【从零构建大模型】二、编码Attention机制
概览
构建大模型的全景图如下,本文介绍了基础的attention处理。
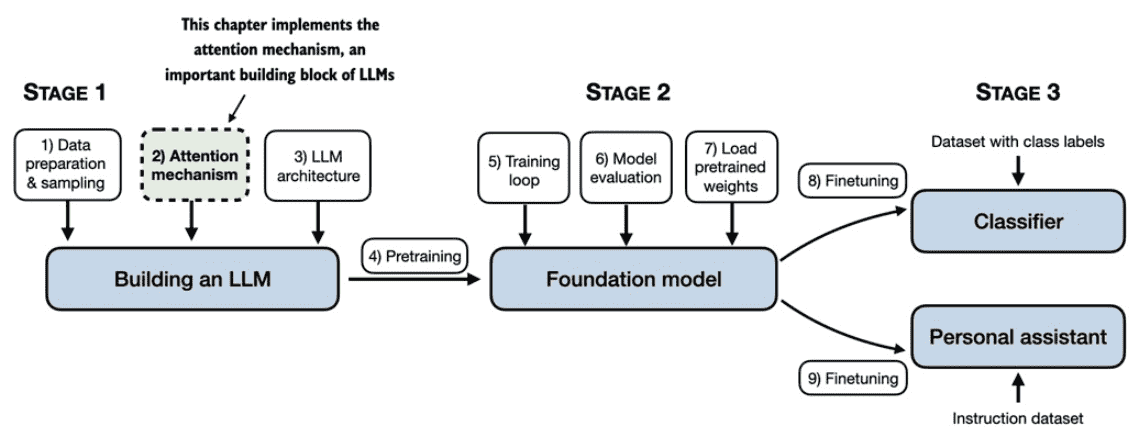
介绍的脉络如下:
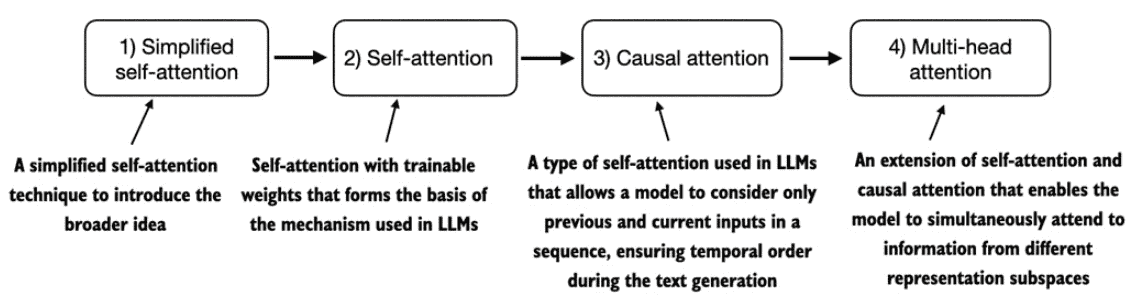
介绍
The problem with modeling long sequences
对于类似翻译的任务,由于不同语言的语法问题,所以难以做到一对一的逐字翻译,需要提前对原本的字符串进行encoder提取信息,然后使用decoder模块进行翻译。
而传统的encoder-decoder RNNs方法在encoder阶段无法从编码器访问先前的隐藏状态。因此,它只能依赖于当前隐藏状态,而当前隐藏状态包含了所有相关信息。这可能会导致上下文丢失,尤其是在依赖关系可能跨越很长距离的复杂句子中。
所以提出了注意力机制来更好地捕获原本的信息。
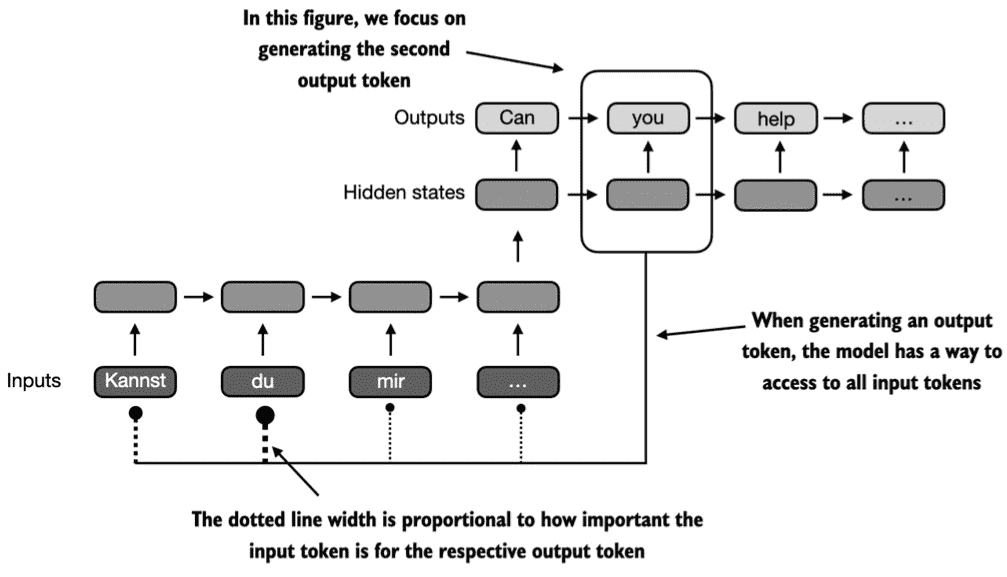
Capturing data dependencies with attention mechanisms
在注意力机制中,encoder可以选择性地访问所有输入的tokens,并自行判断哪些tokens更加重要,而这部分判断就是依靠attention weights。
