Transformer 详解
概览
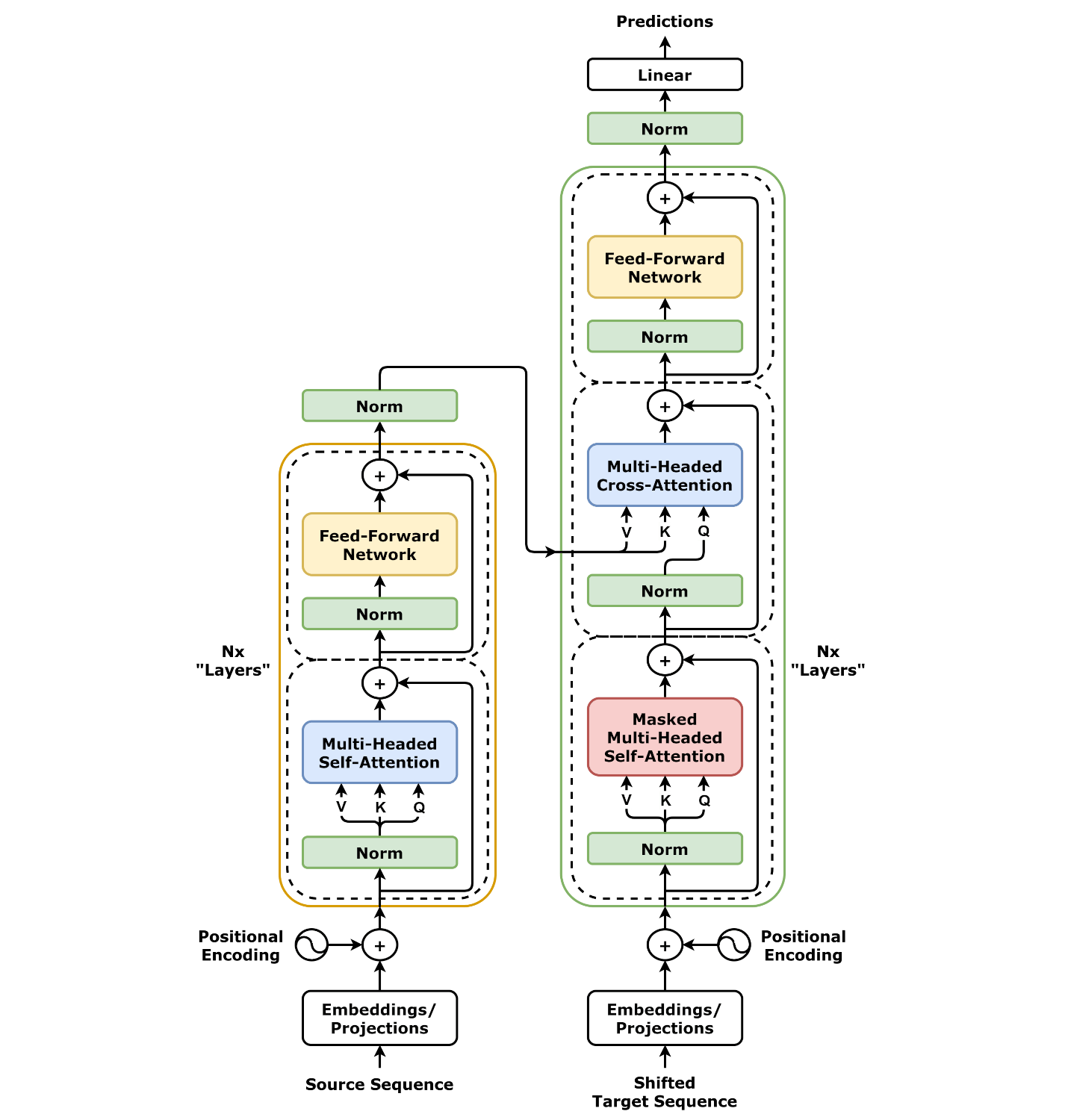
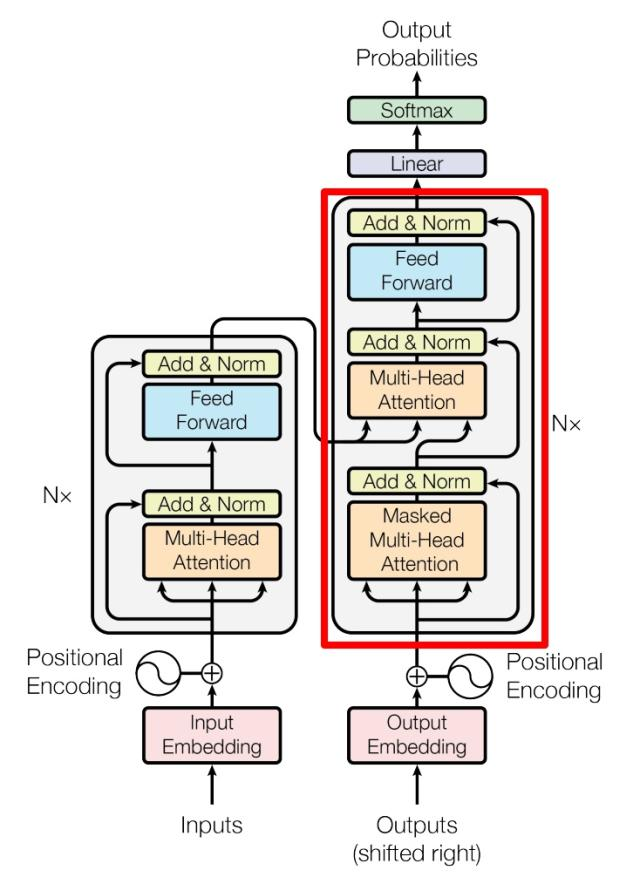
Transformer由两个部分组成,包括Decoder和Encoder两个部分
Self-attention
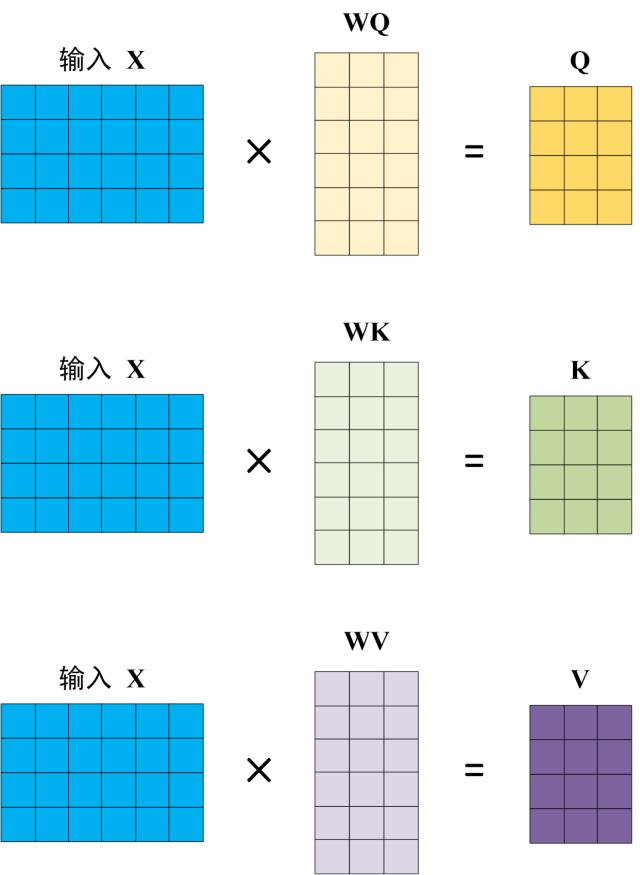
对于输入X,我们有对应的WQ、WK、WV矩阵,可以计算得到,Q、K、V
Q代表查询向量(Query)
K代表键向量(Key),KQ其实就代表了对于各个字符的注意力
V代表值向量(Value),需要与注意力相乘得倒最后的值
然后依据下面的公式可以计算出对应的Attention。公式中计算矩阵Q和K每一行向量的内积,为了防止内积过大,因此除以 dk 的平方根

注意softmax的公式为:
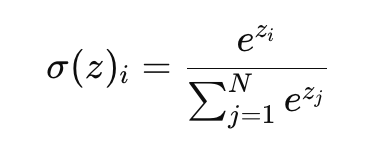
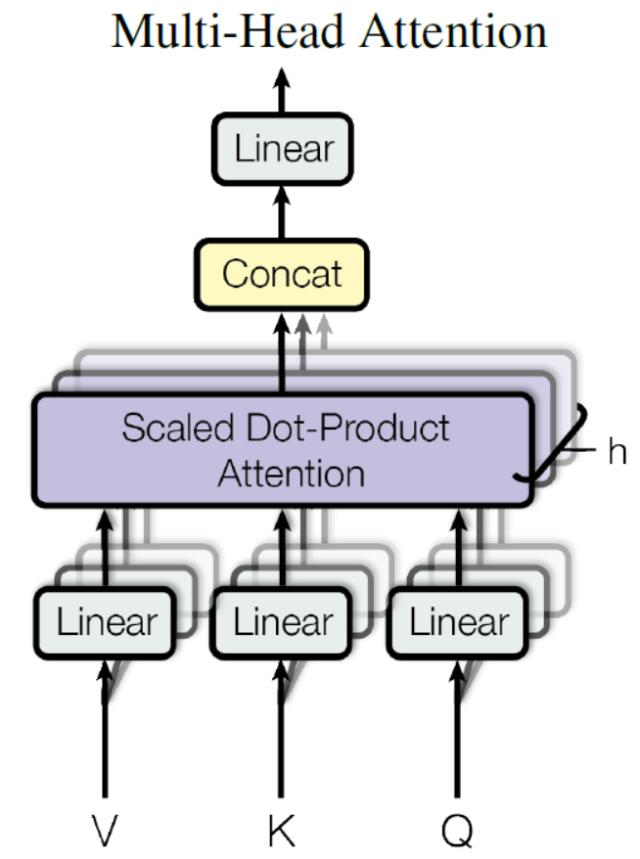
Multi-Head Attention
Multi-Head Attention 是由多个 Self-Attention 组合形成的,下图是论文中 Multi-Head Attention 的结构图。
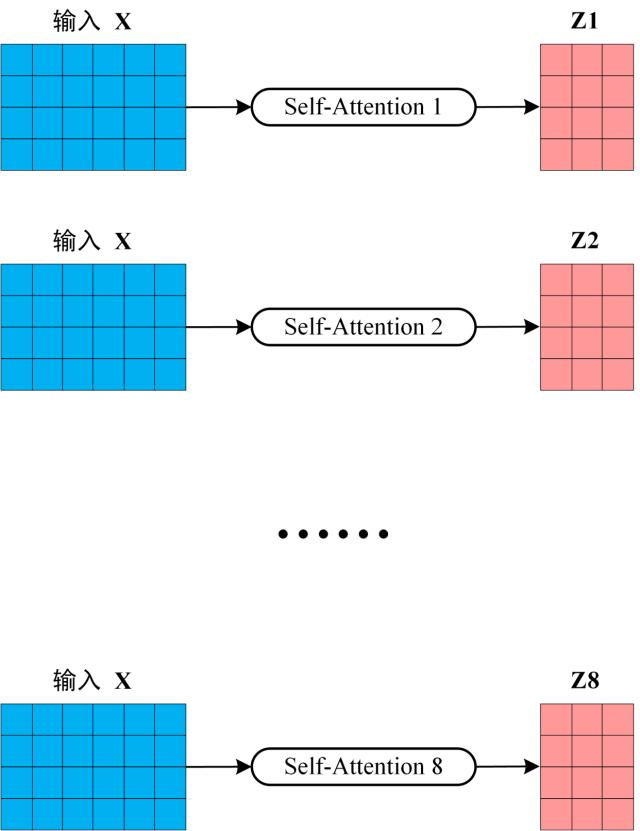
下图是 h=8 时候的情况,此时会得到 8 个输出矩阵Z。
