【从零构建大模型】四、对模型进行无监督训练
概览
构建大模型的全景图如下,本文介绍了如何训练大模型以及如何重加载已有的预训练过的大模型参数。
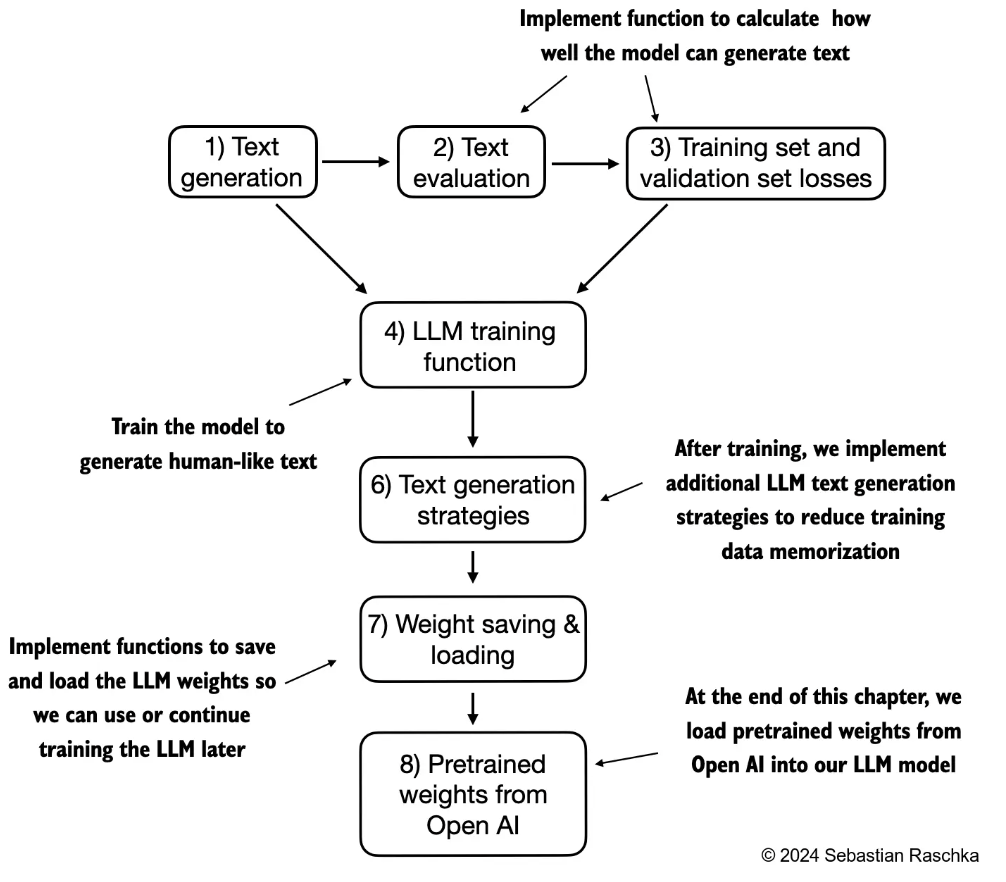
介绍的脉络如下:
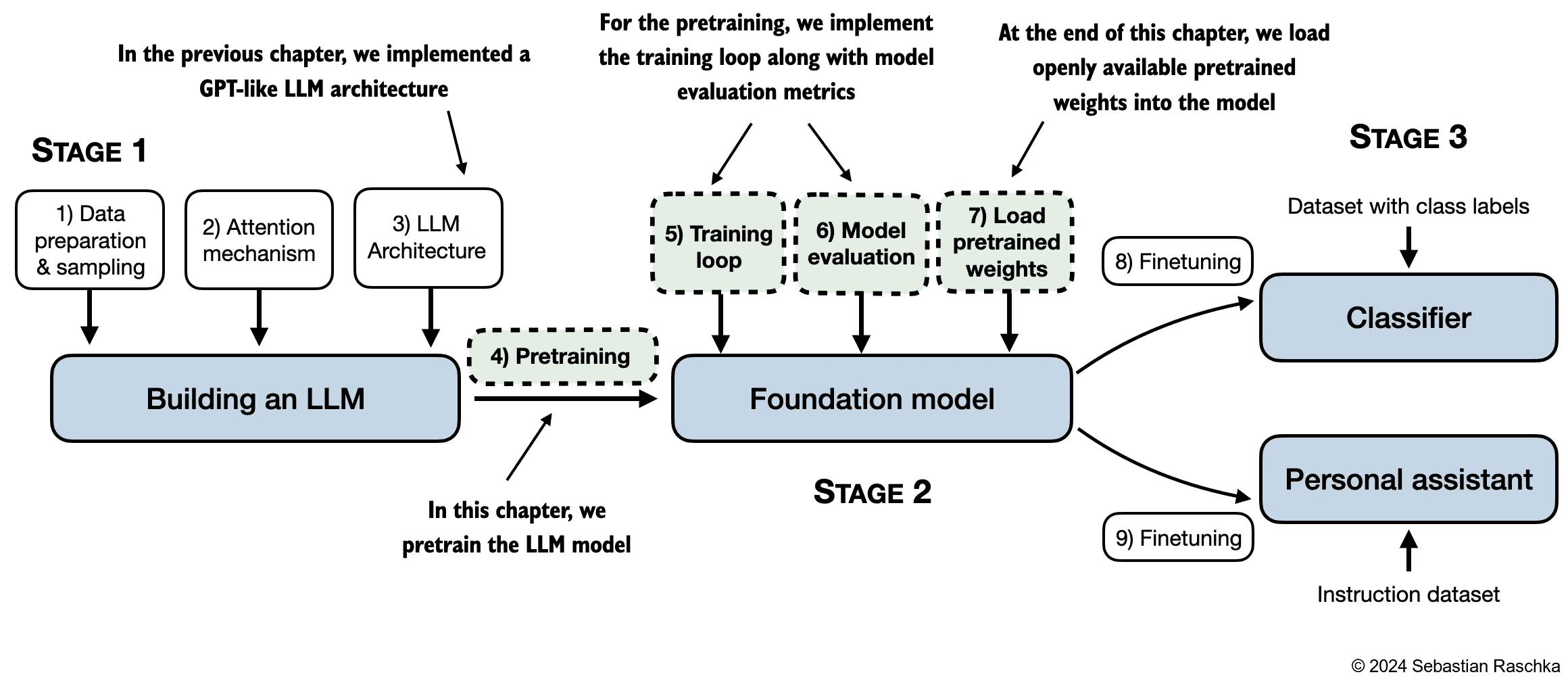
介绍
Evaluating generative text models
Using GPT to generate text
简单回顾一下GPT模型,其结构的关键参数如下所示:
1 | |
注意在现在流行的LLM中往往已经不给
nn.Linear加入bias层。为了降低计算开销把上下文长度从1024缩减到了256。
一个简单的对输入输出进行解码器的函数如下:
1 | |
可以看到现在没有被训了的模型的输出还是很混乱的。
Calculating the text generation loss: cross-entropy and perplexity
假设现在一个batch中有两个训练实例,那么其target就是相应的右移一位的结果,如下所示。
1 | |