Self attention是transfomer中的关键的一种机制,它允许输入序列中的每个位置在计算序列的表示时关注同一序列中的所有位置。自注意力机制是基于 Transformer 架构的当代LLM的关键组成部分,例如 GPT 系列。下面我们将从头开始编写这种自注意力机制的代码
Attending to different parts of the input with self-attention
A simple self-attention mechanism without trainable weights
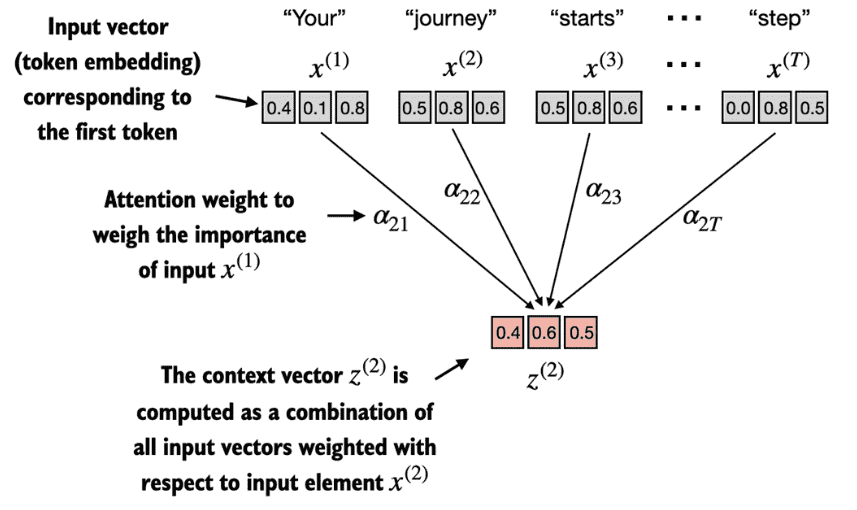
自注意力机制的目标是为每个输入元素计算一个上下文向量,该向量结合了所有其他输入元素的信息。
下图表示了一种简化后的attention机制,我们想要计算得到第2个字符的上下文向量就只需要用attention weights与原序列中的各个token相乘即可。
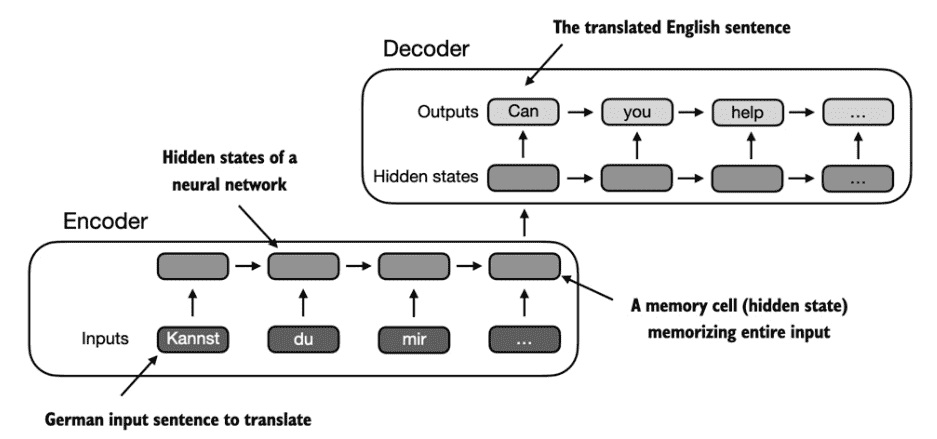
而一个简单的计算两者attention weights的方法就是直接将两者的token embedding进行点积。
点积还是相似性的度量,因为它量化了两个向量的对齐程度:更高的点积表示更大程度的对齐或相似性向量之间。在自注意力机制的背景下,点积决定了序列中元素相互关注的程度:点积越高,两个元素之间的相似度和注意力分数就越高。
