【从零构建大模型】三、从零实现一个 GPT 模型以生成文本
概览
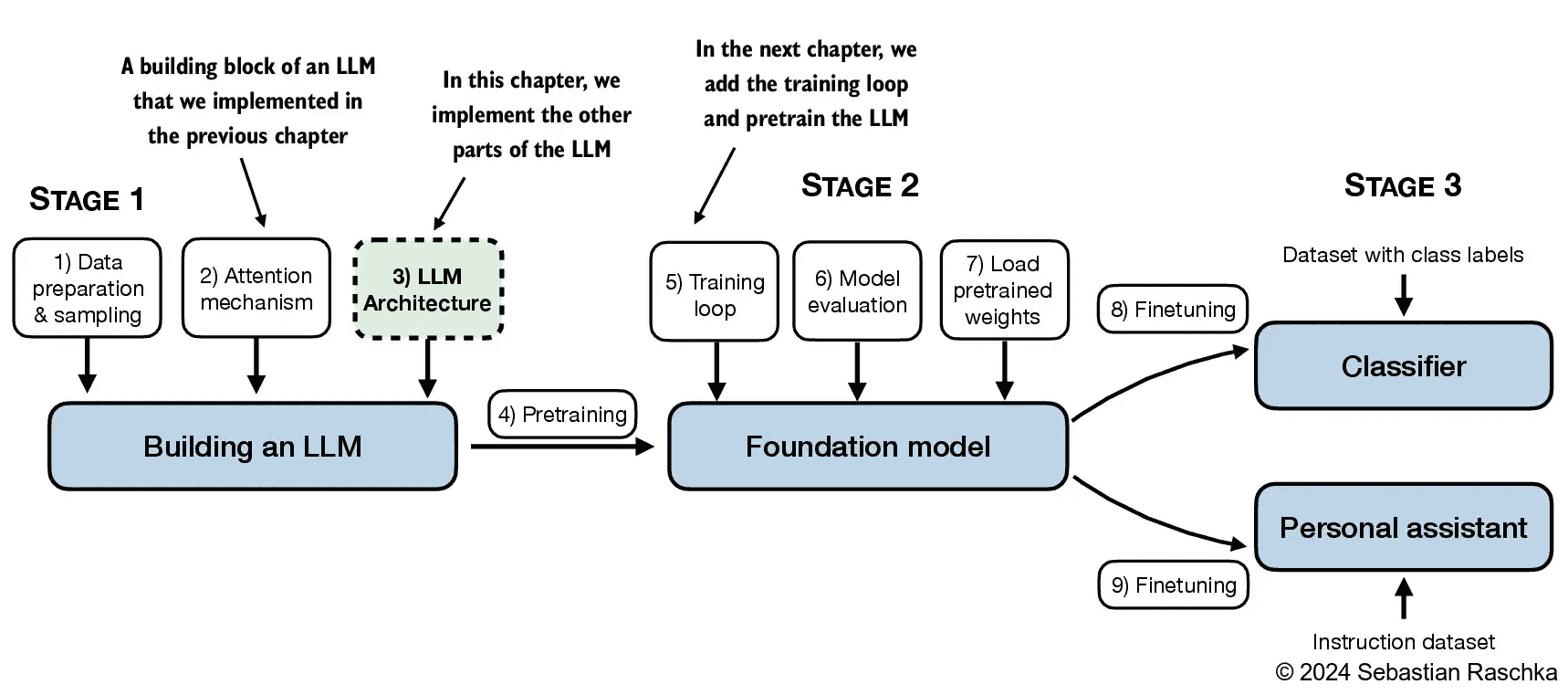
构建大模型的全景图如下,本文介绍了基础GPT-2系列的模型架构。
介绍的脉络如下:
介绍
Coding an LLM architecture
一个参数量为124 million的GPT-2模型包括了以下的定义参数:
1 | |
vocab_size:单词数量,也就是BPE解码器所支持的单词数量
context_length:最长允许输入的token数量,也就是常说的上下文长度
emb_dim:Embedding层的维度
n_heads:多头注意力中注意力头的数量
n_layers:transformer块的数量
drop_rate:为了防止过拟合所采用的丢弃率,0.1意味着丢弃10%
qkv_bias:Liner层是否再加一个bias层
这些参数在初始化GPT模型的时候采用如下的使用方法(一些层还没有介绍,先留白):
1 | |
