【论文阅读】{MegaScale}:Scaling Large Language Model Training to More Than 10,000 {GPUs}
论文基础信息
论文地址: {MegaScale}: Scaling Large Language Model Training to More Than 10,000 {GPUs}
收录会议: 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24)(CCF-A,计算机网络顶级会议)
作者机构: 字节跳动x北京大学
部分组件的开源地址:veScale
摘要
MegaScale是字节跳动一个用于训练超过1万台GPU规模的LLM的生产系统。
为了提高大规模系统的效率,他们采用全栈方法,跨model block和优化器设计、计算和通信重叠、算子优化、数据管道和网络性能调整来共同设计算法和系统组件。
为了提高大规模系统的稳定性,他们加强了对系统的可观测性,开发了一套诊断工具来监控各个系统组件和事件,识别报错根本原因。
最终在 12,288 个 GPU 上训练 175B LLM 模型时,MegaScale 实现了 55.2% 的模型 FLOP 利用率 (MFU),与 Megatron-LM 相比,MFU 提高了 1.34 倍。
背景
LLM展示出来的巨大能力越来越被被重视。缩放定律显示了模型大小和训练数据大小是决定模型能力的关键因素。所以人们开始在数千亿乃至数万亿的token上训练具有数千亿甚至数万亿参数的大型模型。LLM领域的主要参与者构建了拥有数万个 GPU 的大规模 AI 集群来训练LLM。传统虽然也有管理过万台GPU,但是那都是面对多个小任务,而现在LLM一个任务就占据了数万台GPU,这带来了两个挑战:
- 如何提高训练效率。其中主要指标看的是FLOP模型利用率,即假设峰值 FLOP 为 100% 时观察到的吞吐量与理论最大吞吐量的比率。这挑战包括了通信、算子优化、数据预处理、GPU内存消耗等。