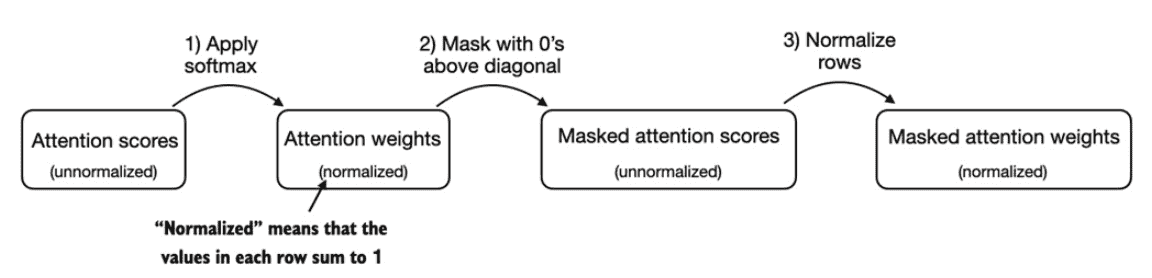
通过点积得到attention weights后往往还会进行归一化,一般采用softmax函数。
最后通过各个token的embeddings与attention weights的加权相乘就可以得到需要的上下文向量。
简单的代码实现如下
1 | |
Computing attention weights for all input tokens
前面说的是单个token如何计算上下文向量, 而在实际过程中可以简单的使用向量处理的方向一次性得到所有的attention weight和上下文向量,代码如下:
1 | |
Implementing self-attention with trainable weights
Computing the attention weights step by step
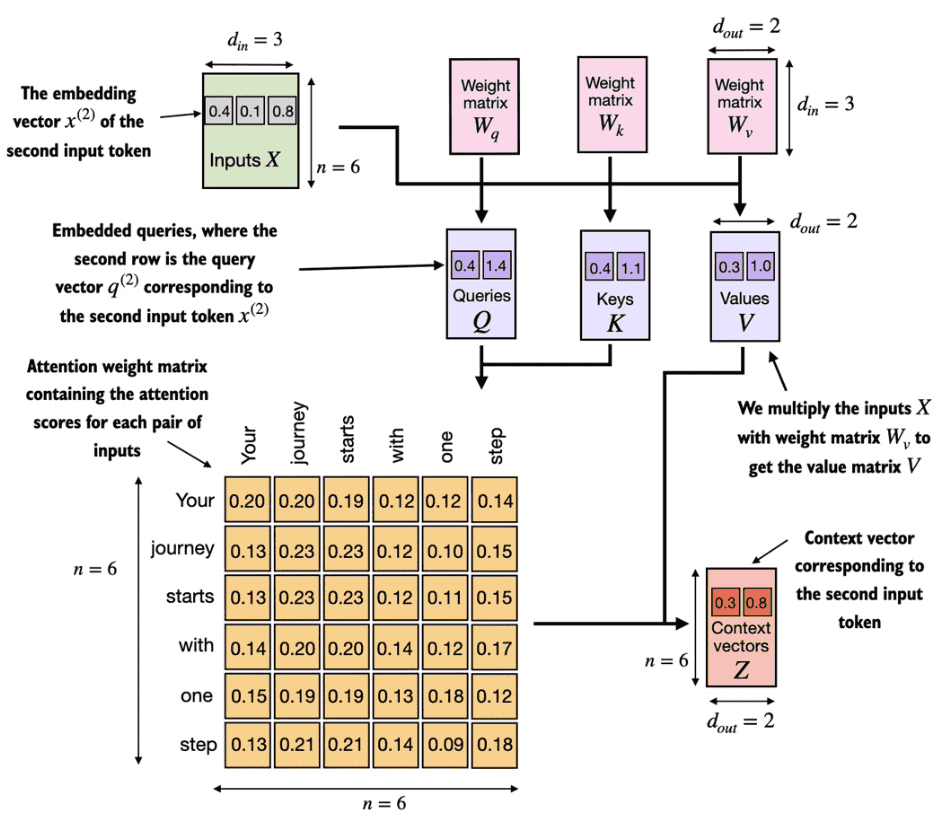
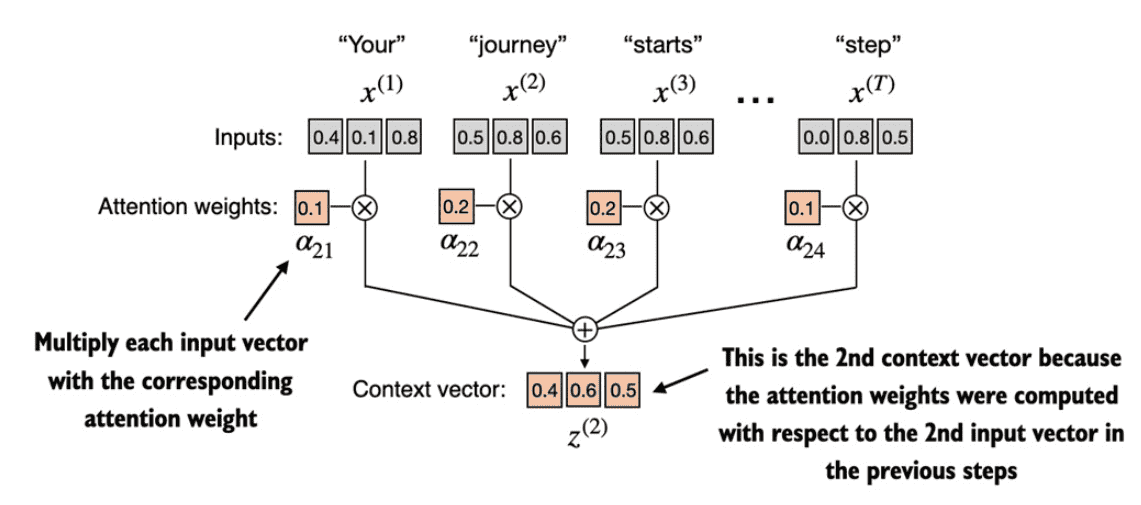
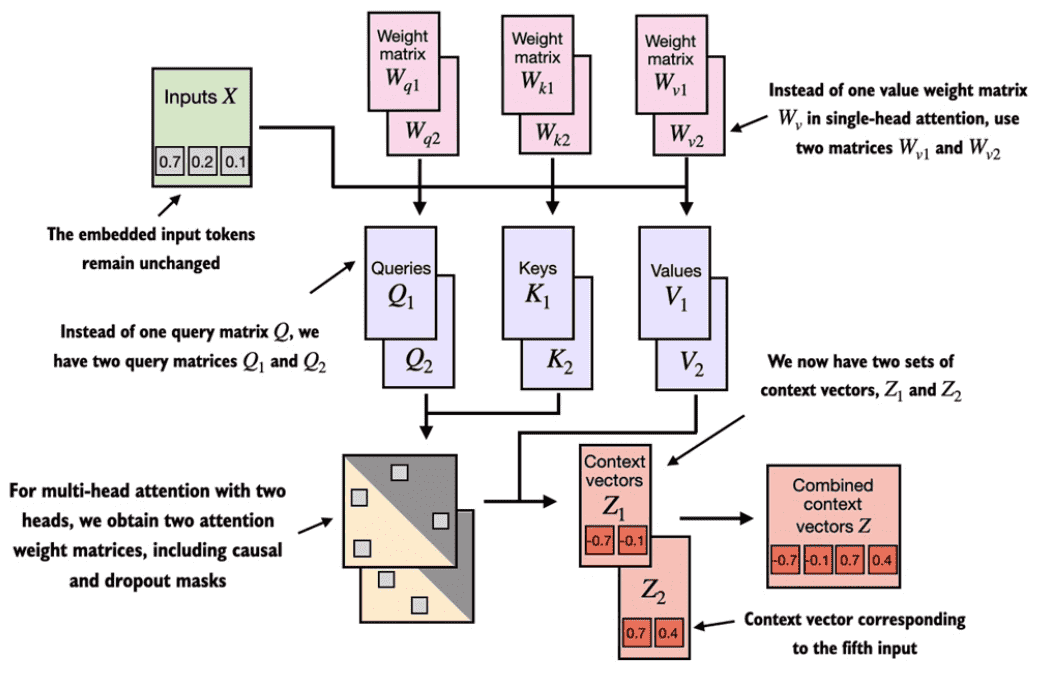
在实际的self-attention中会三个可训练的权重矩阵$$W_q$$,$$W_k$$,$$W_v$$,其分别用于与原token embedding相乘计算Query、Key、Value。下面以d_in=3维度的token以及d_out=2维度的输出来演示如何计算第二token的上下文。