Normalizing activations with layer normalization
LayerNorm归一化层的作用是将某一个维度中的参数都均值化到0,同时将方差归为1。其处理方法如下:
$$\mu = \frac{1}{N} \sum_{i=1}^{N} x_i$$:均值
$$\sigma^2 = \frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2$$:方差
$$\varepsilon$$:小值,防止除以0
而更灵活一点的实现会再额外添加了一个scale变量以控制各变量x进行缩放,还有shift变量来控制变量x进行平移。
简单使用代码实现,如下所示:
1 | |
需要注意的是我们这里的x其实就是样本,所以 $$\mu$$实际上并不是标准的均值,故理论上在计算方差时应该除以N-1,不然就是有偏的。不过由于GPT-2的结构是这样的,所以我们仿照它的做法,此外由于embedding层的维数N一般都比较大,所以N和N-1也差别不大。
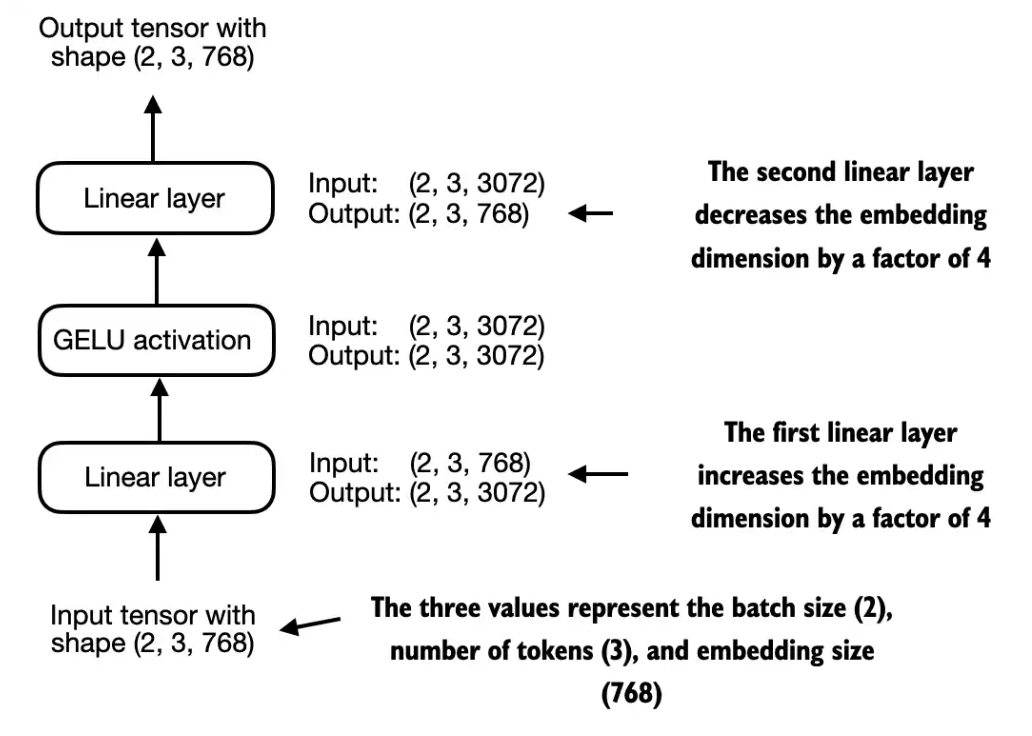
Implementing a feed forward network with GELU activations
一个前馈网络的结构如下:
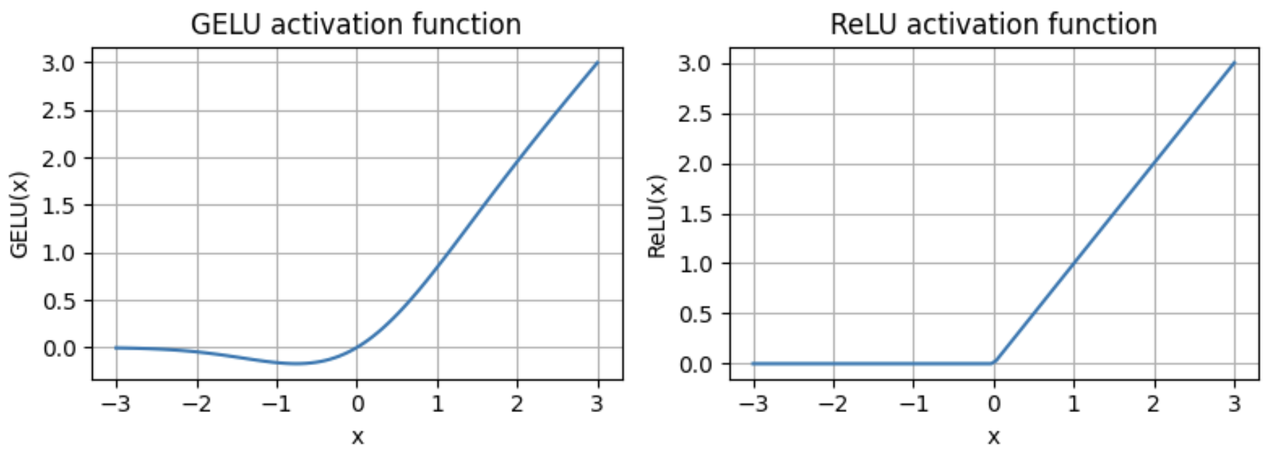
注意这里采用的是GELU激活函数,其表达式如下:
$$\text{GELU}(x) \approx 0.5 \cdot x \cdot \left(1 + \tanh\left[\sqrt{\frac{2}{\pi}} \cdot \left(x + 0.044715 \cdot x^3\right)\right]\right)$$
相比于RELU激活函数,GELU是一个平滑的非线性函数,近似于ReLU,但负值具有非零梯度(约-0.75除外)。
代码实现前馈网络如下:
1 | |
Adding shortcut connections
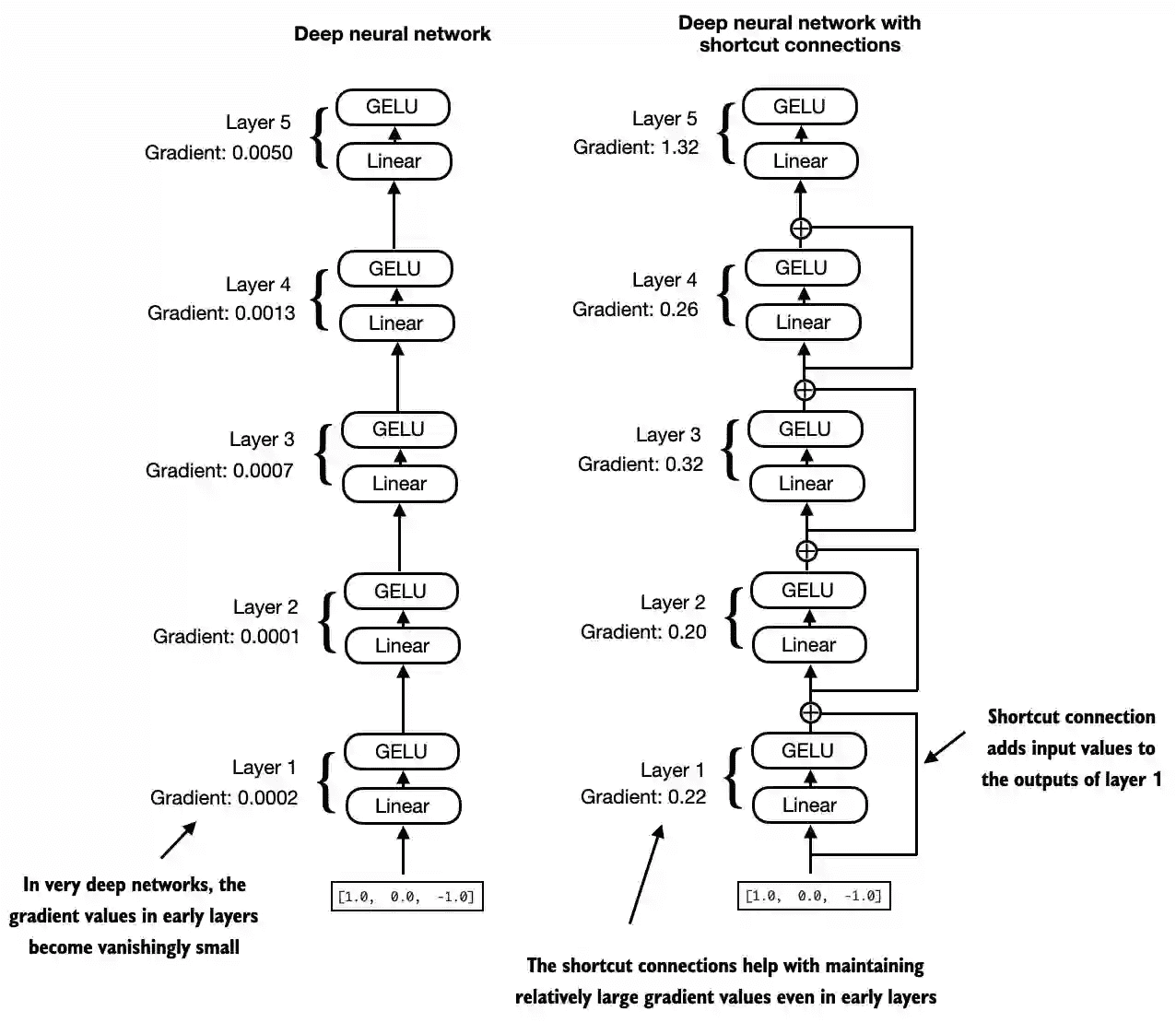
shortcut连接主要是为了解决梯度消息的问题,它将之前网络的输出与现在网络的输入相加后再进行传递,如下所示:
该机制的代码实现如下所示:
1 | |
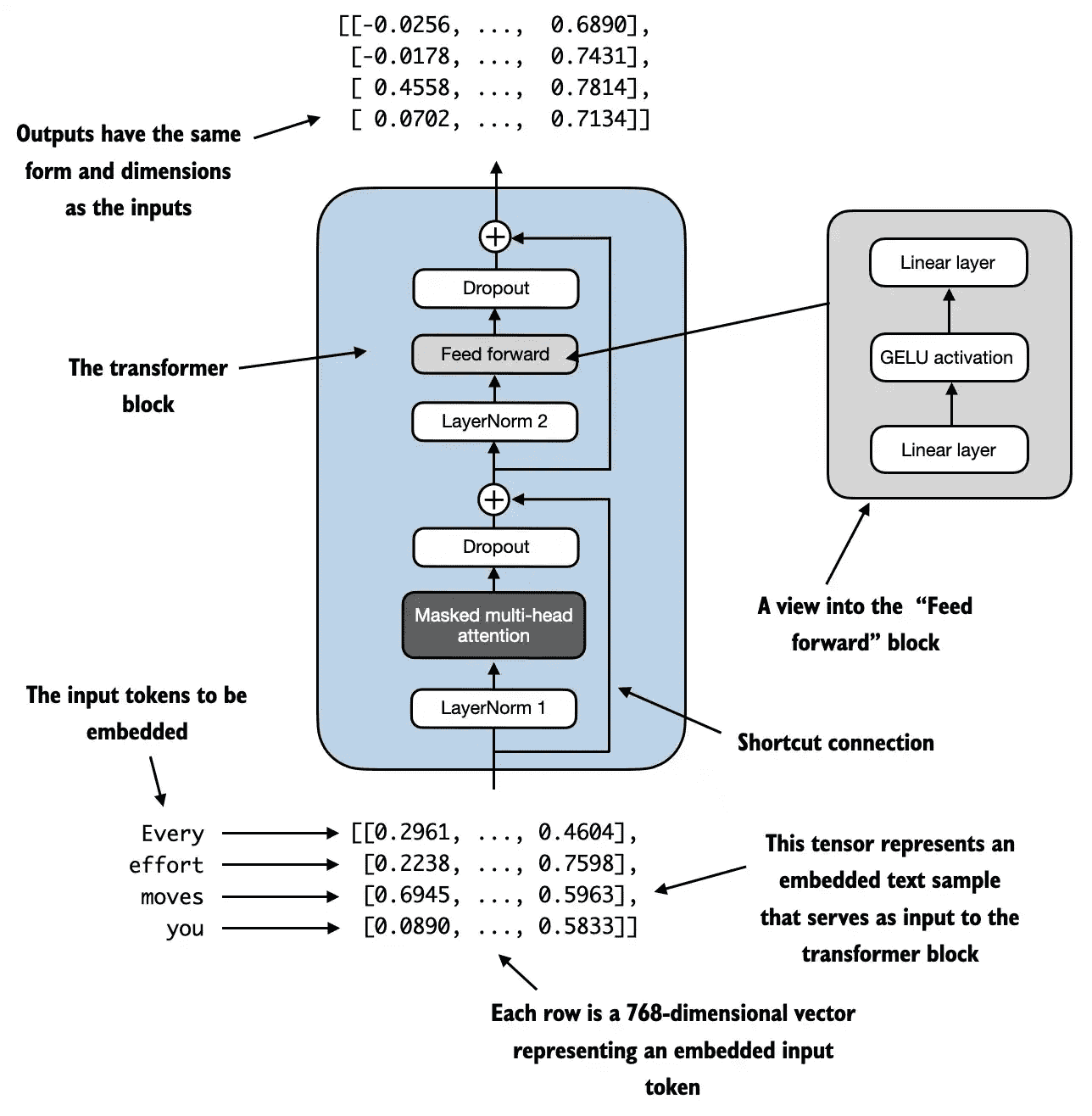
Connecting attention and linear layers in a transformer block
一个transformer块的结构如下所示:
简单的代码实现如下:
1 | |
transformer块采用这种结构的好处可以如下理解:
多头注意力机制可以识别并分析出序列中各元属之间的关系
前馈网络强化了局部的信息
对每个位置进行特定的非线性变换,提升其独立特征表达
协同效果:这种组合让模型既能捕捉全局模式,又能处理局部细节,从而在面对复杂数据模式时表现出更强的处理能力。
【例】句子翻译任务:自注意力机制帮助模型理解句子结构和词语之间的关系;前馈网络对每个单词的特定信息进行调整和优化,从而生成更准确的翻译。
注意对于整一个Transformer结构,其输入和输出的形状最后是相同的。这种输入输出相同的设计更加方便各层之间的叠加,输入可以直接当做输出叠加上去。
例如下面的这个示例,我们采用batch size=2,上下文长度为4,每个embedding层的维度为768,最后得到的结果也是相同的形状。
1 | |
Coding the GPT model
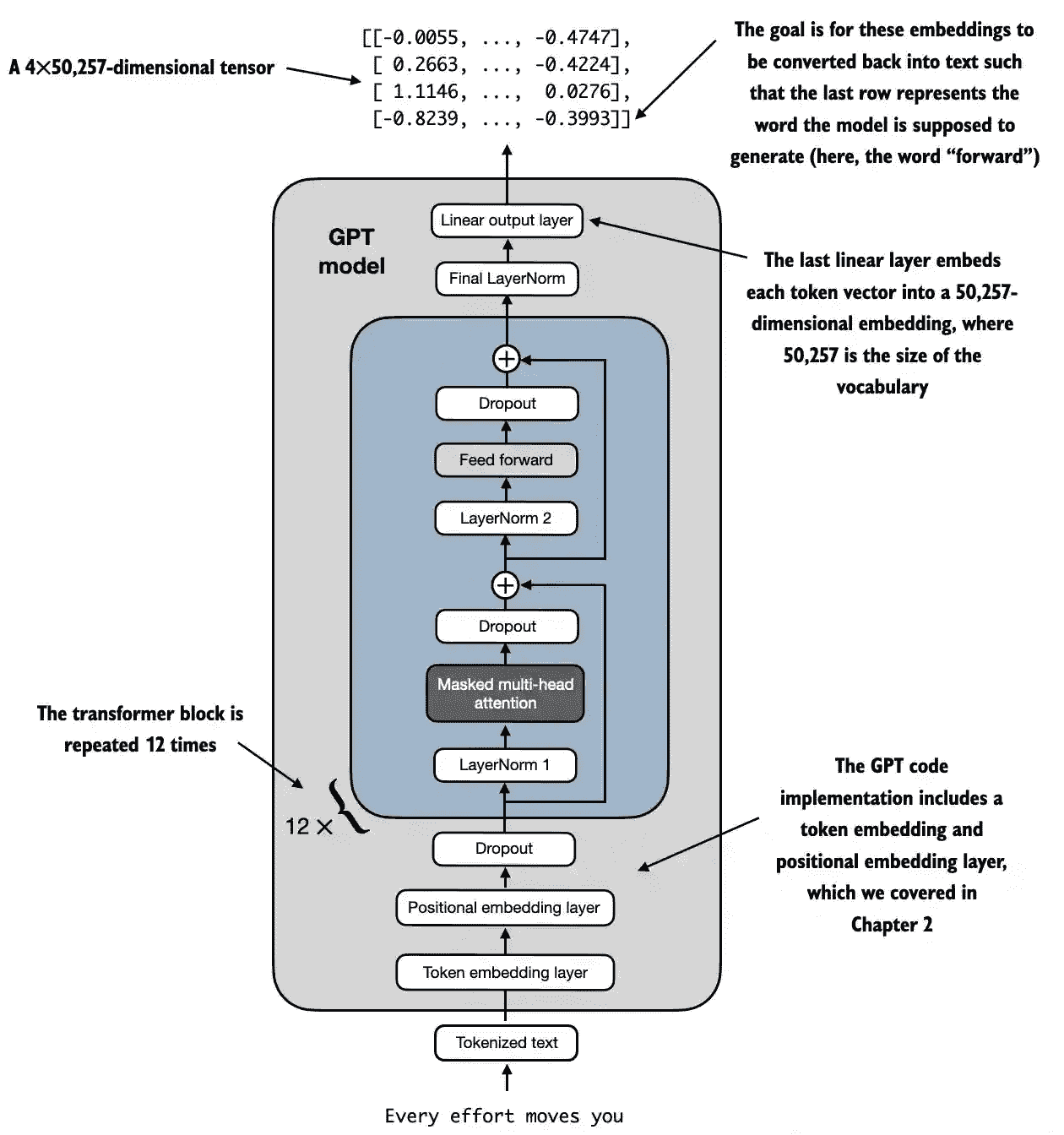
一个GPT模型的结构概览如下图所示。
对于一个124 million参数的GPT-2模型,其使用了12个transformer块,对于最大的 GPT-2 模型,其参数有 1.542 billion,这个 Transformer 块重复了 36 次。
叠加起来的代码实现如下:
1 | |
注意模型最后的输出的结果是后续接着各个词的对应id的概率,其维度为字典的大小。注意其实际上生成了这个上下文中各个前缀生成的可能的词的结果。