- 如何提高稳定性。训练过程中故障和掉队是LLM训练的常态,但是其故障的代价也是非常高昂的,所以减少恢复时间至关重要;而掉队不仅影响自己的工作,还会减慢涉及数万个GPU的整个工作。
为了解决这两个挑战,提出了两个系统设计原则:
- 算法-系统协同设计。其
- 对模型架构进行了一些修改并融入了有效的优化技术,包括parallel transformer、slide window attention、LAMB optimizer。
- 利用混合并行策略,将数据并行、piple并行、张量并行和序列并行相结合。并根据每个并行策略的模式设计定制技术,以最大化通信和计算之间的重叠。
- 应用预取和基于树的加载来优化数据管道。
- 我们利用非阻塞异步操作,消除大规模集体通信组初始化的全局障碍。
- 设计自定义网络拓扑,减少 ECMP 哈希冲突,自定义拥塞控制,并调整重传超时参数以获得高网络性能。
- 深度可观测性。
- 许多硬稳定性问题只会大规模出现,这可能源于堆栈深处的各种软件和硬件故障。考虑到系统的规模和复杂性,手动识别和解决每个问题是不可行的。
- 我们应用深度可观察性的原理构建了一套诊断工具。我们所说的“深度可观察性”是指一种全面的监控和可视化策略,它超越表面指标,收集系统堆栈每个组件的详细、精细的数据,旨在创建系统性能的多维视图。这套工具使我们能够通过揭示复杂的相互作用和依赖机制来诊断系统并确定根本原因。
- 我们开发了一个强大的训练框架来自动化故障定位和恢复。我们设计了封装各种形式信息的心跳消息,以方便实时异常检测并提供早期预警。我们实施了一套诊断测试来识别导致中断的节点。我们优化检查点和恢复程序以减少中断。为了解决掉队造成的细微差别,我们开发了一个性能分析工具来记录细粒度的 CUDA 事件并从分布式视图生成系统范围的热图和时间线跟踪,并开发了一个 3D 并行训练可视化工具来显示排名之间的数据依赖关系诊断。
大规模高效训练
模型算法优化
并行transformer
采取之前使用过的并行transformer架构,如下的一个变化:
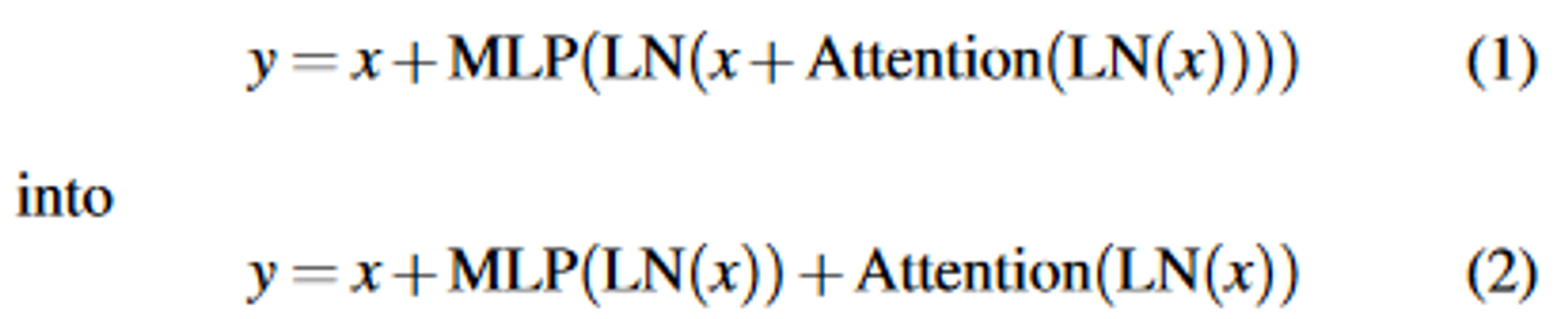
这可以使得MLP块和Attention块并行进行。