最后在经过模型前向传播后我们会得到每一个batch中各个前缀的推理结果,这个结果的维度是字典中各个token的概览,简单地通过softmax获取最高可能性的token就可以得到推理的结果,如下所示:
1 | |
现在的输出是混乱的,我们需要计算其与我们想要的target之间的距离,直接去看我们的target的token在输出中预测的概率即可,因为我们最后是希望其对应的概率是1。
而由于在训练过程中优化概率的对数比优化概率本身更加容易,所以我们会对概率取一个对数,又因为我们一般都是说最小化某个值,所以我们再取一个负数修改目标为最小化。而这也叫做cross_entropy(交叉熵)。
更通用的交叉墒的公式为:
$$H(y, \hat{y}) = -\sum_{i=1}^{C} y_i \log(\hat{y}_i)$$
由于我们这目标是唯一的一个target,而其他token的目标概率都为0,所以就可以只关注目标y这一个。
纯手写的计算方法如下:
1 | |
直接调用pytorch的写法如下,稍微不同的一点在于我们需要先将其展开,消去batch维度:
1 | |
此外直接对交叉墒求指数就可以得到困惑度,它代表了大模型对输出的不确定性,越低的困惑度就更接近真实的分布,如下:
1 | |
Calculating the training and validation set losses
在训练过程中会将数据分为训练集和测试集,最简单的分法就是直接将文本按比例进行划分,如下:
1 | |
然后计算每一个batch的的损失方法以及一个数据集中指定batch数量的损失的方法如下所示:
1 | |
此时直接计算整个训练集和测试集的损失如下所示,可以看到都是比较大的损失:
1 | |
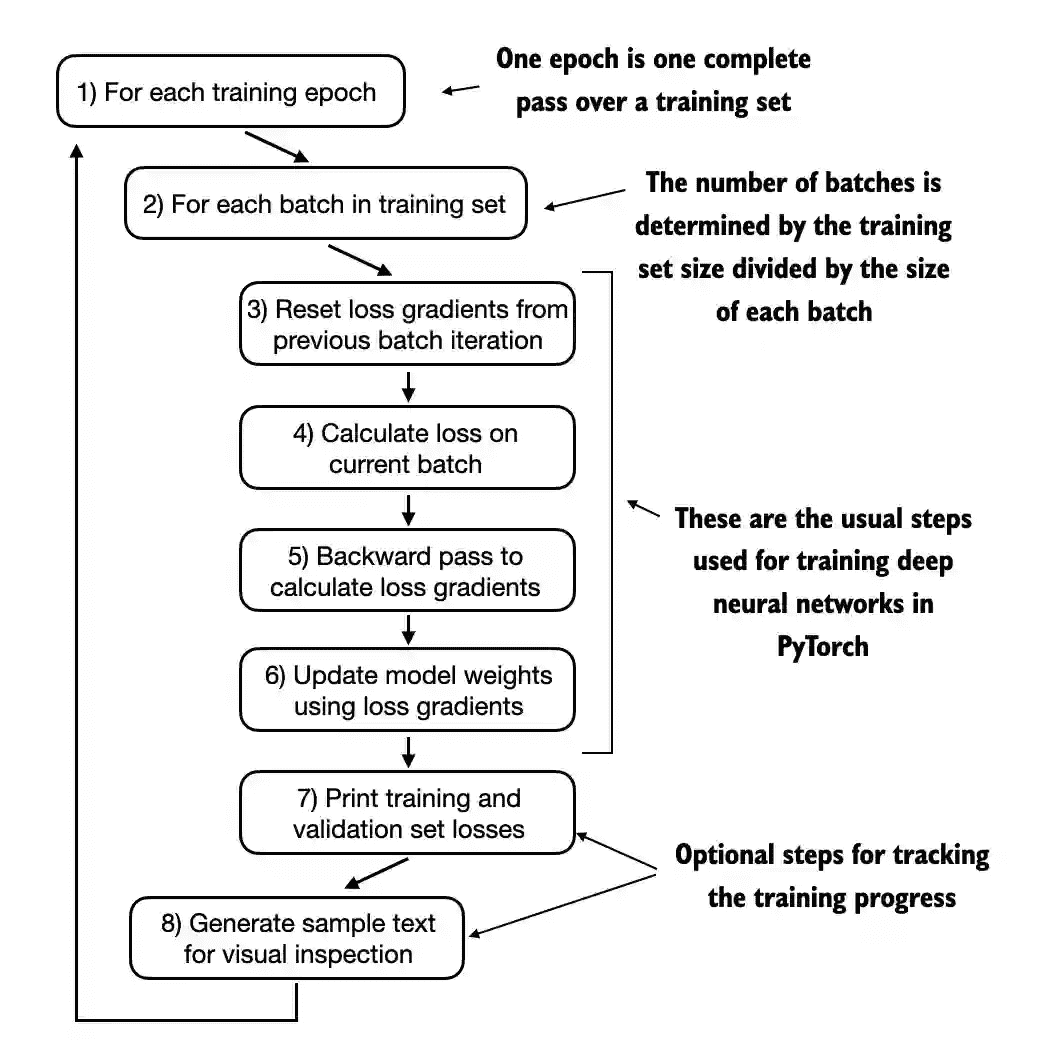
Training an LLM
暂时不考虑一些高阶的大模型训练方法,其整体的训练流程如下:
训练代码如下:
与之前相比新加的内容为添加了loss.backward()进行反向传播获得梯度
添加了optimizer.step() 进行参数更新
1 | |
我们这里采用经典的AdamW优化器,调用上述代码进行训练的代码如下:
- 可以看到随着训练的持续,模型可以输出一些更加通顺的句子
1 | |
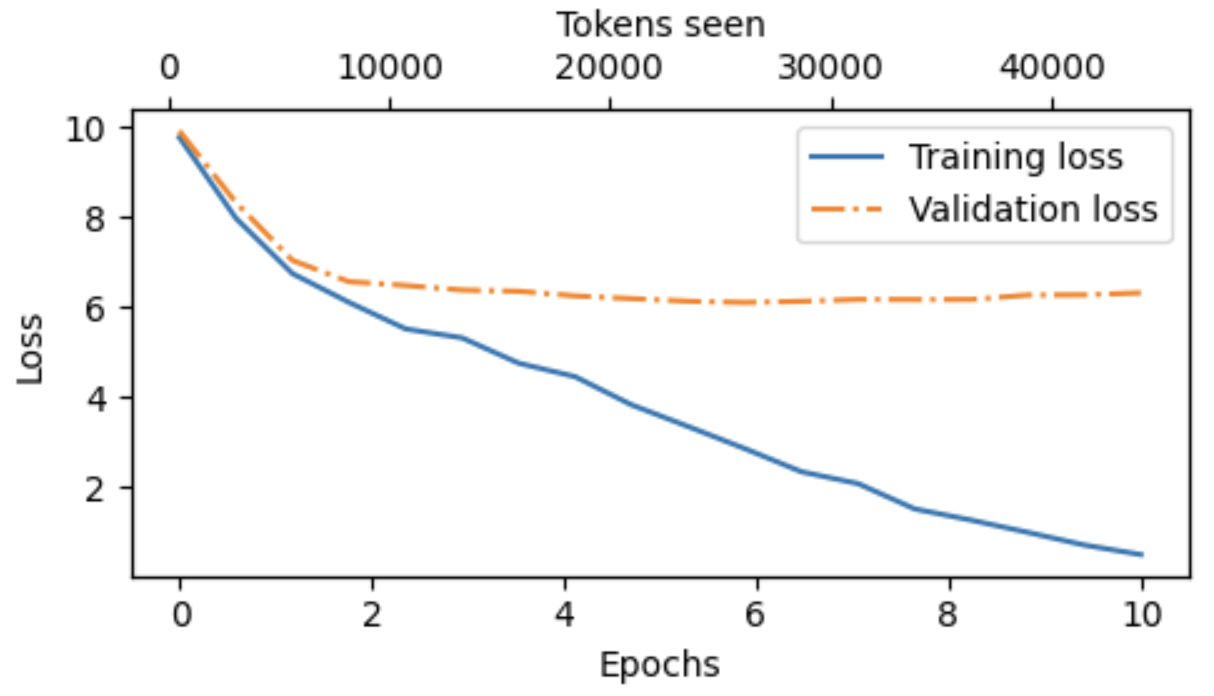
绘制训练集的loss与验证集的loss如下,可以发现整个模型训练过程中训练集的loss在一直快速下降,但是验证集的loss后面就基本保持不变了,说明其实是有发生过拟合的。
