大模型显存占用浅析
基础知识
浮点数
对于大模型常说的1B、7B中的B指的是Billion,即十亿参数,然后还需考虑模型采用什么位数来存储,常见的表示类型如下:
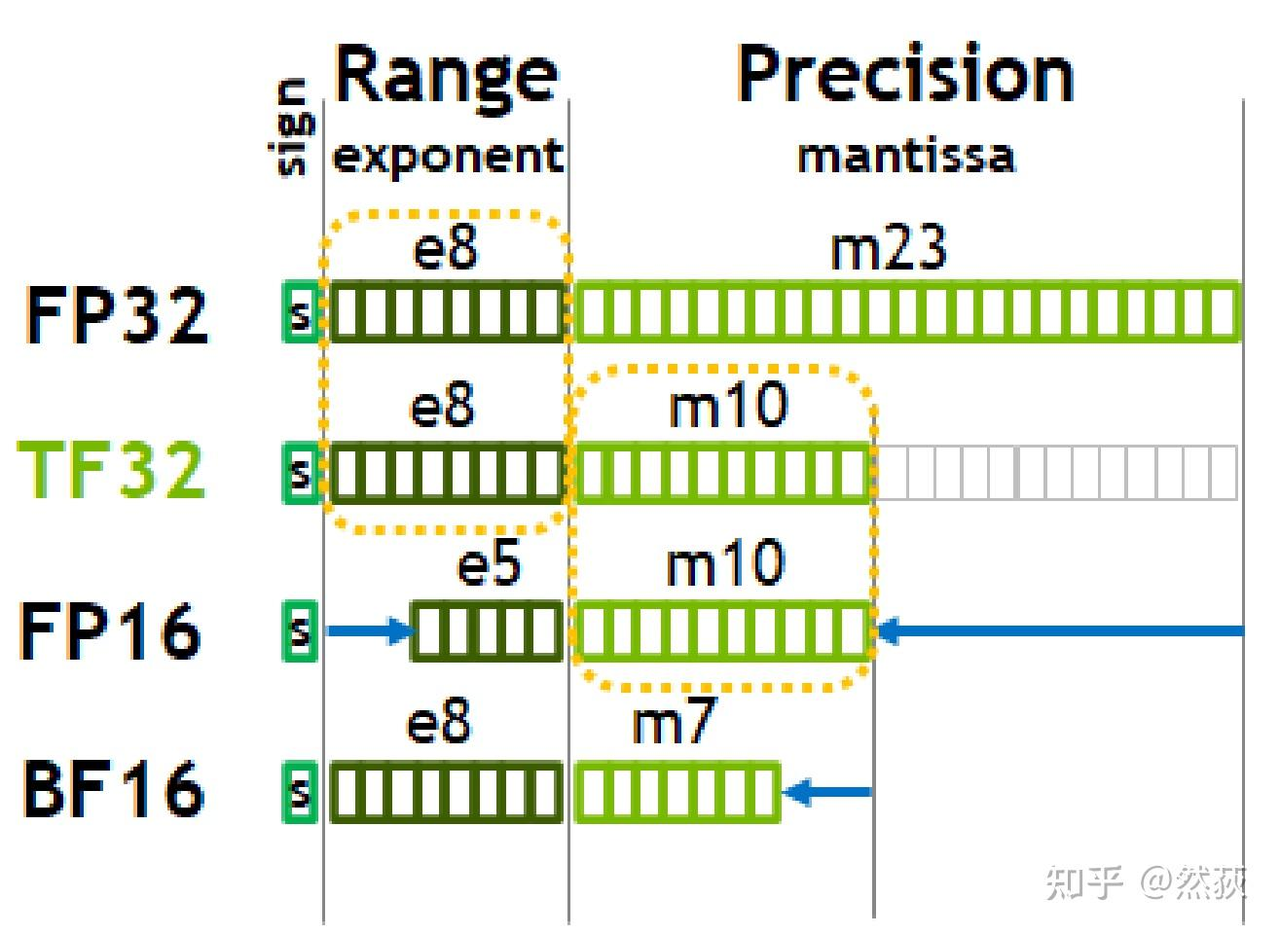
可以非常直观地看到,浮点数主要是由符号位(sign)、指数位(exponent)和小数位(mantissa)三部分组成。 符号位都是1位(0表示正,1表示负),指数位影响浮点数范围,小数位影响精度。 其中TF32并不是有32bit,只有19bit不要记错了。BF16指的是Brain Float 16,由Google Brain团队提出。
而对于上述的计数方式,以BF16为例,从下面这一个例子来表示具体是如何计数的:

其计算规则如下:
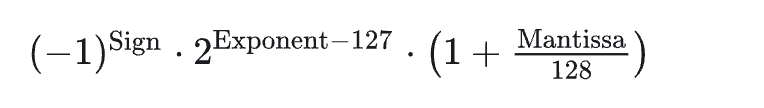
符号位Sign = 1,代表是负数
指数位Exponent = 17,中间一坨是 2^(−110)
小数位Mantissa = 3,后面那一坨是 1+3/128
最终结果,三个部分乘起来就是最终结果 -8.004646331359449e-34
1Byte=8bit,以fp32为例,1个fp32的参数就是32/8=4Bytes,故而对于1B的fp32的模型,其占用的显存为4 Billion bytes ,而1GB约等于10^9,即1 Billion,故模型的显存占用约为4GB。
