parallelizer:一个并行处理工具
- defaultConstraints:默认的拓扑约束
- sharedLister:一个共享的列表器,它提供了对 Kubernetes 资源(如节点、Pods 等)的访问
- services:一个服务列表器,用于列出 Kubernetes 中的服务资源。
- replicationCtrls:一个副本控制器列表器,用于列出和访问 Kubernetes 中的副本控制器对象。
- replicaSets:一个副本集列表器,用于列出和访问 Kubernetes 中的副本集对象。
- statefulSets:一个有状态集列表器,用于列出和访问 Kubernetes 中的有状态集对象。
- enableMinDomainsInPodTopologySpread:控制是否启用 Pod 拓扑分布的最小域
minDomains特性。 - enableNodeInclusionPolicyInPodTopologySpread:控制是否启用了节点包含策略特性,如果没有启用,那么就只考虑通过节点亲和性及node selector的node。但是如果启用了,就会根据各个拓扑约束的nodeAffinityPolicy和nodeTaintsPolicy 来考虑是否检查节点能否通过亲和性约束及node selector和节点污点特性。
- enableMatchLabelKeysInPodTopologySpread:控制是否启用在 Pod 拓扑分布中的
matchLabelKeys特性。
再查看其注册的事件,可以看到当pod有任何修改或者node有添加、删除、更新label的操作时,就会将调度失败的pod进行重新调度。
1 | |
再看其初始化的构建函数New,如下
1 | |
filtering.go
PreFilter
首先查看其PreFilter函数,如下
1 | |
再查看核心的calPreFilterState函数,如下,补充了部分注释。
1 | |
可以看到该函数的主要作用还是统计各个拓扑域上符合条件的pod的数量。其流程如下:
获取所有的节点信息
查看pod是否有自定义的拓扑分布约束,如果没有就构建一个默认的约束。
构建默认约束的函数
buildDefaultConstraints如下,注意其输入为要调度的pod和noSchedule级别。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// buildDefaultConstraints builds the constraints for a pod using
// .DefaultConstraints and the selectors from the services, replication
// controllers, replica sets and stateful sets that match the pod.
func (pl *PodTopologySpread) buildDefaultConstraints(p *v1.Pod, action v1.UnsatisfiableConstraintAction) ([]topologySpreadConstraint, error) {
constraints, err := pl.filterTopologySpreadConstraints(pl.defaultConstraints, p.Labels, action)
if err != nil || len(constraints) == 0 {
return nil, err
}
selector := helper.DefaultSelector(p, pl.services, pl.replicationCtrls, pl.replicaSets, pl.statefulSets)
if selector.Empty() {
return nil, nil
}
for i := range constraints {
constraints[i].Selector = selector
}
return constraints, nil
}其中主要的函数是
filterTopologySpreadConstraints函数,其传入的是pl.defaultConstraints,如下,补充了部分注释。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61// filterTopologySpreadConstraints 从 Pod 的拓扑分布约束中筛选出满足 whenUnsatisfiable 为指定 action 的约束。
func (pl *PodTopologySpread) filterTopologySpreadConstraints(
constraints []v1.TopologySpreadConstraint, // Kubernetes v1 版本的拓扑分布约束列表。
podLabels map[string]string, // Pod 的标签。
action v1.UnsatisfiableConstraintAction, // 当约束不可满足时的动作。
) ([]topologySpreadConstraint, error) { // 返回筛选后的拓扑分布约束列表和错误(如果有的话)。
var result []topologySpreadConstraint // 初始化一个用于存放筛选结果的切片。
for _, c := range constraints { // 遍历所有的拓扑分布约束。
if c.WhenUnsatisfiable == action { // 检查约束的 whenUnsatisfiable 字段是否与指定的 action 匹配。
selector, err := metav1.LabelSelectorAsSelector(c.LabelSelector) // 将 LabelSelector 转换为 Selector。
if err != nil { // 如果转换出错,返回错误。
return nil, err
}
// 如果启用了按标签键匹配,并且约束中定义了 MatchLabelKeys,则从 Pod 标签中提取相应的标签。