请注意,在类似 GPT 的模型中,输入和输出维度通常相同,但为了便于说明,为了更好地跟踪计算,我们在此选择不同的输入(d_in=3)和输出(d_out=2)维度。
整体流程如下图所示:
各个token与$$W_q$$,$$W_k$$,$$W_v$$相乘的到q、k、v
第二个token的q与各个k相乘的到attention
对attention进行softmax
对attention进行缩放
各个attention与v加权相乘得到上下文向量
为什么在自注意力机制中会用嵌入维度的平方根来缩放点积?
缩放的目的:用嵌入维度的平方根来缩放,是为了避免训练过程中出现过小的梯度。若不做缩放,训练时可能会遇到梯度非常小的情况,导致模型学习变慢,甚至陷入停滞。
出现梯度变小的原因:1、当嵌入维度(即向量的维度)增加时,两个向量的点积值会变大。在GPT等大型语言模型(LLM)中,嵌入维度往往很高,可能达到上千,因此点积也变得很大。 2、在点积结果上应用softmax 函数时,如果数值较大,softmax 输出的概率分布会变得很尖锐,近似于阶跃函数。此时,大部分概率集中在几个值上,导致其他部分的梯度几乎为零。这样就会导致模型训练时更新不充分。
缩放的效果:通过用嵌入维度的平方根缩放点积的大小,可以让点积的数值控制在合理范围,使得softmax 函数的输出更加平滑,从而使得梯度较大,模型可以更有效地学习。这种缩放的自注意力机制因此被称为“缩放点积注意力” (scaled-dot product attention)。
整体的代码如下所示:
1 | |
Implementing a compact SelfAttention class
类似的在实际计算所有的上下文向量的时候都是通过矩阵相乘的方法来做的,如下图所示:
代码如下所示,注意这里使用了nn.Linear,这有助于更稳定、有效的模型训练。:
1 | |
Hiding future words with causal attention
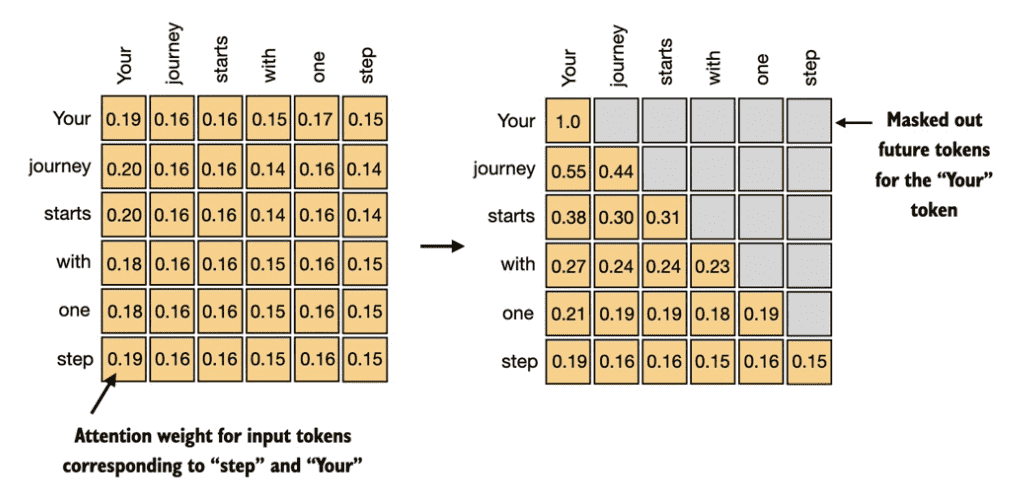
在decoder生成阶段时我们只能看到要生成的token的前面的token,所以需要对生成的attention weight进行mask,这也叫做Causal attention。
Applying a causal attention mask
简单的mask就是在生成了attention weight之后在进行mask,然后再进行归一化。
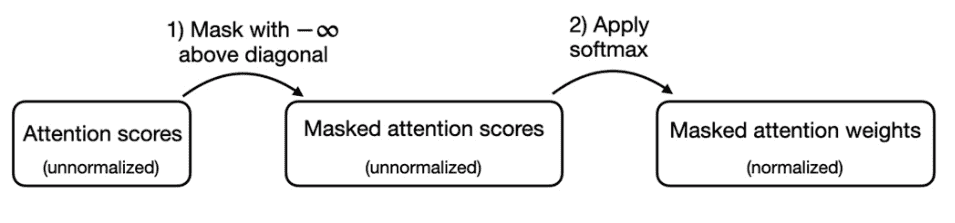
而更常见的方法是利用softmax的数学特性,在q@k得到attention之后直接给要mask的attention weights记为-inf,这样softmax之后其值为0。
代码实现如下:
1 | |
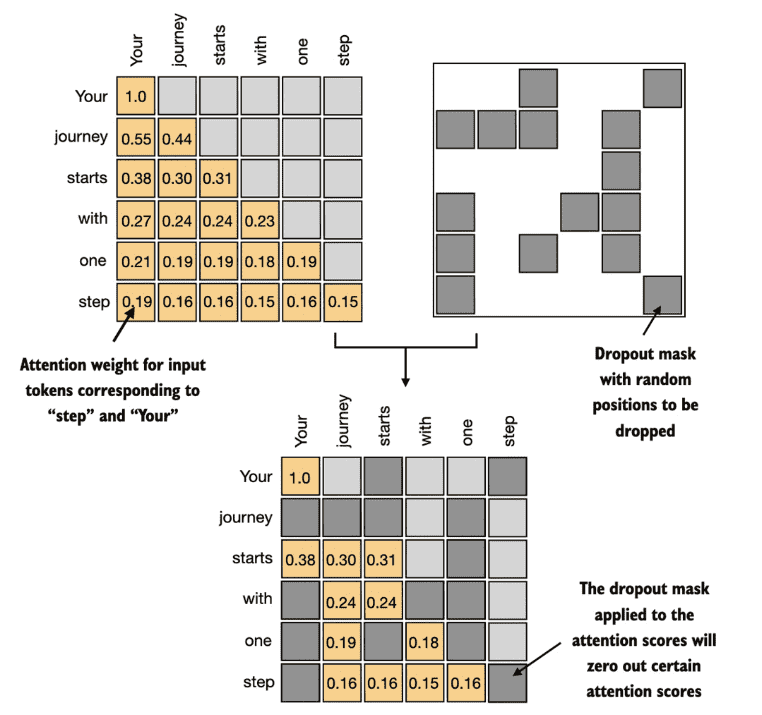
Masking additional attention weights with dropout
此外,我们还应用dropout来减少训练过程中的过拟合,确保模型不会过度依赖任何特定的隐藏层单元集。需要强调的是,Dropout 仅在训练期间使用,训练结束后将被禁用。
可以有两处dropout的地方
在计算完attention weight之后
在attention weight与values相乘之后
一般第一种更加普遍,下图我们以50%的dropout 比例为例来介绍,在实际如GPT模型中往往只会采取10%、20%的比例。
代码如下:
1 | |
Implementing a compact causal self-attention class
将mask和dropout的特性加上后的代码如下:
1 | |
Extending single-head attention to multi-head attention
Stacking multiple single-head attention layers
实际往往会采取多头注意力机制,在分别得到对应的上下文后会将其直接进行拼接,然后一般会再与一个全联接层进行相乘