显存占用类型
而在大模型训练过程中,显存主要被以下几个部分占用:
模型权重
优化器状态
梯度
激活值
临时缓冲区
不同的训练阶段(如SFT、RLHF)对显存的需求也有所不同。
混合精度训练
介绍
在进行大模型训练时,往往采取的是混合精度训练(MIXED PRECISION TRAINING)
混合精度训练是在尽可能减少精度损失的情况下利用半精度浮点数加速训练。它使用FP16即半精度浮点数存储权重和梯度。在减少占用内存的同时起到了加速训练的效果。
整体过程如下所示:
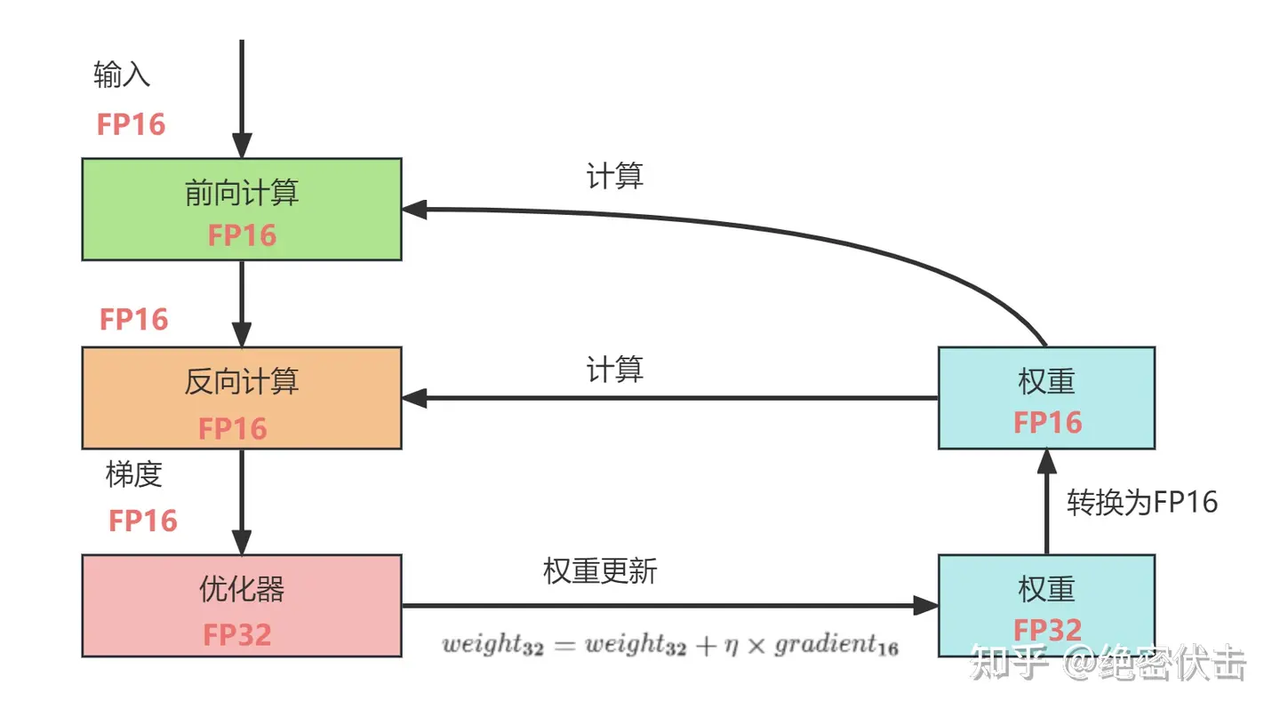
从图中可以看出,在计算过程中所产生的权重,激活值,梯度等均使用 FP16 来进行存储和计算,其中权重使用FP32额外进行备份。这样做的原因是,在更新权重公式为如下形式。
对于优化器和权重采用fp32是因为在深度模型中,学习率×梯度的参数值可能会非常小,如果利用FP16来进行相加的话,则很可能会出现舍入误差问题,导致更新无效。因此通过将权重拷贝成FP32格式,并且确保整个更新过程是在FP32格式下进行的。
注意虽然这样子会导致我们需要一个额外的FP16的模型权重,但是由实际上额外拷贝一份权重只增加了训练时候静态内存的占用。而在训练过程中内存中分为动态内存和静态内容,其中动态内存是静态内存的3-4倍,主要是中间变量值和激活值。只要动态内存的值基本都是使用FP16来进行存储,则最终模型与整网使用FP32进行训练相比起来,内存占用也基本能够减半。