1 | |
参数量分析
GPT2各个size的参数如下:
GPT2-small (the 124M configuration we already implemented):
“emb_dim” = 768
“n_layers” = 12
“n_heads” = 12
GPT2-medium:
“emb_dim” = 1024
“n_layers” = 24
“n_heads” = 16
GPT2-large:
“emb_dim” = 1280
“n_layers” = 36
“n_heads” = 20
GPT2-XL:
“emb_dim” = 1600
“n_layers” = 48
“n_heads” = 25
我们代码实现的是GPT2-small,但是如果我们直接将所有的参数量都统计出来会发现其值并不是124M,而是163M:
1 | |
这是由于在最初的GPT-2模型中使用了模型参数绑定,也就是self.out_head.weight = self.tok_emb.weight。因为tok_emb负责将id转化为对应的embedding,其行数是50257,列数是768维,而out_head负责将embedding再转为字典中词数量的维度,故可以复用。
减去out_head这一层的参数量后也可以看到确实就是124M的参数量
1 | |
Generating text
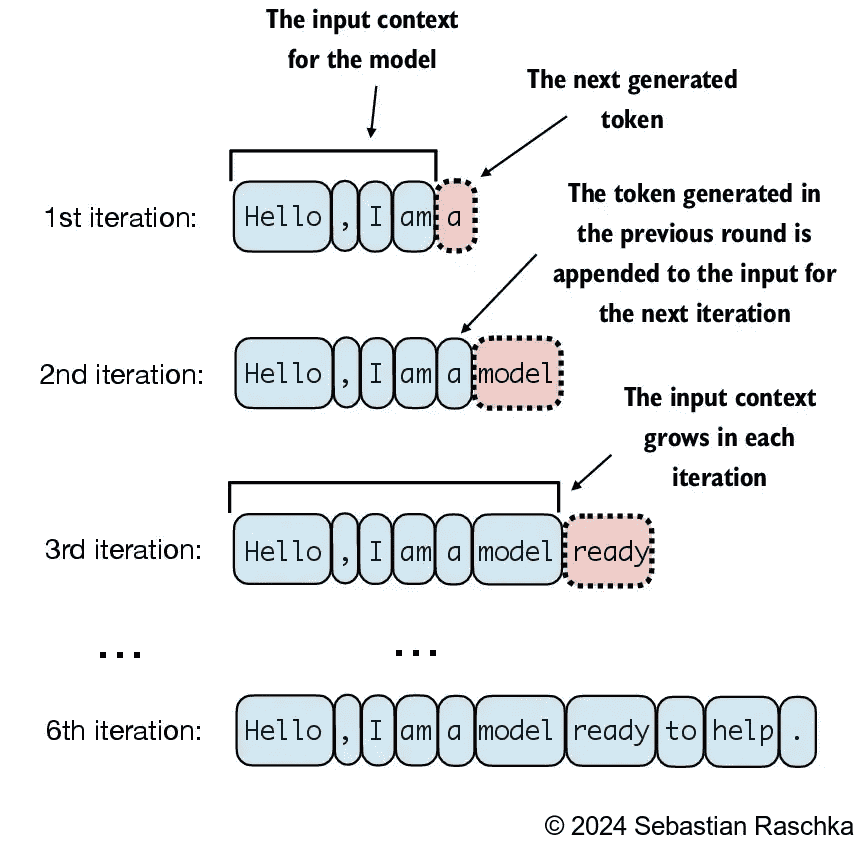
下图展示了生成文本的一个经典过程,即每次生成一个新的token,然后再将这个token拼接起来继续生成后一个token。
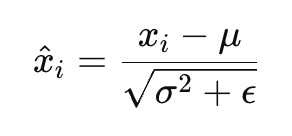
一个简单的生成文本的代码实现如下所示,在这里我们将只取输出的n_token那一层的最后一维,代表利用前面全部的信息所得到的后一个词的预测结果,然后再简单地进行softmax选取概览最高的那一个词作为输出。
1 | |
注意这时我们还没有对模型训练,所以模型前向传播得到的都是一些混乱的单词
1 | |