Decoding strategies to control randomness
这里介绍一下如何控制输出随机性的内容。上面介绍的输出实际上对于相同的输入一直都是相同的输出,我们希望能够有更加多样化的输出内容。
Temperature scaling
一个方法就是通过对概率采样来得到输出,因为我们现在最后已经有了各个token的概率,这样概率大的自然采用得到的概率也就更大,代码实现如下:
1 | |
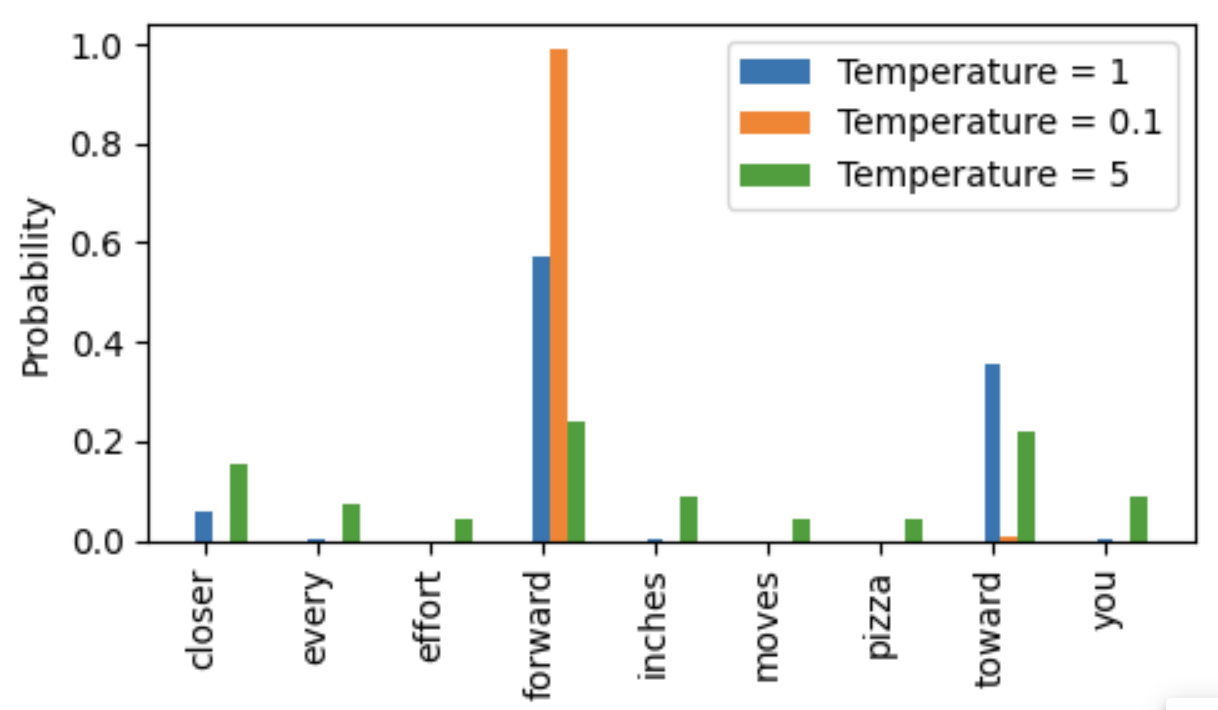
此外我们可以控制Temperature scaling(温度缩放)来进一步控制概率分布的整体情况,其做法就是在输出的概率进行softmax前除以一个temperature。
如果temperature大于1那么就会使得各个概率被缩小,整体分布比较平缓
如果temperature小于1那么就会使得各个概率被放大,整体分布比较尖锐
代码实现如下:
1 | |
同一个概率分布下不同的temperature控制下的概率分布情况如下所示:
Top-k sampling
通过采样得到输出有可能得到概率较低的输出,这实际上可能确实是错误的输出,所以我们可以将top-k以外的输出概率都置为0来避免这种情况,其实际在处理时也就是在softmax之前将top-k以外的概率置为-inf,代码实现如下:
1 | |
Modifying the text generation function
通过结合上述两项技术就可以得到一个新的generate函数,如下所示:
1 | |
Loading and saving model weights in PyTorch
我们可以在训练过程中保存检查点,然后再有需要的时候再进行加载,从而支持断点续训的功能。
注意为了能够继续训练,我们往往不止需要保持模型的权重还需要保存优化器中的权重。
1 | |
Loading pretrained weights from OpenAI
我们可以直接通过gpt_download库来下载gpt-2的权重信息,下载方法如下(注意这里已经下好了):
1 | |
查看一些关键文件的内容:
1 | |
可以看到embedding层确实就是我们之前说的支持50257种token,每个token的维度为768。
我们可以直接将下载到的模型的权重加载进我们自定义的相同结构的模型中:
1 | |
然后进行调用和输出
1 | |
实际上还有许多其他的模型权重的加载方法,这里先不再赘述。