if pl.enableMatchLabelKeysInPodTopologySpread && len(c.MatchLabelKeys) > 0 {
matchLabels := make(labels.Set) // 初始化一个标签集合。
for _, labelKey := range c.MatchLabelKeys { // 遍历 MatchLabelKeys。
if value, ok := podLabels[labelKey]; ok { // 如果 Pod 标签中包含该键,则添加到集合中。
matchLabels[labelKey] = value
}
}
// 如果集合非空,则将标签集合与选择器合并。
if len(matchLabels) > 0 {
selector = mergeLabelSetWithSelector(matchLabels, selector)
}
}
// 创建 topologySpreadConstraint 结构体实例,填充筛选出的约束的相关信息。
tsc := topologySpreadConstraint{
MaxSkew: c.MaxSkew, // 最大偏差数。
TopologyKey: c.TopologyKey, // 拓扑键。
Selector: selector, // 与标签匹配的选择器。
// 如果 MinDomains 为 nil,我们将其视为 1。
MinDomains: 1,
// 如果 NodeAffinityPolicy 为 nil,我们将其视为 "Honor"。
NodeAffinityPolicy: v1.NodeInclusionPolicyHonor,
// 如果 NodeTaintsPolicy 为 nil,我们将其视为 "Ignore"。
NodeTaintsPolicy: v1.NodeInclusionPolicyIgnore,
}
// 如果启用了最小域特性,并且约束中定义了 MinDomains,则使用该值。
if pl.enableMinDomainsInPodTopologySpread && c.MinDomains != nil {
tsc.MinDomains = *c.MinDomains
}
// 如果启用了节点包含策略特性,则根据约束中的设置更新 NodeAffinityPolicy 和 NodeTaintsPolicy。
if pl.enableNodeInclusionPolicyInPodTopologySpread {
if c.NodeAffinityPolicy != nil {
tsc.NodeAffinityPolicy = *c.NodeAffinityPolicy
}
if c.NodeTaintsPolicy != nil {
tsc.NodeTaintsPolicy = *c.NodeTaintsPolicy
}
}
// 将筛选出的拓扑分布约束添加到结果切片中。
result = append(result, tsc)
}
}
// 返回筛选后的拓扑分布约束列表,如果没有错误发生,则返回 nil。
return result, nil
}其会遍历所有的constrain,只有满足默认的action,即v1.DoNotSchedule才会继续往下执行:
处理pod的selector,注意到这里如果LabelKeys是enable的,会将LabelKeys中定义的label转化成selector,其方法是查看pod中该key对应的value,组成一个selector,然后调用
mergeLabelSetWithSelector函数合并进原来的selector。如下1
2
3
4
5
6
7
8
9
10
11
12
13
14func mergeLabelSetWithSelector(matchLabels labels.Set, s labels.Selector) labels.Selector {
mergedSelector := labels.SelectorFromSet(matchLabels)
requirements, ok := s.Requirements()
if !ok {
return s
}
for _, r := range requirements {
mergedSelector = mergedSelector.Add(r)
}
return mergedSelector
}查看是否默认配置启用了MinDomains特性,如果是就需改MinDomains为设定值。
查看是否默认配置了节点包含策略特性,如果没有就将Pod的节点亲和性约束和节点污点特性添加进来。
如果拓扑约束为空就直接返回,否则初始化一个preFilterState结构体。该结构体的定义如下
1 | |
各个变量的含义参考注释如下:
Constraints:拓扑约束
TpKeyToCriticalPaths:是一个map,key是拓扑键,例如Region、hostName。注意再看一下
criticalPaths的定义,如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// CAVEAT: the reason that `[2]criticalPath` can work is based on the implementation of current
// preemption algorithm, in particular the following 2 facts:
// Fact 1: we only preempt pods on the same node, instead of pods on multiple nodes.
// Fact 2: each node is evaluated on a separate copy of the preFilterState during its preemption cycle.
// If we plan to turn to a more complex algorithm like "arbitrary pods on multiple nodes", this
// structure needs to be revisited.
// Fields are exported for comparison during testing.
// 翻译:
// [2]criticalPath 之所以能够工作,是基于当前的抢占算法实现,特别是以下两个事实:
// 事实 1:我们只在同一个节点上抢占 pods,而不是在多个节点上的 pods。
// 事实 2:在每个节点的抢占周期中,对其评估时使用的是 preFilterState 的一个独立副本。
// 如果我们计划转向更复杂的算法,如“多个节点上的任意 pods”,则需要重新审视这种结构。
// 字段在测试期间被导出以供比较。
type criticalPaths [2]struct {
// TopologyValue denotes the topology value mapping to topology key.
TopologyValue string
// MatchNum denotes the number of matching pods.
MatchNum int
}可以看到
criticalPaths定义了这个拓扑键下的拓扑域中匹配的pod数量。而看注释可以得知
TpKeyToCriticalPaths[0]定义了这个域中最少匹配的pod的数量及相应的value,而TpKeyToCriticalPaths[1]记录了另一个value的情况,它匹配的数量肯定不会比TpKeyToCriticalPaths[0]小。TpKeyToDomainsNum:各个拓扑键下的拓扑域的数量。
TpPairToMatchNum:各个拓扑域匹配的pod的数量。可以注意一下topologyPair的定义,如下:
1
2
3
4type topologyPair struct {
key string
value string
}
并行遍历各个node,统计各个node上各个拓扑域中匹配到的pod的数量。其流程如下
得到node的信息。
如果没有启用节点包含策略特性,那么就检查节点是否符合pod的节点亲和性及node selector的要求,如果不符合就直接返回,如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14// Match checks whether the pod is schedulable onto nodes according to
// the requirements in both nodeSelector and nodeAffinity.
func (s RequiredNodeAffinity) Match(node *v1.Node) (bool, error) {
if s.labelSelector != nil {
if !s.labelSelector.Matches(labels.Set(node.Labels)) {
return false, nil
}
}
if s.nodeSelector != nil {
return s.nodeSelector.Match(node)
}
return true, nil
}检查当前node是否包含了约束需要的拓扑键,即是否有类似于约束要求的region的定义,如果没有就直接返回。
遍历每个拓扑约束:
如果启用了节点包含策略特性,那么就根据配置有选择性地检查当前节点是否符合pod的节点亲和性及node selector的要求,以及是否符合节点污点及容忍的要求。如果不符合,就跳过这个拓扑约束。
matchNodeInclusionPolicies函数如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15func (tsc *topologySpreadConstraint) matchNodeInclusionPolicies(pod *v1.Pod, node *v1.Node, require nodeaffinity.RequiredNodeAffinity) bool {
if tsc.NodeAffinityPolicy == v1.NodeInclusionPolicyHonor {
// We ignore parsing errors here for backwards compatibility.
if match, _ := require.Match(node); !match {
return false
}
}
if tsc.NodeTaintsPolicy == v1.NodeInclusionPolicyHonor {
if _, untolerated := v1helper.FindMatchingUntoleratedTaint(node.Spec.Taints, pod.Spec.Tolerations, helper.DoNotScheduleTaintsFilterFunc()); untolerated {
return false
}
}
return true
}计算这个node上满足selector要求的pod的数量,
countPodsMatchSelector函数如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16func countPodsMatchSelector(podInfos []*framework.PodInfo, selector labels.Selector, ns string) int {
if selector.Empty() {
return 0
}
count := 0
for _, p := range podInfos {
// Bypass terminating Pod (see #87621).
if p.Pod.DeletionTimestamp != nil || p.Pod.Namespace != ns {
continue
}
if selector.Matches(labels.Set(p.Pod.Labels)) {
count++
}
}
return count
}注意这里专门过来了已经删除的pod以及不和要调度的pod在同一namespace的pod。【或许未来可以考虑跨namespace的pod的拓扑约束】
对各个拓扑域匹配的pod的数量进行记录。
汇总统计结果,转化为记录各个拓扑域匹配的pod数量。
如果启用了
MinDomains特性就统计各个拓扑键下拓扑值的数量。统计各个拓扑域的最小匹配的pod数到TpKeyToCriticalPaths中,具体的更新方法如下,补充了部分注释:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32func (p *criticalPaths) update(tpVal string, num int) {
// 首先验证 tpVal 是否已经存在于 criticalPaths 中
i := -1 // 初始化索引 i 为 -1,表示尚未找到匹配的拓扑值
if tpVal == p[0].TopologyValue {
i = 0 // 如果 tpVal 与第一个元素的拓扑值匹配,则索引 i 设为 0
} else if tpVal == p[1].TopologyValue {
i = 1 // 如果 tpVal 与第二个元素的拓扑值匹配,则索引 i 设为 1
}
if i >= 0 {
// 如果索引 i 是非负的,表示找到了 tpVal
p[i].MatchNum = num // 更新找到的拓扑值对应的匹配 pods 数量
if p[0].MatchNum > p[1].MatchNum {
// 如果第一个路径的匹配 pods 数量大于第二个路径,
// 则交换两个路径的拓扑值和匹配数量
p[0], p[1] = p[1], p[0]
}
} else {
// 如果索引 i 是 -1,表示 tpVal 在 criticalPaths 中不存在
if num < p[0].MatchNum {
// 如果新的数量 num 小于第一个路径的匹配 pods 数量,
// 则用第一个路径的信息更新第二个路径
p[1] = p[0]
// 然后更新第一个路径的拓扑值和匹配数量
p[0].TopologyValue, p[0].MatchNum = tpVal, num
} else if num < p[1].MatchNum {
// 如果新的数量 num 小于第二个路径的匹配 pods 数量,
// 则只更新第二个路径的拓扑值和匹配数量
p[1].TopologyValue, p[1].MatchNum = tpVal, num
}
}
}这个方法的逻辑是,首先检查传入的拓扑键
tpVal是否已经存在于criticalPaths中。如果存在,就更新对应的MatchNum。如果不存在,并且新的数量num小于已有的最小数量p[0].MatchNum,则进行相应的更新或替换,同时把原本p[0]的内容转移到p[1]。如果num介于p[0].MatchNum与p[1].MatchNum之间就更新p[1].MatchNum。如此保证一般情况下p[0]是最小的,p[1]是第二小的,除非出现了传入的拓扑值tpVal是已经存在于criticalPaths中的特殊情况。
Filter
Filter函数,如下,补充了部分注释。
1 | |
这里的逻辑就比较简单了,整体流程如下。
- 获取node信息及PreFilter的结果。
- 遍历处理每个拓扑约束constrain,注意这里的约束经过PreFilter筛选后都是没通过就不可以调度的硬约束。
如果node没有这个约束需要查看的拓扑键就返回不通过筛选。
统计域中各个value全局最小的匹配到的node的数量
minMatchNum,函数minMatchNum如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// minMatchNum returns the global minimum for the calculation of skew while taking MinDomains into account.
func (s *preFilterState) minMatchNum(tpKey string, minDomains int32, enableMinDomainsInPodTopologySpread bool) (int, error) {
paths, ok := s.TpKeyToCriticalPaths[tpKey]
if !ok {
return 0, fmt.Errorf("failed to retrieve path by topology key")
}
minMatchNum := paths[0].MatchNum
if !enableMinDomainsInPodTopologySpread {
return minMatchNum, nil
}
domainsNum, ok := s.TpKeyToDomainsNum[tpKey]
if !ok {
return 0, fmt.Errorf("failed to retrieve the number of domains by topology key")
}
if domainsNum < int(minDomains) {
// When the number of eligible domains with matching topology keys is less than `minDomains`,
// it treats "global minimum" as 0.