滑动窗口注意力(SWA)
滑动窗口注意力是一种稀疏注意力机制,它采用围绕输入序列中每个标记的固定大小的窗口。计算复杂度为 O(s × w),其中 s 是输入序列长度,w 是固定窗口大小。滑动窗口注意力比完全自注意力更有效,其计算复杂度为 O(s × s),假设 w ≪ s。
LAMB优化器
为了提高批量大小从而进行大规模高效训练,我们采用LAMB 优化器,其已被证明可以在不影响准确性的情况下将 BERT 的训练批量大小扩展到 64K。在 LLM 设置中,我们的实验发现 LAMB 可以将批量大小扩展到 4 倍,而不会损失精度。
3D并行中的通信折叠
数据并行优化
针对数据并行中从其他模型更新参数的前向传递的all-gather和在收集梯度的后向传递的reduce-scatter操作,由于all-gather 操作在模型块的前向传递之前触发,reduce-scatter 操作在其向后传递后开始。这导致了第一个全收集操作和最后一个reduce-scatter操作无法隐藏的挑战。受 PyTorch FSDP 的启发,初始all-gather 操作在每次迭代开始时预取,使其与数据加载操作重叠,有效地将通信时间减少 1/(2 * vpp_size) 。我们还首先启动高优先级通信以最大化重叠。通信算子的优先级由依赖于通信结果的相应计算算子的顺序确定。
pipline并行重叠优化
对于warm-up阶段,我们将发送和接收解耦,使得操作可以和计算重叠,同时也避免了被较慢的发送和接收所阻塞。
对于cool-down阶段,作为warma-up的逆过程,我们逆向应用相关优化。
对于steady阶段,由于前向和后向计算都独立于相邻的通信操作,所以使发送和接收操作异步启动以与计算重叠
张量/序列并行性重叠
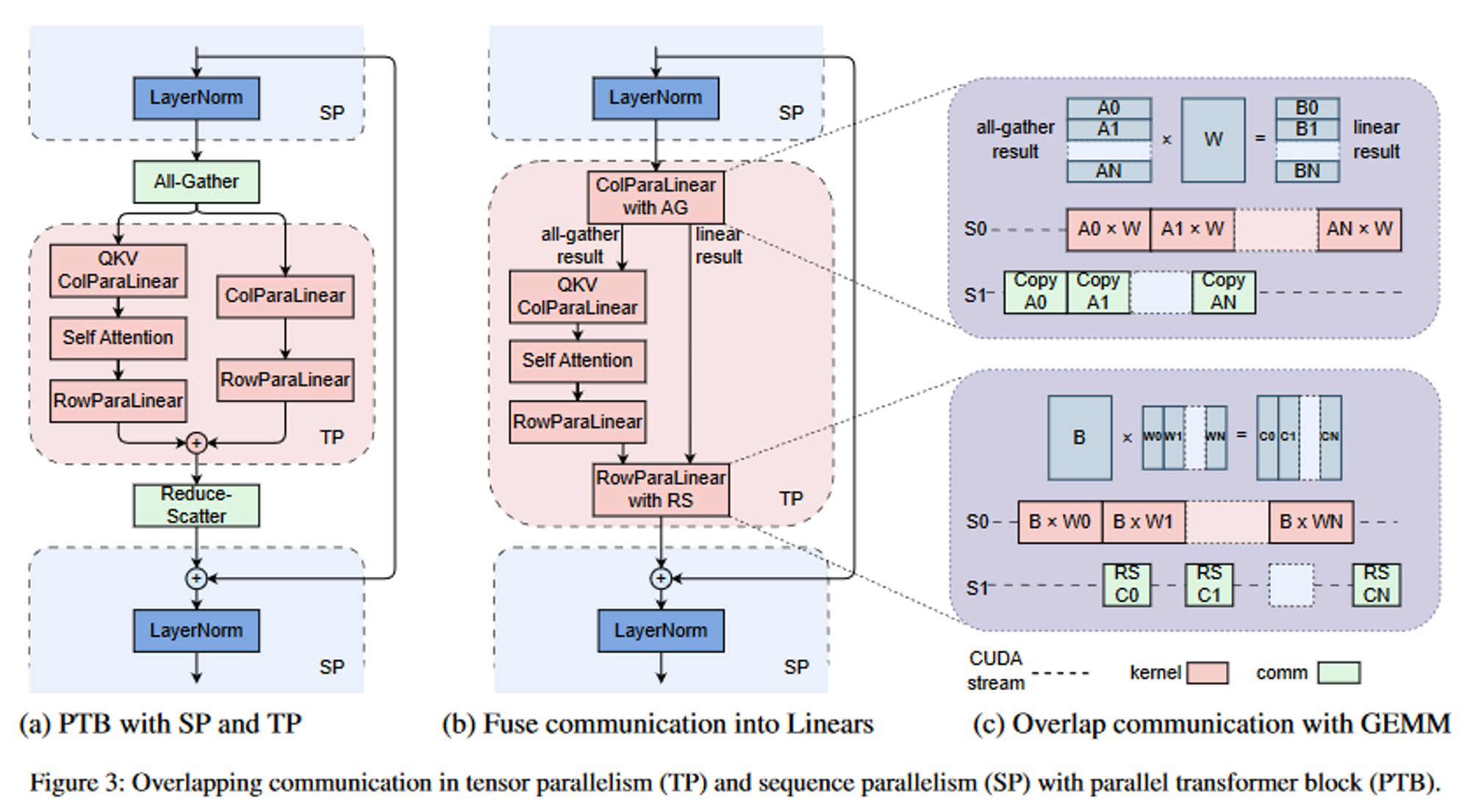
张量并行通常用于计算密集型操作中的权重划分,而 LayerNorm 和 Dropout 等操作则沿序列维度进行划分以节省 GPU 内存。这就需要对 GPU 之间的输入收集和输出重新分配进行all-gather和reduce-scatter操作。
下图 a 显示了并行transformer架构中的这种通信模式。在这里,两个通信操作处于关键路径上。为了消除这种开销,我们选择将all-gather和reduce-scatter与 FFN 路径上的并行线性融合(下图 b)。由于FFN路径上的GEMM核较大,因此可以更好地隐藏通信。我们将 GEMM 内核分成小块,并通过通信管道执行(下图c)。该策略可以类似地应用于向后传递
算子优化
采用flash-attention2来通过改进不同线程块和线程束之间的工作划分对transformer的进行优化。
对于 LayerNorm 和 GeLU算子还进行了算子融合的优化,从而优化了内存的访问,实现了更好的性能。
数据Pipeline优化
目标是隐藏数据预处理和数据加载的时间消耗,从而减少GPU的空闲。手段如下:
- 异步数据预处理:当 GPU 工作线程在每个训练步骤结束时同步梯度时,可以开始后续步骤的数据预处理,从而隐藏了预处理开销。
- 减少冗余数据加载:传统分布式训练的典型数据加载阶段,每个GPU worker都有自己的数据加载器,通过将数据读取到CPU中再传递到GPU中,多个work的读取会导致磁盘带宽读取的瓶颈。考虑到一台机器上的GPU worker都在同一个张量并行组中,所以每次迭代输入的数据都相同,故在每台机器上使用单个专用的数据加载器将数据读取到共享内存中,然后GPU worker直接将必要的数据复制到自己的GPU内存中进行处理。
集体通讯组初始化
在初始化时,需要在各个GPU worker之间建立NVIDIA集体通信组(NCCL),默认实现在2048个GPU上的初始化需要1047秒,虽然这对于训练时间微不足道,但是却对日常测试开发造成了影响,还阻碍了快速重启和恢复机制,故对其进行了优化。
- 优化barrier operation:采用异步非阻塞的Redis替换单线程阻塞的TCPStore。这将2048个GPU上的初始化时间减少到了361秒。
- 优化global barrier:通过设计通信组初始化的顺序,以尽量减少对global barrier的需要。这种方法将全局屏障的时间复杂度从 O(n2) 降低到 O(n)。通过这些优化,初始化时间在 2048 个 GPU 上减少到 5 秒以下,在超过 10,000 个 GPU 上减少到 30 秒以下。
网络性能调优
主要优化的手段包括以下这些(不做详细介绍了):
- 优化网络拓扑:数据中心网络采用基于 Broadcom Tomahawk 4 芯片的高性能交换机构建。
- 减少 ECMP 哈希冲突。精心设计了网络拓扑并调度网络流量,以减少 ECMP 哈希冲突。
- 拥塞控制:开发了一种结合了 Swift 和 DCQCN 原理的算法,将往返时间 (RTT) 的精确测量与显式拥塞通知 (ECN) 的快速拥塞响应功能集成在一起。
- 重传超时设置:重新设置NCCL中的参数来控制重传定时器和重试计数,并在 NIC 上启用了 adap_retrans 功能。
大规模训练容错
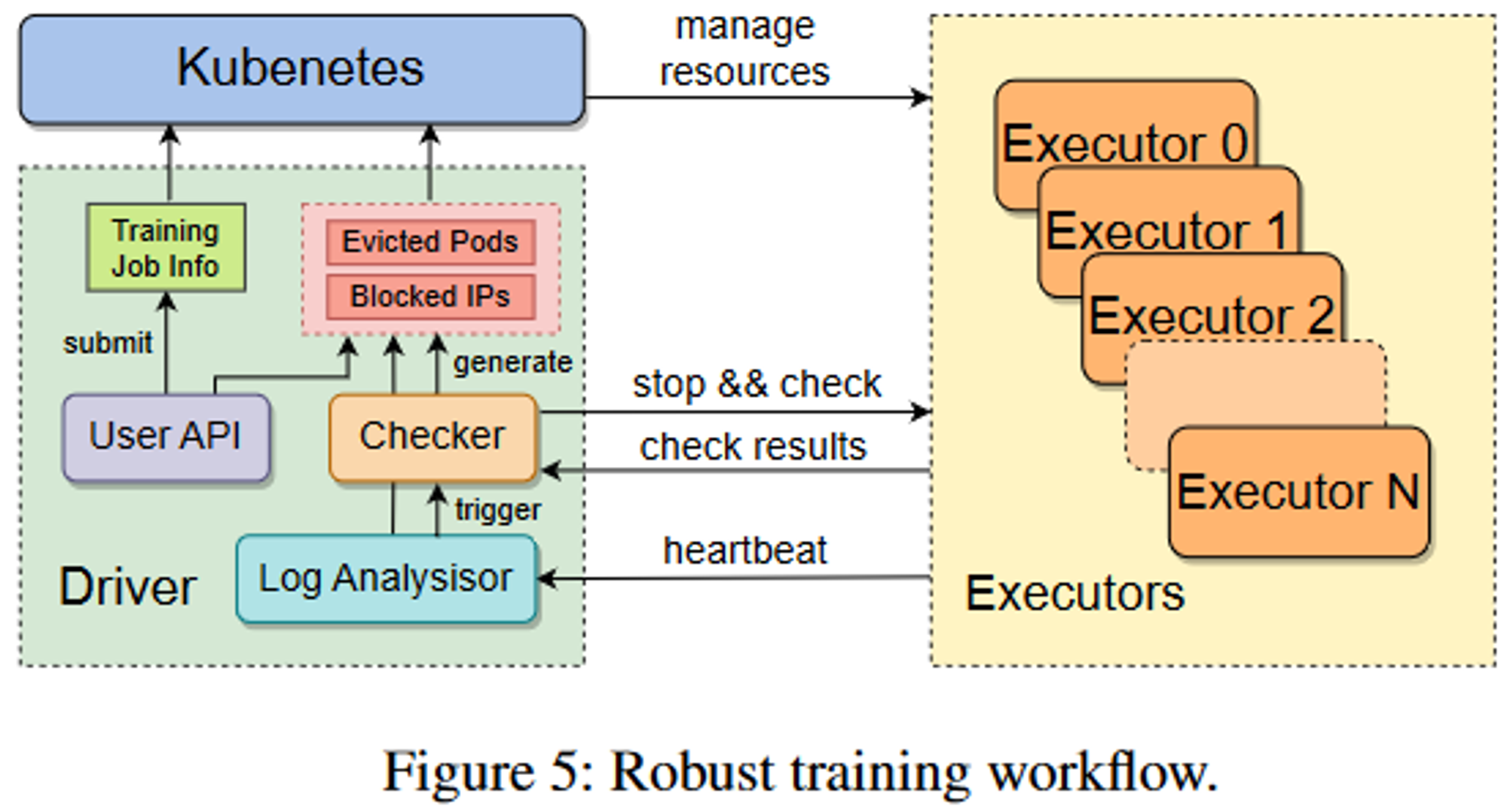
鲁棒性的训练工作流
如下图所示,用户将训练任务提交给Driver后,他与k8s进行交互,为每个Executor分配资源并启动相应的pod,一个Exector关联一个node。Exector需要定期通过心跳给Driver上报信息,如果收到了异常信息或者超时未收到信息,那么就会停止所有Exector的任务执行,并启动自检程序,识别到有问题的节点后,将相关节点上报给k8s进行驱逐,并补充等量的通过了健康检查的节点。
监控数据收集和分析
心跳信息包括:
- Exector基本信息
- 训练的日志信息,用来识别警告、错误等关键字
- RDMA流量指标,有些异常发生后,训练还是能继续进行,这时就可以通过分析RDMA流量指标来分析,因为训练具有周期性,一般流量情况都相似,如果出现异常波动,就需要进行人工排除或启动自动恢复程序了。
为了加强对训练稳定性和表现的监控,还开发了精度达到毫秒级的监控系统:
- 二级监控通常用于评估整体健康状况并排除常见配置对训练的影响。
- 毫秒级的监控也用于判断网络是否拥塞,数据并行和管道并行的数据传输速度是否达到物理极限。