得到 8 个输出矩阵 Z1 到 Z8 之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出Z。
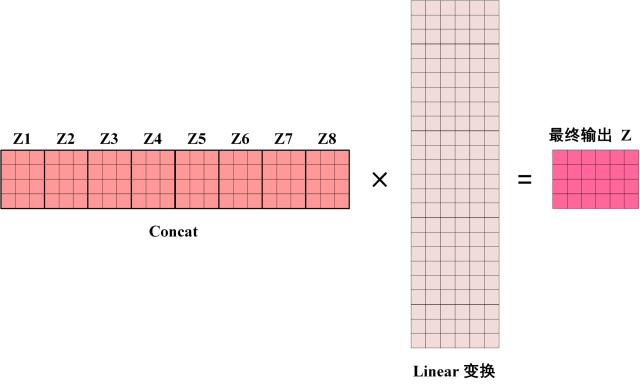
可以看到 Multi-Head Attention 输出的矩阵Z与其输入的矩阵X的维度是一样的。
Positional Encoding
Transformer中attention在对字符串对处理过程中是并行的,直接相乘即可,所以没有像RNN那样有位置信息,所以需要添加位置信息,在transormer原文中采用了固定位置编码(Sinusoidal Positional Encoding)的方式,其计算公式如下:
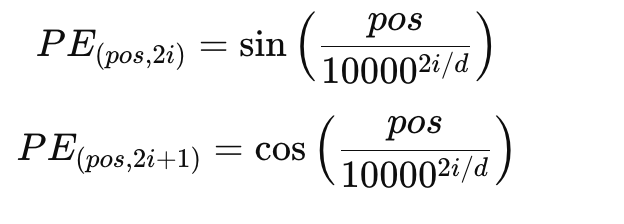
其中:
pospospos 是序列中某个位置的索引(从 0 开始)。
i 是位置编码的维度索引(从 0 开始)。
d 是位置编码的总维度,通常与词嵌入维度相同。
公式中的10000^{2i/d}是一个缩放因子,控制不同维度的周期性,使得较小的维度具有较高的频率,较大的维度则具有较低的频率。
使用正弦和余弦函数是为了保证每个位置的编码是周期性的,同时具有较高的区分度,能够区分不同位置之间的关系。
Encoder
下图左边是Encoder架构,它由多个block组成:
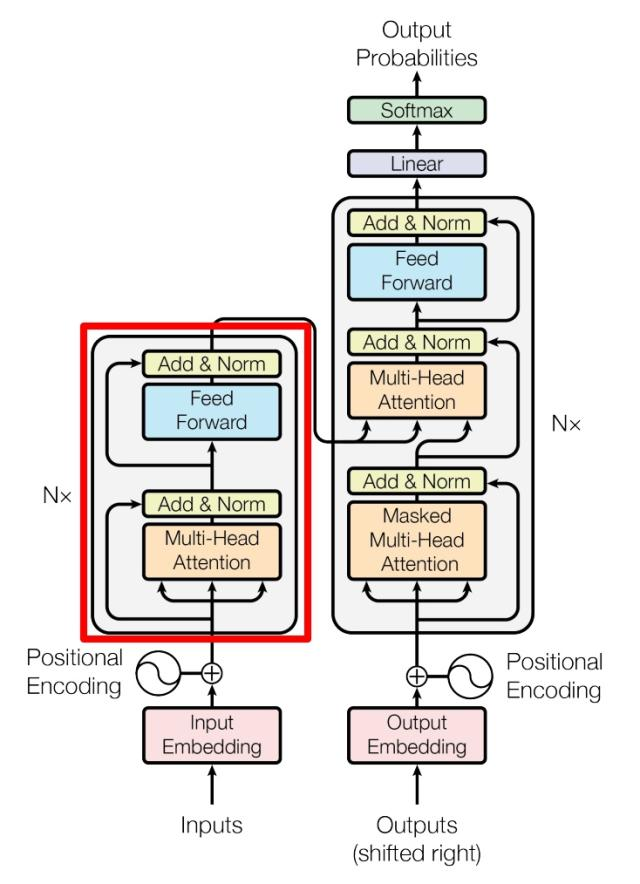
上图红色部分是 Transformer 的 Encoder block 结构,可以看到是由 Multi-Head Attention, Add & Norm, Feed Forward, Add & Norm 组成的。刚刚已经了解了 Multi-Head Attention 的计算过程,现在了解一下 Add & Norm 和 Feed Forward 部分。
Add & Norm
该部分的计算公式如下

两个向量相加其实也被叫为残差连接,在深度神经网络中,随着网络的加深,可能会遇到 梯度消失 或 梯度爆炸 问题,使得训练变得困难。为了避免这种情况,残差连接 提供了一条直接的路径,使得网络中的信息可以更容易地向前传播(即通过每一层),同时也更容易向后传播(即通过反向传播更新梯度)。
通过加上 X(即原始输入),模型不仅可以学习到来自当前层的信息,还可以保留和传递输入层的部分信息。这有助于解决深层网络的训练问题,并且使得模型能够更快地学习。
Layer Normalization的公式如下,它会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
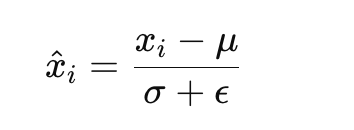
其中:
μ是输入向量 x的均值。
σ^2是输入向量的方差。
ϵ是一个小常数,用于防止除零错误,通常设定为10^{-6}。
\hat{x}_i是归一化后的每个元素。
它有以下的作用:
梯度消失和梯度爆炸问题:在训练深层神经网络时,由于网络层数很深,梯度在反向传播过程中可能会消失或爆炸,导致训练不稳定。Layer Normalization 有助于缓解这个问题,通过对每个样本进行归一化来保证每一层的激活分布稳定,从而改善训练稳定性。
加速收敛:归一化可以使得网络的训练更加平稳,避免了不同层次的激活值在训练中波动过大,从而加速了训练过程。
避免内部协变量偏移(Internal Covariate Shift):在神经网络训练过程中,由于层之间参数的变化,会导致每一层的输入分布发生变化,导致训练变得不稳定。Layer Normalization 通过归一化层输入,减少了这种变化,从而使训练过程更加稳定。
Feed Forward
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下。
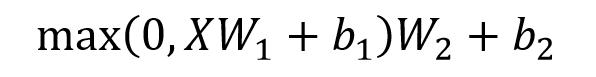
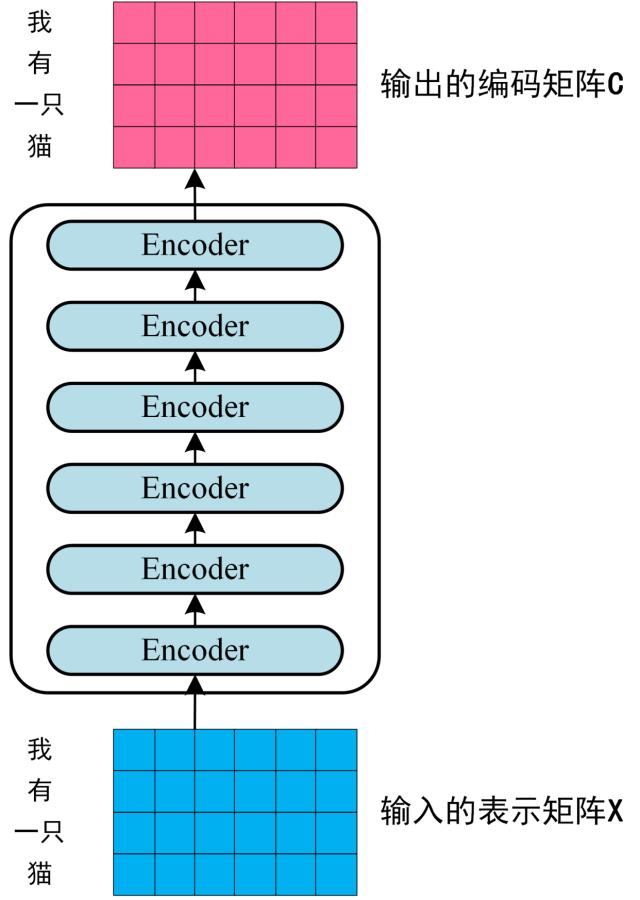
组成Encorder
通过上面描述的 Multi-Head Attention, Feed Forward, Add & Norm 就可以构造出一个 Encoder block,多个Encoder block 叠加就可以组成 Encoder。
第一个 Encoder block 的输入为句子单词的表示向量矩阵,后续 Encoder block 的输入是前一个 Encoder block 的输出,最后一个 Encoder block 输出的矩阵就是编码信息矩阵 C,这一矩阵后续会用到 Decoder 中。
Decoder
图红色部分为 Transformer 的 Decoder block 结构,与 Encoder block 相似,但是存在一些区别:
包含两个 Multi-Head Attention 层。
第一个 Multi-Head Attention 层采用了 Masked 操作。
第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
最后有一个 Softmax 层计算下一个翻译单词的概率。
注意:Self-attention 中的 W_Q, W_K, W_V 矩阵 是共享的,即每个 attention 头在每个解码器子层都使用相同的矩阵。
Masked Multi-Head Attention
其主要是为了将输入盖住,防止在训练过程中模型提前看到后面要预测的单词
第一步:是 Decoder 的输入矩阵和 Mask 矩阵
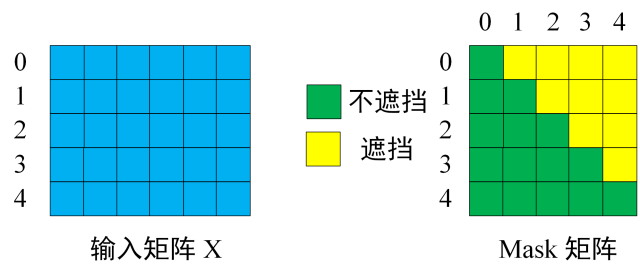
第二步:接下来的操作和之前的 Self-Attention 一样,通过输入矩阵X计算得到Q,K,V矩阵。然后计算Q和 K^T 的乘积 QK^T 。
第三步:在得到 QKT 之后需要进行 Softmax,计算 attention score,我们在 Softmax 之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作其实就是直接和Mask 矩阵直接按位相乘:
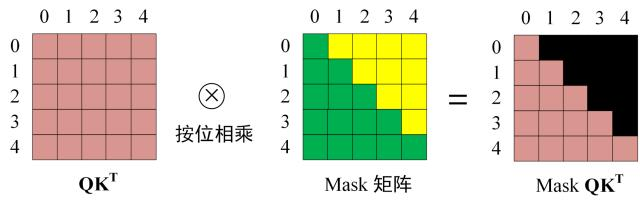
得到 Mask QK^T 之后在 Mask QK^T上进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0。