minMatchNum = 0
}
return minMatchNum, nil
}可以看到如果没有启用MinDomains特性,就直接返回最小值,如果启用了就查看这个拓扑键下拓扑值的数量,如果小于minDomains,就返回0,否则返回最小值。
如果自身也符合这个约束的label筛选要求,那么就设置
selfMatchNum为1,否则设置为0。得到node所在的这个拓扑域的匹配的pod的数量
matchNum计算偏差度,即
skew=matchNum + selfMatchNum - minMatchNum如果偏差度
skew大于可以容忍的最大偏差MaxSkew,那么就返回不通过筛选
- 通过了所有的约束检查,返回nil
Scoring.go
PreScore
PreScore函数如下,补充了部分注释
1 | |
其流程如下:
获取所有节点信息,检查是否有通过筛选的node,如果没有就直接返回
检查是否需要node有所有的拓扑键,如果采取的是自定义的约束或者不是系统默认的约束,就设置为必须得满足
初始化
preScoreState变量,关键的initPreScoreState函数如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64// initPreScoreState 遍历 "filteredNodes" 以筛选出没有所需拓扑键的节点,并初始化:
// 1) s.TopologyPairToPodCounts: 以合格的拓扑对和节点名称为键。
// 2) s.IgnoredNodes: 不应被打分的节点集合。
// 3) s.TopologyNormalizingWeight: 基于拓扑中值的数量,给予每个约束的权重。
func (pl *PodTopologySpread) initPreScoreState(s *preScoreState, pod *v1.Pod, filteredNodes []*v1.Node, requireAllTopologies bool) error {
var err error
if len(pod.Spec.TopologySpreadConstraints) > 0 {
// 如果 Pod 规范中定义了拓扑分布约束,则过滤这些约束
s.Constraints, err = pl.filterTopologySpreadConstraints(
pod.Spec.TopologySpreadConstraints, // Pod 的拓扑分布约束
pod.Labels, // Pod 的标签
v1.ScheduleAnyway, // 调度策略
)
if err != nil {
// 如果获取 Pod 的软拓扑分布约束时出错,则返回错误
return fmt.Errorf("obtaining pod's soft topology spread constraints: %w", err)
}
} else {
// 如果 Pod 规范中没有定义拓扑分布约束,则构建默认约束
s.Constraints, err = pl.buildDefaultConstraints(pod, v1.ScheduleAnyway)
if err != nil {
// 如果设置默认软拓扑分布约束时出错,则返回错误
return fmt.Errorf("setting default soft topology spread constraints: %w", err)
}
}
if len(s.Constraints) == 0 {
// 如果没有拓扑分布约束,则不需要进一步处理,直接返回 nil
return nil
}
topoSize := make([]int, len(s.Constraints)) // 为每个约束维护一个拓扑大小的切片
for _, node := range filteredNodes {
// 如果要求所有拓扑键并且节点标签不匹配分布约束,则将节点添加到忽略集合中
if requireAllTopologies && !nodeLabelsMatchSpreadConstraints(node.Labels, s.Constraints) {
s.IgnoredNodes.Insert(node.Name)
continue
}
for i, constraint := range s.Constraints {
// 对于每个约束,检查节点是否有相应的拓扑键
// 如果是主机名标签,则跳过,因为主机名分布独立处理
if constraint.TopologyKey == v1.LabelHostname {
continue
}
pair := topologyPair{key: constraint.TopologyKey, value: node.Labels[constraint.TopologyKey]}
// 如果拓扑对在计数映射中不存在,则初始化它并增加相应约束的拓扑大小
if s.TopologyPairToPodCounts[pair] == nil {
s.TopologyPairToPodCounts[pair] = new(int64)
topoSize[i]++
}
}
}
// 为每个约束初始化拓扑归一化权重,基于拓扑中值的数量
s.TopologyNormalizingWeight = make([]float64, len(s.Constraints))
for i, c := range s.Constraints {
sz := topoSize[i]
// 如果拓扑键是主机名,则使用过滤后的节点数减去忽略的节点数作为大小
if c.TopologyKey == v1.LabelHostname {
sz = len(filteredNodes) - len(s.IgnoredNodes)
}
// 计算并设置拓扑归一化权重
s.TopologyNormalizingWeight[i] = topologyNormalizingWeight(sz)
}
return nil
}其运行流程如下
- 查看pod是否有拓扑约束,如果有就读取,如果没有就创建一个系统默认的的拓扑约束,与PreFilter类似。
- 如果拓扑约束为空直接返回nil
- 开始遍历筛选过后的node
如果需要检查是否包含所有的拓扑键,但是node没有全部的拓扑键,那么就将这个node加入到
IgnoredNodes中,然后跳过这个node遍历所有的拓扑约束:
- 如果拓扑约束的拓扑键是
hostName那么就跳过,因为其后面会特殊处理 - 查看是否在之前统计了这个node上对应的拓扑键-拓扑值,如果没有就加入,然后这个拓扑约束的
topoSize+1。故最后topoSize会记录各个拓扑约束中拓扑键对应的拓扑值的个数。
- 如果拓扑约束的拓扑键是
计算各个拓扑约束的权重,也需要遍历所有的拓扑约束
- 得到这个拓扑约束中
topoSize的值 - 如果拓扑约束的拓扑键是
hostName,那么就将topoSize设置为len(filteredNodes) - len(s.IgnoredNodes),即不能被忽略的node的个数 - 计算这个拓扑约束的权重,计算函数
topologyNormalizingWeight如下
1
2
3
4
5
6
7
8
9
10
11
12// topologyNormalizingWeight calculates the weight for the topology, based on
// the number of values that exist for a topology.
// Since <size> is at least 1 (all nodes that passed the Filters are in the
// same topology), and k8s supports 5k nodes, the result is in the interval
// <1.09, 8.52>.
//
// Note: <size> could also be zero when no nodes have the required topologies,
// however we don't care about topology weight in this case as we return a 0
// score for all nodes.
func topologyNormalizingWeight(size int) float64 {
return math.Log(float64(size + 2))
}权重即为
ln(topoSize+2),即拓扑键对应的拓扑值种类越多,权重就越大,一般而言肯定是hostName这种拓扑键的约束权重最大了。- 得到这个拓扑约束中
如果权重不为空就将权重写入到
cycleState中得到要调度的pod的node亲和性
并行遍历各个node,流程如下
- 得到node的信息
- 与PreFilter类似,如果没有启用节点包含策略,就检查是否通过了node亲和性及node selector的约束,如果没有直接返回
- 如果需要node有所有的拓扑键,但是node没有,那么也会直接返回
- 遍历每个拓扑约束,流程如下
如果启用了节点包含策略特性,那么就根据配置有选择性地检查当前节点是否符合pod的节点亲和性及node selector的要求,以及是否符合节点污点及容忍的要求。如果不符合,就跳过这个拓扑约束。
如果拓扑键是hostName,也直接跳过(后面在
Score时再计算)计算这个拓扑约束的拓扑键对应的拓扑域上相匹配的pod的个数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17func countPodsMatchSelector(podInfos []*framework.PodInfo, selector labels.Selector, ns string) int {
if selector.Empty() {
return 0
}
count := 0
for _, p := range podInfos {
// Bypass terminating Pod (see #87621).
if p.Pod.DeletionTimestamp != nil || p.Pod.Namespace != ns {
continue
}
if selector.Matches(labels.Set(p.Pod.Labels)) {
count++
}
}
return count
}
将结果写入到
cycleState中,与PreFilter基本是一样的操作,最后得到是各个各个拓扑域对应的匹配的pod的数量
Score
代码如下
1 | |
其流程比较简明,如下
得到node的信息及PreScore的结果
如果node在没通过筛选需要被忽略的node,即
IgnoredNodes中,那么返回分数为0遍历各个拓扑约束,计算分数
得到这个node对应在这个拓扑约束的拓扑键中的拓扑域
如果这个拓扑约束的拓扑键是hostName是hostName,那么就调用
countPodsMatchSelector计算这个node上匹配的pod数量cnt,不然就从PreScore的结果中得到对应的拓扑域上匹配的pod数量cnt调用scoreForCount对当前的拓扑约束进行分数计算
1
2
3
4
5
6
7// scoreForCount calculates the score based on number of matching pods in a
// topology domain, the constraint's maxSkew and the topology weight.
// `maxSkew-1` is added to the score so that differences between topology
// domains get watered down, controlling the tolerance of the score to skews.
func scoreForCount(cnt int64, maxSkew int32, tpWeight float64) float64 {
return float64(cnt)*tpWeight + float64(maxSkew-1)
}计算方式为
cnt*拓扑约束的权重+maxSkew-1。【至于为什么要这样打分暂时也没想清楚】
最终得到了各个拓扑约束下的总分,并返回