诊断测试
自检诊断的执行时间和准确性之间存在权衡。通过迭代实验和优化,我们部署了一套轻量级诊断测试,有效覆盖了实际训练过程中遇到的各种硬件和软件故障。
主机内网络测试:
- 环回测试测量从所有 RDMA NIC (RNIC) 到各种主机内端点(包括内存节点和 GPU)的环回带宽。
- RNICto-RNIC 测试检查同一主机上不同 RNIC 之间的连接和带宽性能。
NCCL 测试:
- 为了识别 GPU 通信中的潜在故障,我们在单个节点内的 GPU 之间运行全面测试,以观察带宽是否符合预期基准。
- 一旦主机内通信测试通过,每个节点还会与同一 ToR 交换机下的相邻机器进行 all-reduce 测试,以评估节点间 GPU 通信。
快速检测点和恢复
目的是为了确保最新的检查点尽可能接近故障发生时的训练进度状态,同时还希望减少检查点过程引入的延迟,特别是关键路径上阻碍训练进度的时间,从而阻碍整体系统吞吐量。
为了快速构建检查点,引入了一种优化的两阶段方法:
- 第一阶段:每个GPU将其片上状态写入到主机内存中,然后继续训练,过程可缩短到几秒钟
- 第二阶段:后台进程接管,将主机内存异步传输到分布式文件系统(HDFS)中
为了优化从检查点恢复的过程,由于其瓶颈主要在于HDFS的带宽,又意识到多个GPU worker通常都共享相同的状态分区,如同一个数据并行组的worker,为了避免重复读,一组中只有一个worker从HDFS读取,然后再将其状态广播给其他需要的GPU worker。
大规模训练故障排除
尽管我们强大的训练框架可以自动发现、查明并解决大多数常见故障,但仍然存在某些硬件异常现象,这些异常现象以概率的形式出现,无法通过机器自检发现。一些异常可能会使系统看似正常运行,但会显着降低训练效率。为了解决这些细微差别的情况,我们实现了多种自定义监控和分析工具,旨在支持逐案异常检测。
使用 CUDA 事件监视器进行性能诊断
在大规模实验中观察到不同的running表现出不同的计算效率。即使使用相同的配置,这种不一致仍然存在,如下图所示。我们还观察到,训练任务的性能在此规模上并不一致。各种训练任务的 MFU 随着时间的推移逐渐下降。但是在单 GPU GEMM 微基准测试下没有检测到明显的差异。
