preprocessed = [ item.strip() for item in preprocessed if item.strip() ] ids = [self.str_to_int[s] for s in preprocessed] return ids
defdecode(self, ids): text = " ".join([self.int_to_str[i] for i in ids]) # Replace spaces before the specified punctuations text = re.sub(r'\s+([,.?!"()\'])', r'\1', text) return text
classSimpleTokenizerV2: def__init__(self, vocab): self.str_to_int = vocab self.int_to_str = { i:s for s,i in vocab.items()}
defencode(self, text): preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text) preprocessed = [item.strip() for item in preprocessed if item.strip()] preprocessed = [ item if item in self.str_to_int else"<|unk|>"for item in preprocessed ]
ids = [self.str_to_int[s] for s in preprocessed] return ids
defdecode(self, ids): text = " ".join([self.int_to_str[i] for i in ids]) # Replace spaces before the specified punctuations text = re.sub(r'\s+([,.:;?!"()\'])', r'\1', text) return text
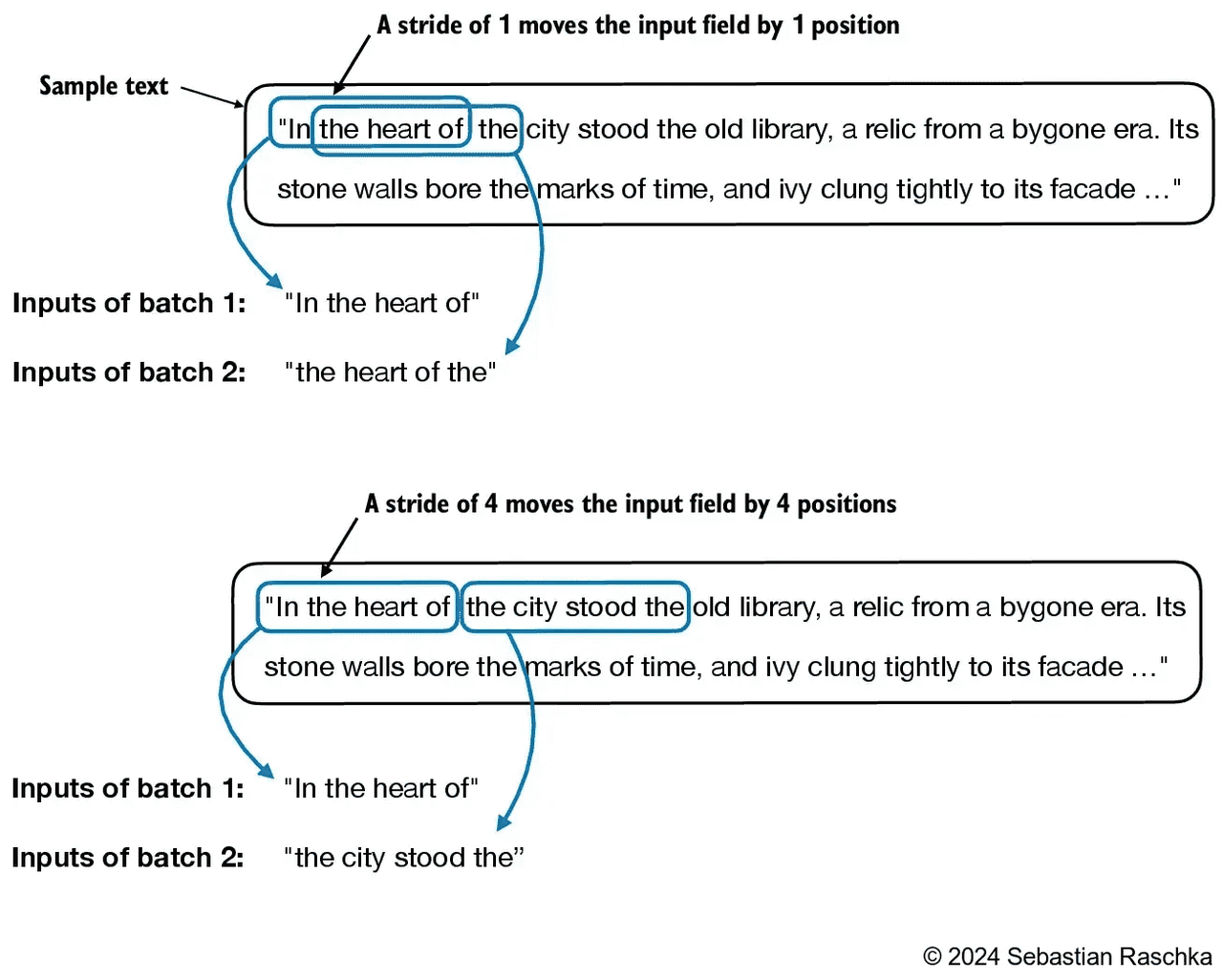
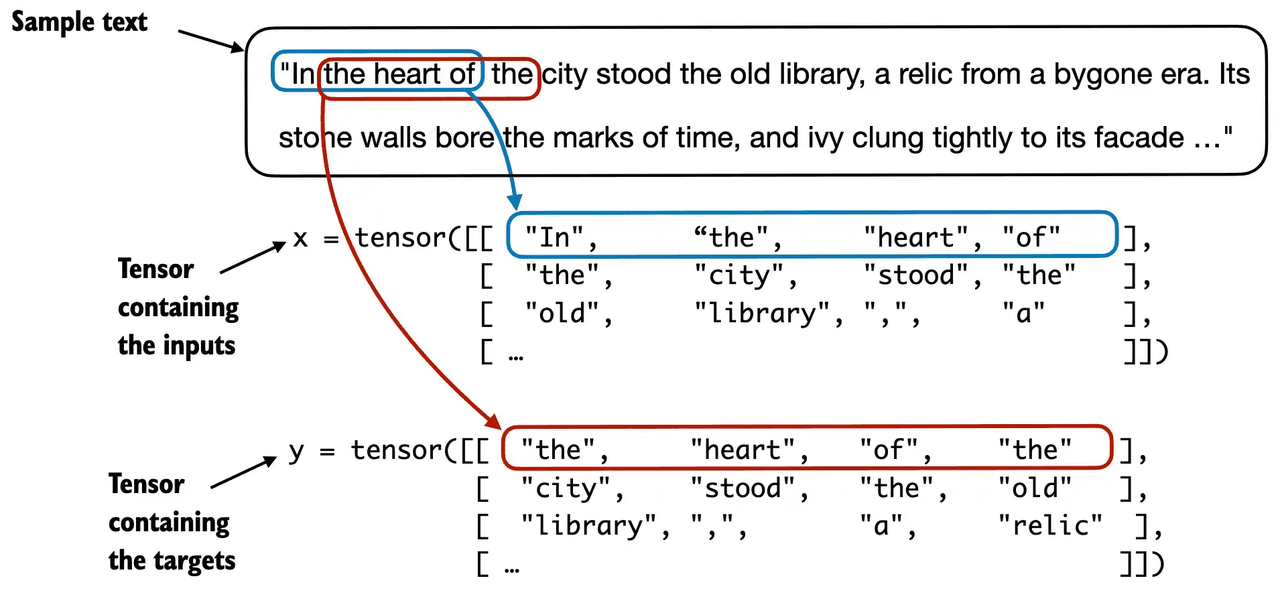
# Tokenize the entire text token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"}) assertlen(token_ids) > max_length, "Number of tokenized inputs must at least be equal to max_length+1"
# Use a sliding window to chunk the book into overlapping sequences of max_length for i inrange(0, len(token_ids) - max_length, stride): input_chunk = token_ids[i:i + max_length] target_chunk = token_ids[i + 1: i + max_length + 1] self.input_ids.append(torch.tensor(input_chunk)) self.target_ids.append(torch.tensor(target_chunk))