Transformer 中Decoder-only、Encoder-only、Decoder-encoder架构区别
不同架构的特点
Encoder-Decoder 模型
特点:包含编码器和解码器两个部分。编码器处理输入序列,生成上下文向量;解码器则根据编码器的输出生成目标序列。这个结构能够同时处理输入和输出序列的关联。
典型模型:T5(Text-to-Text Transfer Transformer) 、BART
应用:序列到序列任务,如机器翻译、摘要生成。
Encoder-only 模型
特点: Encoder-only 模型只使用编码器部分。编码器的核心是处理输入序列,并生成该序列的上下文向量(即隐藏状态),它能够很好地捕捉输入序列的全局信息,对输入进行深度理解。
典型模型:BERT
应用:自然语言理解(NLU)任务,如文本分类、命名实体识别。
局限性:无法直接用于生成任务。
Decoder-only 模型
特点:以自回归方式,基于先前生成的词预测下一个词。
典型模型:GPT
应用:自然语言生成(NLG)任务,如文本生成、对话系统。
优势:能够同时处理理解和生成任务。
为什么现在的LLM都是Decoder only的架构?
目前主要的几种架构有:
以BERT为代表的encoder-only
以T5和BART为代表的encoder-decoder
以GPT为代表的decoder-only
还有以UNILM为代表的PrefixLM(相比于GPT只改了attention mask,前缀部分是双向,后面要生成的部分是单向的causal mask),可以用这张图辅助记忆:
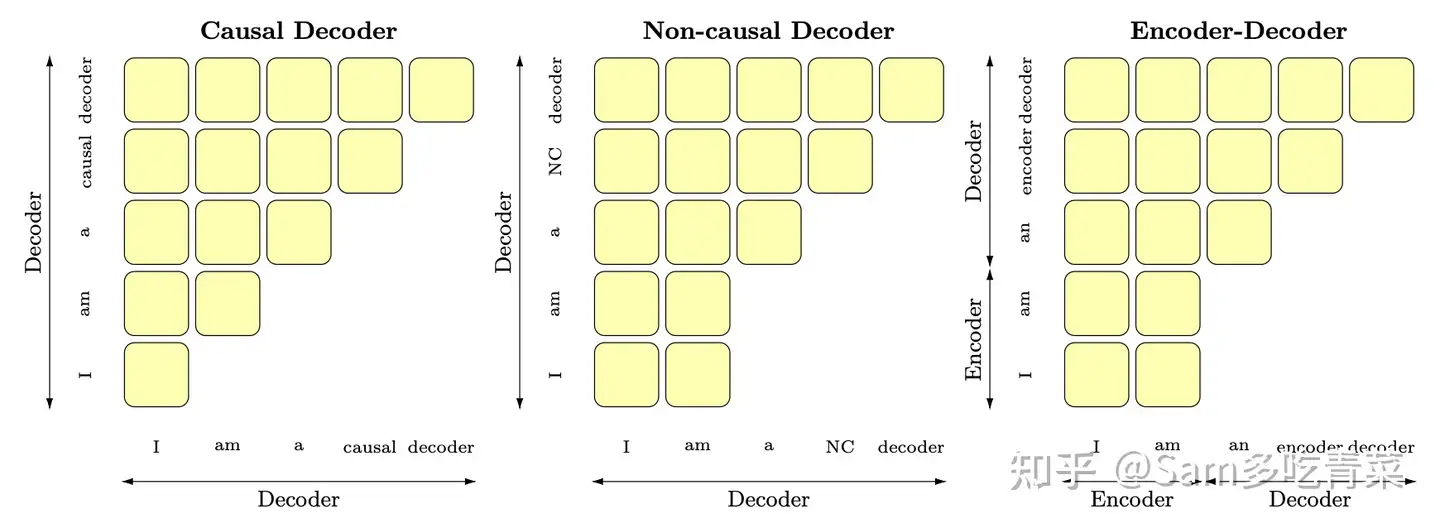
Encoder-only的缺点
首先淘汰掉BERT这种encoder-only,因为它用masked language modeling预训练,不擅长做生成任务,做NLU一般也需要有监督的下游数据微调;相比之下,decoder-only的模型用next token prediction预训练,兼顾理解和生成,在各种下游任务上的zero-shot和few-shot泛化性能都很好。
引入了部分双向attention的encoder-decoder和Prefix-LM的相比于Decoder-only的缺点
虽然它们也能兼顾理解和生成,泛化性能也不错,但是这部分设计往往没有被大部分大模型工作采用。而主要是采用了decoder-only设计。原因在于
Decoder-only泛化性能更好。过去有实验表明用next token prediction预训练的decoder-only模型在各种下游任务上zero-shot泛化性能最好;另外,许多工作表明decoder-only模型的few-shot(也就是上下文学习,in-context learning)泛化能力更强。
Decoder-only泛化性能更好的原因:
注意力满秩问题:双向attention的注意力矩阵容易退化为低秩状态,而causal attention的注意力矩阵是下三角矩阵,必然是满秩的,建模能力更强;
预训练难度问题:纯粹的decoder-only架构+next token predicition预训练,每个位置所能接触的信息比其他架构少,要预测下一个token难度更高,当模型足够大,数据足够多的时候,decoder-only模型学习通用表征的上限更高;
上下文学习为decoder-only架构带来的更好的few-shot性能:prompt和demonstration的信息可以视为对模型参数的隐式微调[2],decoder-only的架构相比encoder-decoder在in-context learning上会更有优势,因为prompt可以更加直接地作用于decoder每一层的参数,微调的信号更强;
隐式位置编码:causal attention (就是decoder-only的单向attention)具有隐式的位置编码功能 [3],它打破了transformer的位置不变性,而带有双向attention的模型,如果不带位置编码,双向attention的部分token可以对换也不改变表示,对语序的区分能力天生较弱。
效率问题:decoder-only支持一直复用KV-Cache,对多轮对话更友好,因为每个token的表示只和它之前的输入有关,而encoder-decoder和PrefixLM就难以做到;
轨迹依赖问题:OpenAI作为开拓者勇于挖坑踩坑,以decoder-only架构为基础摸索出了一套行之有效的训练方法和Scaling Law,后来者鉴于时间和计算成本,自然不愿意做太多结构上的大改动,继续沿用decoder-only架构。在工程生态上,decoder-only架构也形成了先发优势,Megatron和flash attention等重要工具对causal attention的支持更好。
参考资料
- 为什么现在的LLM都是Decoder only的架构?https://www.zhihu.com/question/588325646