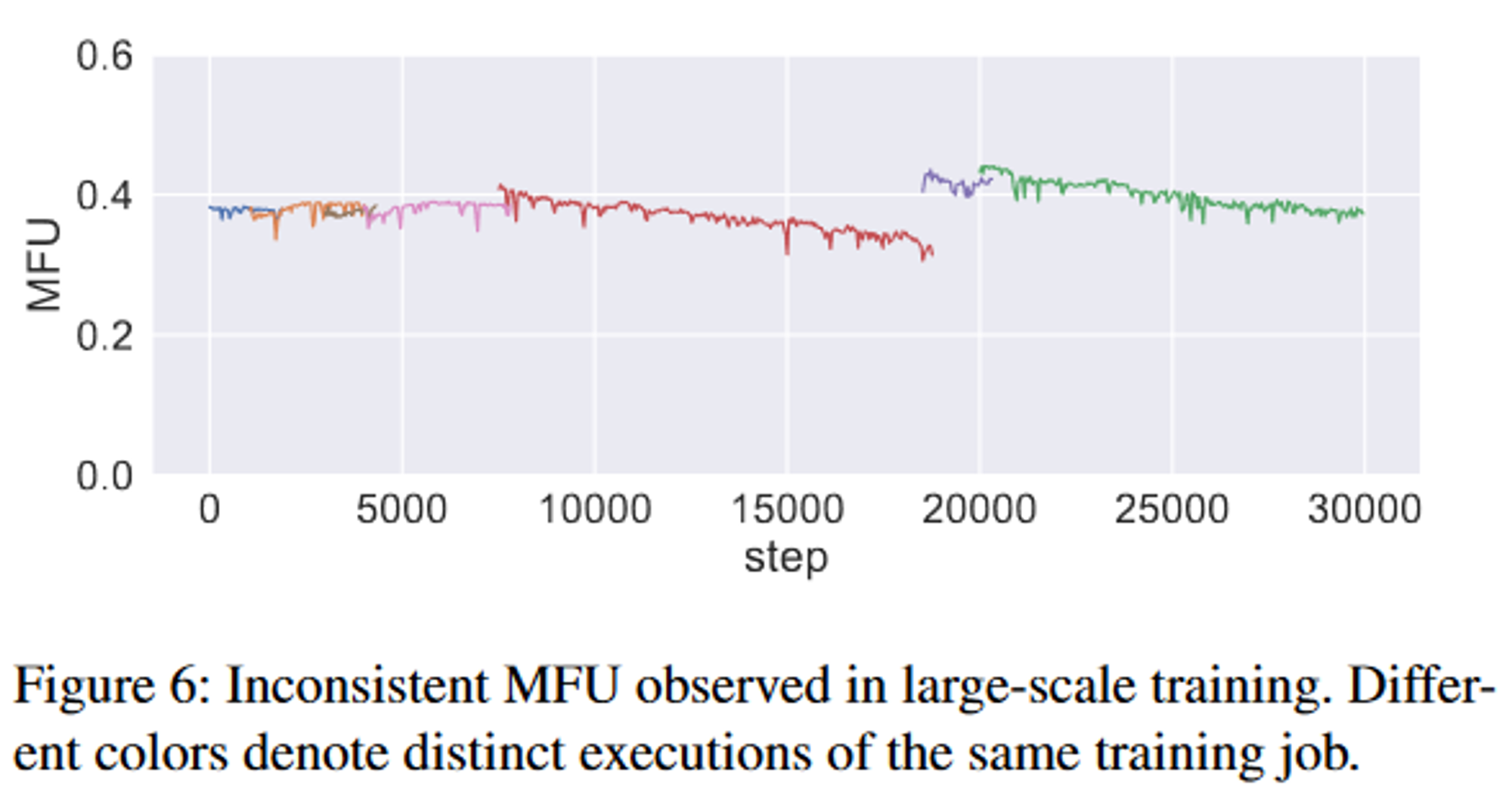
为了诊断这种性能问题,我们开发了一种性能分析工具,用于记录运行期间每个机器级别上关键代码段的执行时间。其基于CUDA事件方法对事件进行计时,以防止性能损失并提供两种可视化模式,可以从不同角度分析收集到的数据。
- 第一种模式使用热图来显示不同维度的机器之间的时间消耗差异。由于训练性能主要由最慢的主机所决定,所以在观察到了性能表现较差的主机后可以将其驱逐出去。
- 第二种模式从不同的分布式视图(数据并行性、管道并行性、张量并行性)以跟踪格式显示机器上的事件时间线。通过将各种等级的跟踪跨度聚合到单个时间线上,我们获得了全面的视角,揭示了数据并行等级之间的整体执行顺序、管道气泡和同步特征。
当计时器数据以逐行格式写入本地文件时,一个单独的流处理进程会将该日志文件与 Kafka 队列实时同步。分析数据库通过使用来自该 Kafka 队列的数据来保持更新,从而在不中断训练作业的情况下实现动态分析。
3D 并行训练可视化
由于3D并行技术的使用以及前述的优化技术的使用,数据流和任务排序变得极其复杂,各个GPU worker之间存在复杂依赖关系,这加大了故障检测的挑战:
单个GPU worker故障,可能会导致整个集群的NCCL通信停滞,从而导致大量的超时的消息。为了快速排除,我们让每个GPU worker在通信超时的时候记录自己正在进行的事件。然后,使用这些日志根据 3D 并行设置中的逻辑拓扑构建数据依赖关系的可视化表示。从而支持快速查明有问题的节点,一旦确定,这些节点可以通过强大的训练框架手动隔离和标记以进行维护。
实验
这里指出MegaScale 构建于 Megatron-LM 之上,通过各种实验展示了MegaScale的优越性。其中在 12,288 个 GPU 上训练 175B LLM 模型时,MegaScale 实现了 55.2% MFU,比 Megatron-LM 提高了 1.34 倍。