Loss-scaling
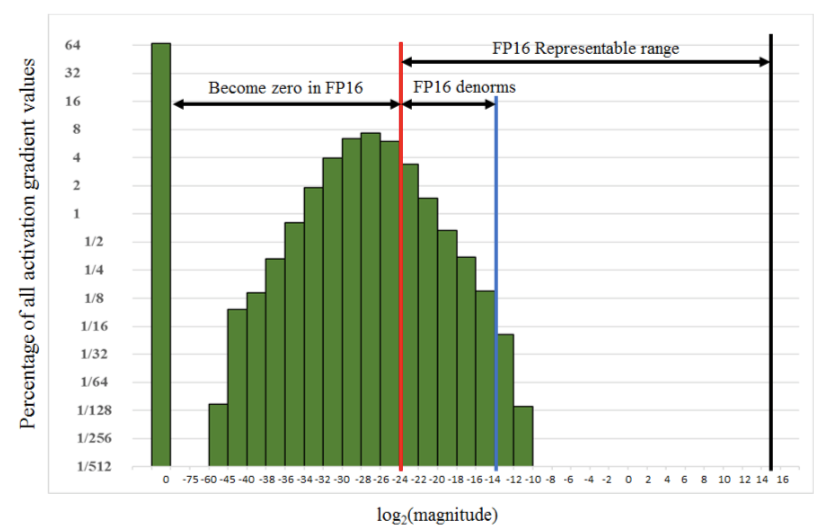
得到FP32的loss后,放大并保存为FP16格式,进行反向传播,更新时转为FP32缩放回来。下图可以看到,很多激活值比较小,无法用FP16表示。因此在前向传播后对loss进行扩大(固定值或动态值),这样在反响传播时所有的值也都扩大了相同的倍数。在更新FP32的权重之前unscale回去。
显存计算
对于llama3.1 8B模型,FP32和BF16混合精度训练,用的是AdamW优化器,请问模型训练时占用显存大概为多少?
解:
模型参数:16(BF16) + 32(PF32)= 48G
梯度参数:16(BF16)= 16G
Adam优化器参数:32(PF32) + 32(PF32)= 64G
不考虑激活值的情况下,总显存大约占用 (48 + 16 + 64) = 128G
参考资料
一文讲明白大模型显存占用(只考虑单卡):https://zhuanlan.zhihu.com/p/713256008
【通俗易读】LLM训练-从显存占用分析到DeepSpeed ZeRO 三阶段解读https://zhuanlan.zhihu.com/p/694880795