简单地将上述的代码进行包装就可以得到多头注意力的版本:
1 | |
Implementing multi-head attention with weight splits
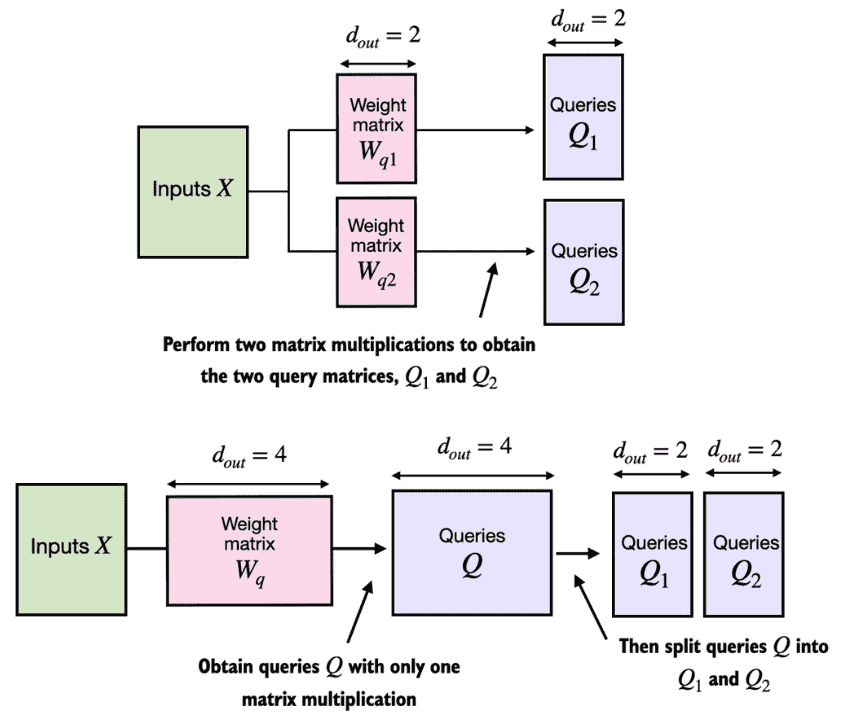
在实际的处理中,为了更好的并行化,其实会作为一个大矩阵来计算多头注意力。例如我们会一次性初始化一个大的Wq,然后通过一次矩阵运算得到Q后再对其进行形状的转化,分割成多个self-attention中的Q。再计算得到attention,再计算得到上下文,最后又通过形状的变化得到拼接后的输出。
1 | |
总结
自注意力机制将上下文向量表示计算为输入的加权和。
在简化的注意力机制中,注意力权重是通过点积计算的。
在LLM中使用的自注意力机制(也称为缩放点积注意力机制)中,我们引入了可训练的权重矩阵来计算输入的中间变换:查询、值和键。当使用从左到右读取和生成文本的LLM时,我们添加了因果注意力掩码,以防止LLM访问未来的token。
除了因果注意力掩码将注意力权重归零之外,我们还可以添加 dropout mask 来减少 LLM 中的过度拟合。
基于 Transformer 的 LLM 中的注意力模块涉及因果注意力的多个实例,这称为多头注意力。
我们可以通过堆叠多个因果注意模块实例来创建多头注意模块。
创建多头注意力模块的更有效方法涉及分批矩阵乘法。