第四步:使用 Mask QK^T与矩阵 V相乘,得到输出 Z,则单词 1 的输出向量 Z1 是只包含单词 1 信息的。
第五步:通过上述步骤就可以得到一个 Mask Self-Attention 的输出矩阵 Zi ,然后和 Encoder 类似,通过 Multi-Head Attention 拼接多个输出Zi 然后计算得到第一个 Multi-Head Attention 的输出Z,Z与输入X维度一样。
第二个Multi-Head Attention
其主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。
根据 Encoder 的输出 C计算得到 K, V,根据**上一个 Decoder block 的输出 Z 计算 Q (如果是第一个 Decoder block 则使用输入矩阵 X 进行计算)**,后续的计算方法与之前描述的一致。
这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。
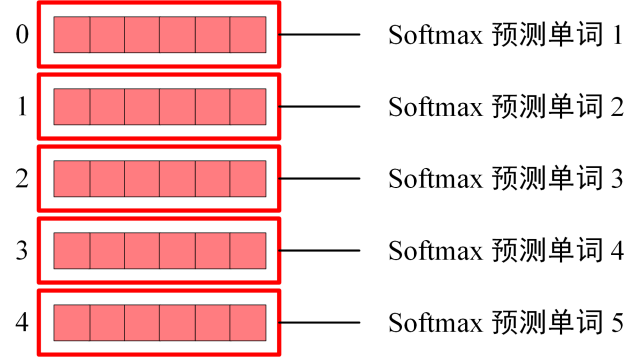
Softmax输出
经过多层的Decoder block 后,会利用 Softmax 预测下一个单词,在之前的网络层我们可以得到一个最终的输出 Z,因为 Mask 的存在,使得单词 0 的输出 Z0 只包含单词 0 的信息,如下:
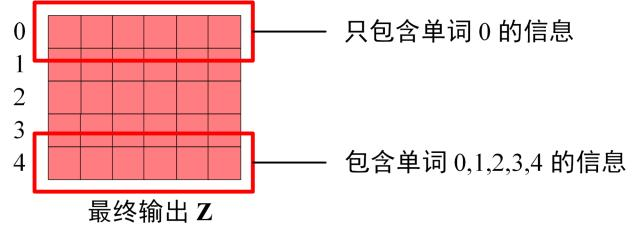
Softmax 根据输出矩阵的每一行预测下一个单词: