【论文阅读】Fluid:Dataset Abstraction and Elastic Acceleration for Cloud-native Deep Learning Training Jobs
论文基础信息
论文地址: Fluid: Dataset Abstraction and Elastic Acceleration for Cloud-native Deep Learning Training Jobs
收录会议: 2022 IEEE 38th International Conference on Data Engineering (ICDE)(CCF-A,数据库领域顶会)
作者机构: 阿里云X南京大学
开源项目地址:fluid
背景
深度学习快速发展,其既需要计算也需要数据,同时越来越倾向采用容器化和云原生技术,但是这种环境下存在计算与存储分离的特点,而一般从远端读取数据过慢,会存在I/O瓶颈。
现有机器学习框架有采用了I/O与GPU计算重叠的方式,但是这不足以消除瓶颈,而其他的预读取、内存缓存、多层次缓存等方式更适用于传统集群而不是云原生环境,主要不足在于:
- 云中具有不同访问协议的异构存储方法,其导致程序复杂。缓存系统配置复杂,鉴于各种云环境下数据集的不同及用户理解的困难,难以配置性能良好的缓存系统。
- 云中的计算资源具有高度灵活性和弹性,这要求缓存也应随其自动拓展,而如何及时准确估计缓存需求、高效动态拓展是一个难题。
- 同一数据集训练多个模型很流行,如何在多个深度学习作业之间有效共享数据存在挑战,这要求降低共享数据缓存的大小,避免频繁的数据缓存抖动,从而提高整体训练性能。
创新
- 将数据集进行抽象(提供了Fluid Dataset的CRD),并以PVC的统一形式提供用户使用。同时每个Fluid Dataset都由自动调整的Cache Runtime(如使用开源的Alluxio系统)提供缓存支持。
- 设计了一种基于训练速度跟踪的缓存自动拓展机制,以自动调整缓存容量,匹配训练速度和计算资源。
- 提出了一种数据缓存和DL作业协同感知的调度策略,通过高效的缓存机制加速具有某些相同数据集的多个DL训练作业的整体性能。
- 实验结果表明Fluid具有优越的性能,将Fluid 与现有的广泛使用和前沿解决方案集成时可将性能提高约 2 倍。
方法
数据集抽象和管理
Fluid Dataset作为数据集的抽象,Cache Runtime作为Cache的抽象,一个Cache Runtime与Fluid Dataset一一对应。如此设计更加灵活,相比于统一的缓存方案,其优点在于:
- 分解的缓存管理器不太可能成为瓶颈,尤其是当许多文件元数据操作处于高度并行时;
- 这允许我们根据不同数据集的特点调整分布式缓存系统的配置,从而达到最优的配置。
分布式缓存自动配置
系统配置(例如线程池大小和元数据缓存级别)对于分布式缓存系统非常重要,因为它们会极大地影响不同类型的文件操作的性能。所以这里将候选配置、Dataset特征输入到一个预训练好的模型进行打分,然后选择最高得分的配置。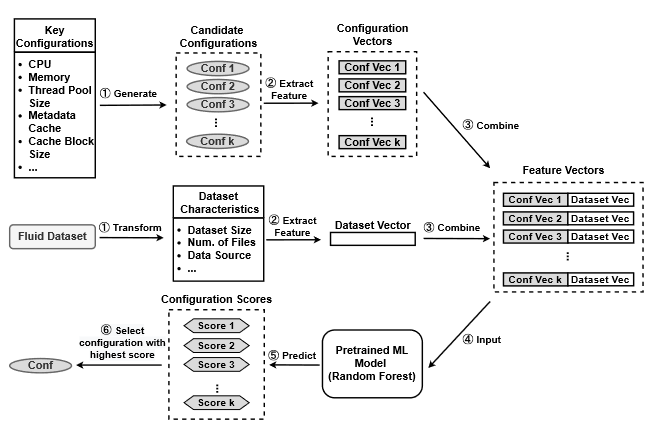
动态缓存系统的自动拓展
为了实时测量深度学习作业的训练速度,协调器收集在时间窗口T内总共训练的样本数SampleNum,从而得到训练速度为SampleNum/T
Fluid通过反复实验的方式拓展缓存容量,其算法如下,主要根据训练速度不断调整。
基于共享的调度策略
旨在优先运行已缓存的作业,同时通过考虑数据集的特征来推测DL作业的运行时间。
调度打分如下,选取得分最高的进行调度。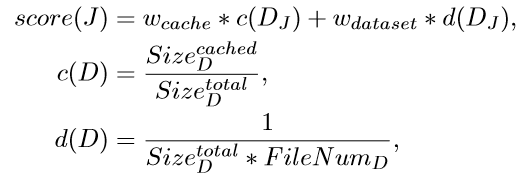
具体实现
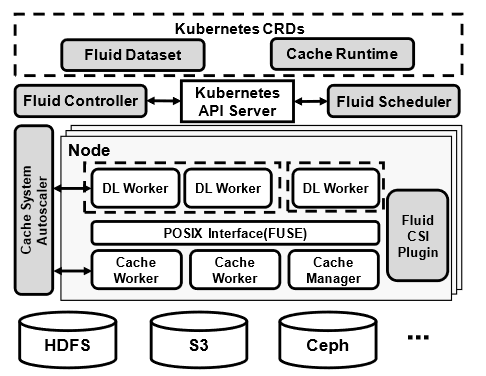
Fluid Controller
将Fluid Dataset和Cache Runtime定义为CRD,再定义Fluid COntroller为operator,Fluid COntroller负责绑定两者,同时配置的ML模型也在其中,一旦缓存就位,就会创建相应的PV和PVC,用户通过引用PVC来访问数据文件。
Fluid Csi插件
Kubernetes 提供了容器存储接口(CSI) 。当任何容器需要通过分布式缓存系统访问数据时,它会引用相应的 PVC,然后 Fluid CSI 插件负责将分布式缓存系统挂载到容器上。
缓存系统自动缩放器
缩放器就是前诉的协调器,它从DL工作者那里收集实时训练速度,并指示分布式缓存系统动态扩展缓存容量,以容纳与 DL 作业训练速度相匹配的训练示例数量。此外,如果缓存容量不足以容纳所有预取的训练示例,缓存系统自动缩放器将添加更多缓存工作者,以动态增加分布式缓存系统的可用缓存容量。此外,我们还通过逐出已使用的训练示例来优化缓存使用率,因为它们不会在同一时期被使用。
Fluid调度器
该调度器基于K8s的原生调度器容器实现,通过 Kubernetes APIServer,调度器定期监视所有节点的资源状态以及缓存系统的状态,当一些资源被释放且可以调度一批深度学习作业时,Fluid 调度器会根据依赖数据集等因素对所有待处理的深度学习作业进行评分,并将得分最高的深度学习作业提交给容器调度器。
使用实例
一个简单的使用实例如下: