大模型 kvcache 浅析
需要清楚知道它的限制,即限制在:
推理阶段
decoder-only架构,单向注意力
推理回顾
假设模型最终生成了“遥遥领先”4个字。
当模型生成第一个“遥”字时,input=”<s>”, “<s>”是起始字符。Attention的计算如下:
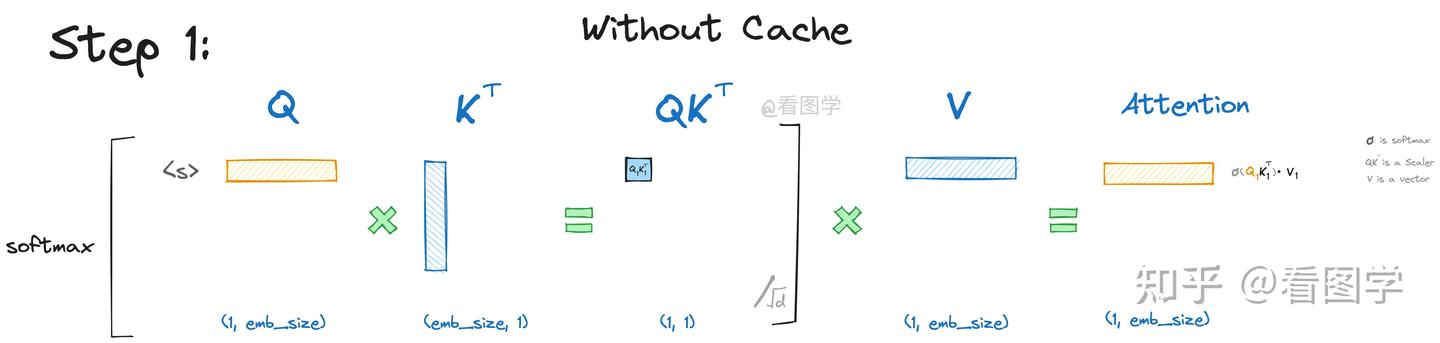
为了看上去方便,我们暂时忽略scale项根号d, 但是要注意这个scale面试时经常考。
如上图所示,最终Attention的计算公式如下,(softmaxed 表示已经按行进行了softmax):
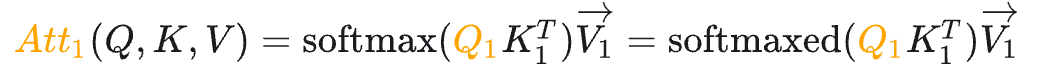
以此类推生成第四个字的时候如下:
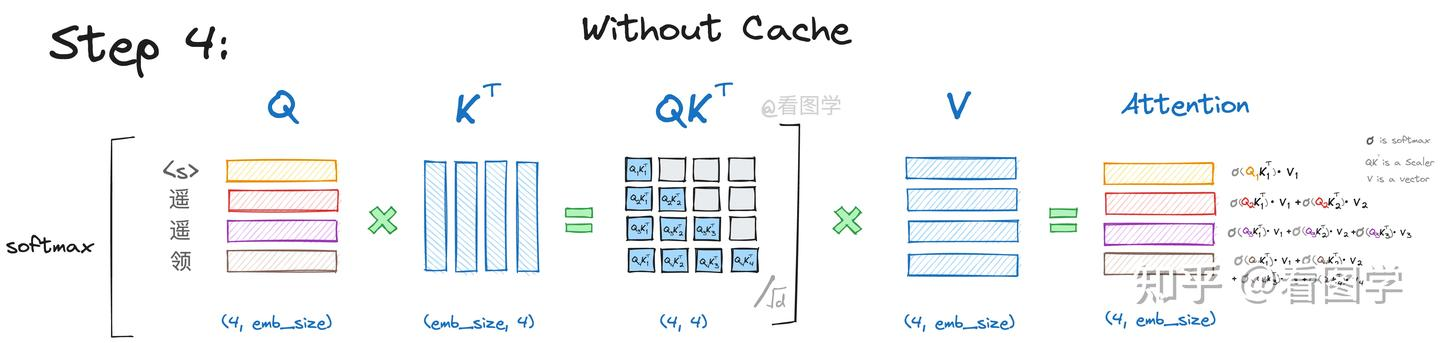
公式为:
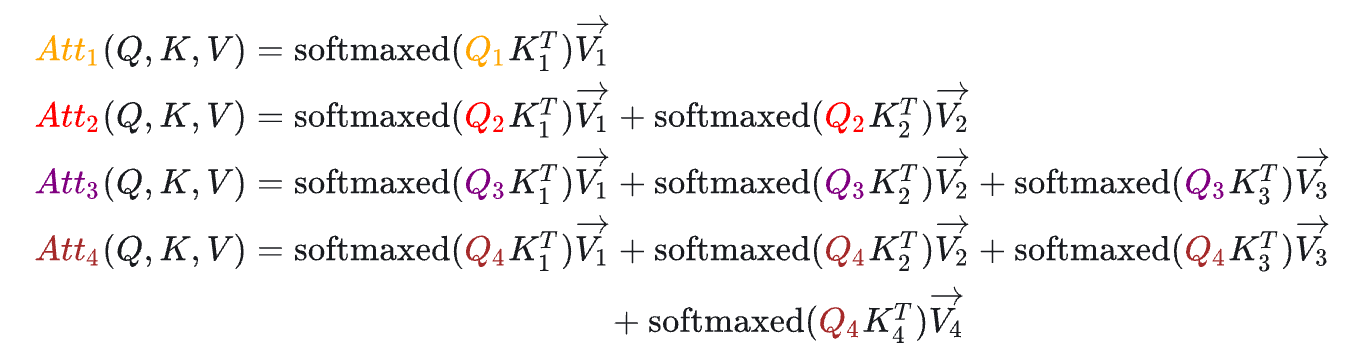
需要注意的一点在于QK^T这个矩阵的长宽都等于历史字符的数量,随着对话轮数的增加,这部分空间暂用是十分恐怖的
KV Cache
这里有一个特点,如果是对于一般的自回归系统,我们在生成下一个字的时候往往需要参考过去所有的字,但是实际上因为mask的存在,我们的Attention_4只需要拿当前新增字符的Q与过去生成的字符(也包括自己)的K、V相乘就可得到,所以我们可以将过去的K、V进行缓存以进行更高速的计算
下图展示了使用KV Cache和不使用的对比
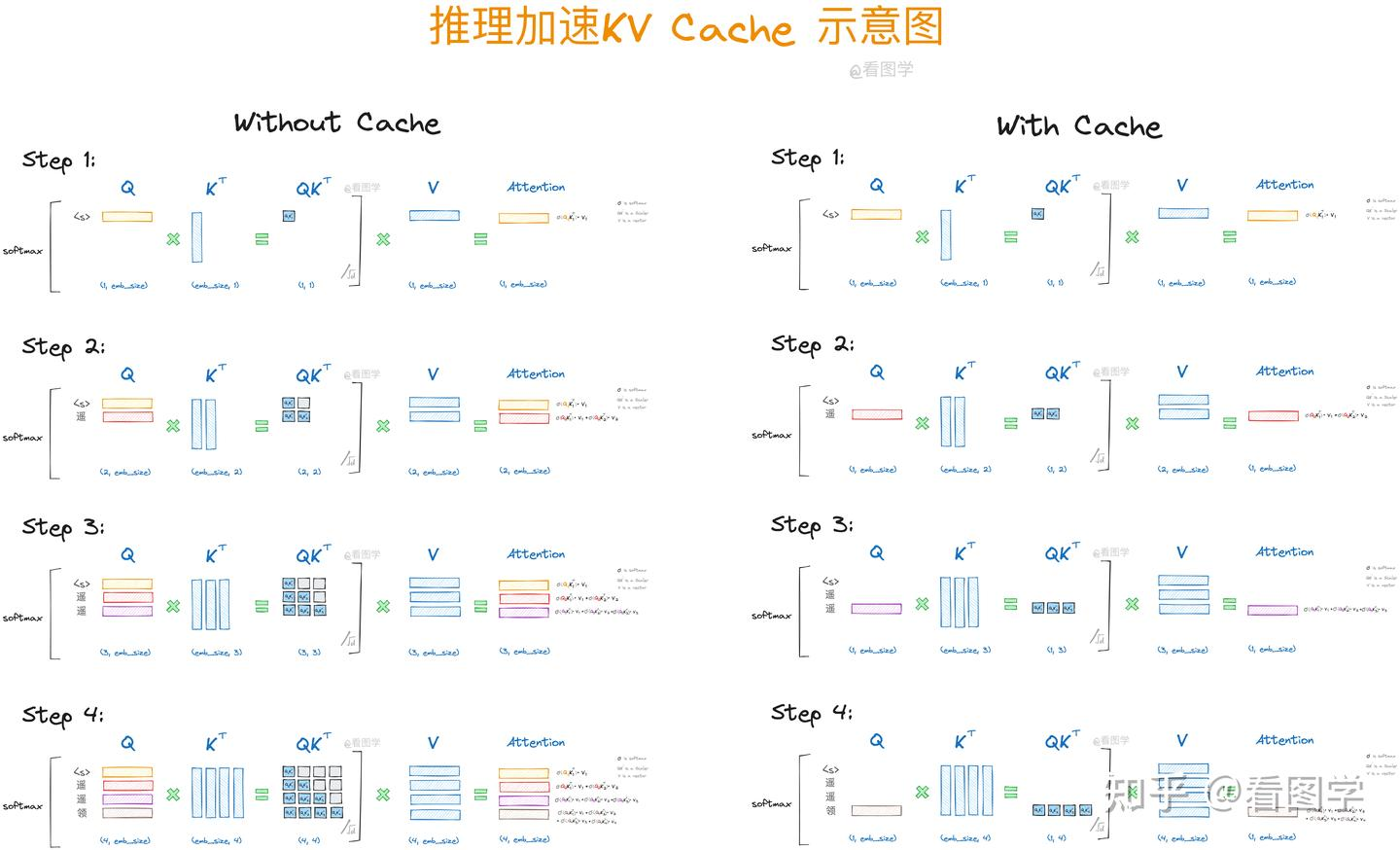
而在实际实现时的做法就较为简单了,直接和缓存起来的过去key和value与新生成的字符的key和value拼接就可以得到新的key和value。
1 | |
显存代价
KV cache实际上可以认为是一种以空间换时间的操作,其内存消耗为:
$$2 \times batch \times context_length \times n_layers \times n_head \times d_heads \times Pa$$
2代表是k与v两类缓存**
batch**:批量大小(batch size),表示一次训练或推理过程中输入的样本数量。**
context_length**:上下文长度,也就是输入序列的长度。在语言模型中,通常对应于文本的词数或标记的数量。**
n_layers**:模型的层数,即 Transformer 模型中的层数,各个层有自己独立的K、V。例如,BERT 或 GPT 中的层数。**
n_heads**:注意力头的数量。在多头注意力机制中,模型会将注意力计算分为多个头,每个头独立地进行计算,最后将结果合并。**
d_heads**:每个注意力头的维度。在多头注意力中,每个头计算的key和value的维度,通常是整个模型的嵌入维度(如hidden_size)除以n_heads。**
Pa**:一个常数,用于表示每个key和value向量的每个元素占用的内存量(如浮点数的字节数)。通常,如果是 32 位浮点数,则为 4 字节;如果是 16 位浮点数,则为 2 字节。
以一个batch_size=32, context_length=2048, n_layer=32, n_head=32, d_head=128, float32类型,则需要占用的显存为: 2 * 32 * 2048 * 32 * 32 * 4096 * 4 / 1024/1024/1024 = 64G。
优化速度
有过一些实验,对于hugging face等推理库:
使用kvcache耗时11s
不使用kvcache耗时56s
参考资料
大模型推理加速:看图学KV Cache:https://zhuanlan.zhihu.com/p/662498827
大模型推理性能优化之KV Cache解读: https://zhuanlan.zhihu.com/p/630832593
【8】KV Cache 原理讲解: https://www.bilibili.com/video/BV17CPkeEEzk/?spm\_id\_from=333.337.search-card.all.click\&vd\_source=cd12a18b61f61365725f1704677a6b74