GPU架构概览
GPU架构概览
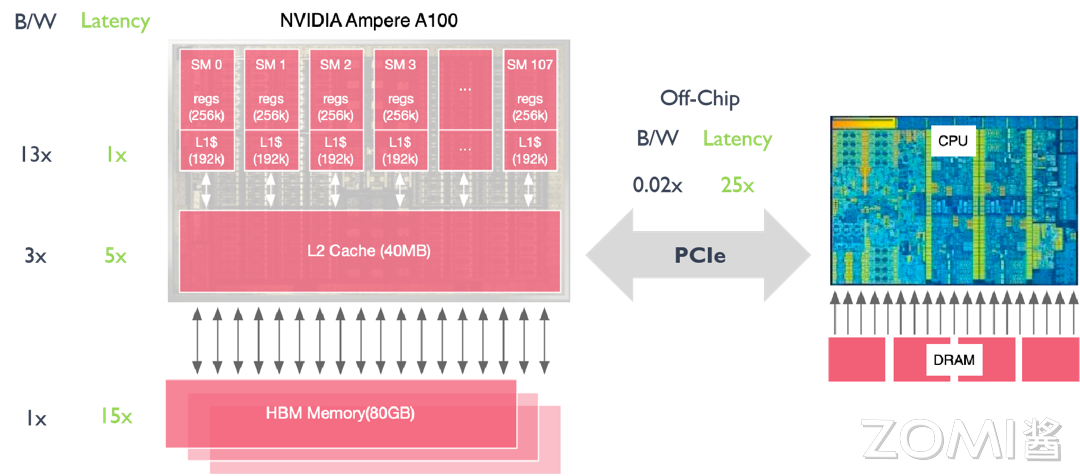
物理体系架构
下图是A100的物理体系架构:
- 绿色部分是计算核心
在 NVidia 的 GPU 里,最基本的处理单元是SP(Streaming Processor),A100中,64SP会组成一个SM(streaming Multiprocessor),SM是GPU中调度的基础单元,A100中总共具有108个SM,所以得到共有108*64=6192个计算核心。
中间蓝色部分是L2缓存
最上面是PCIE层,通过PCIE接口以外设的方式集成到服务器上。
最下面是NVLink,它是多个GPU间进行通信的组件,会对GPU之间的通信做些优化
两侧的HBM2就是显存,目前的A100的显存有两种40G and 80G

SM是核心的计算元件,下图是A100的SM的结构,可以看到:
存在一个192KB的L1级的Cache
各计算单元SP/CUDA Core存在一个L0级的指令Cache
在 Fermi 架构之后,SP 被改称为 CUDA Core,通过 CUDA 来控制具体的指令执行。
计算单元存在适配 FP16、BF16、TF32、FP64、INT8、INT4 和 Binary 等各类数据类型运算的向量运行单元
计算单元存在一个额外的Tensor core去进行张量计算
每个TensorCore提供一个4x4x4矩阵处理数组,它执行操作D=A*B+C,其中A、B、C和D是4×4矩阵。每个TensorCore每个时钟周期可以执行64个浮点FMA混合精度操作,而在一个SM中有多个TensorCore。
张量核心与普通的 CUDA 核心其实有很大的区别,CUDA 核心在每个时钟周期都可以准确的执行一次整数或者浮点数的运算,时钟的速度和核心的数量都会影响整体性能。张量核心通过牺牲一定的精度可以在每个时钟计算执行一次 4 x 4 的矩阵运算。
计算单元还存在一个Warp调度器负责调度执行可运行的Warp
计算单元有专门的特殊函数的计算单元(Special Functions Unit、SPU),(超越函数和数学函数,反平方根、正余弦啥的)
计算单元还存在Dispatch Unit作为指令分发单元

其内存架构如下图所示:
最外层是HBM内存,大小为80GB
然后还有一个SM共享的L2 Cache,大小为40MB
每个SM有一个L1级的Cache,大小为192KB
每个SM的寄存器也可以视作一个缓存,大小为256KB
GPU与CPU之间通过PCIe进行通信
CUDA编程模型下的逻辑体系结构
CUDA简介
一个CUDA程序的可以分为两个部分: 在CPU上运行的Host程序;在GPU上运行的Device程序。两者拥有各自的存储器。GPU上运行的函数又被叫做kernel函数,通过global关键字声名,例如:
1 | |
可以看到在程序中我们需要声明用多少个block,每个block中使用多少线程。线程可以使用1维、2维、3维的线程索引(thread index)来标识,block也可以使用1维、2维、3维的索引。例如在上面的启动命令kernel<<<numBlocks, threadsPerBlock>>>()中就分别制定了block的数量以及每个block中threads的数量。然后在具体的kernel计算就可以根据相关id计算出要取第几位的数。
计算线程模型简介
在CUDA架构下,线程的组织结构可以统一成如下所示:
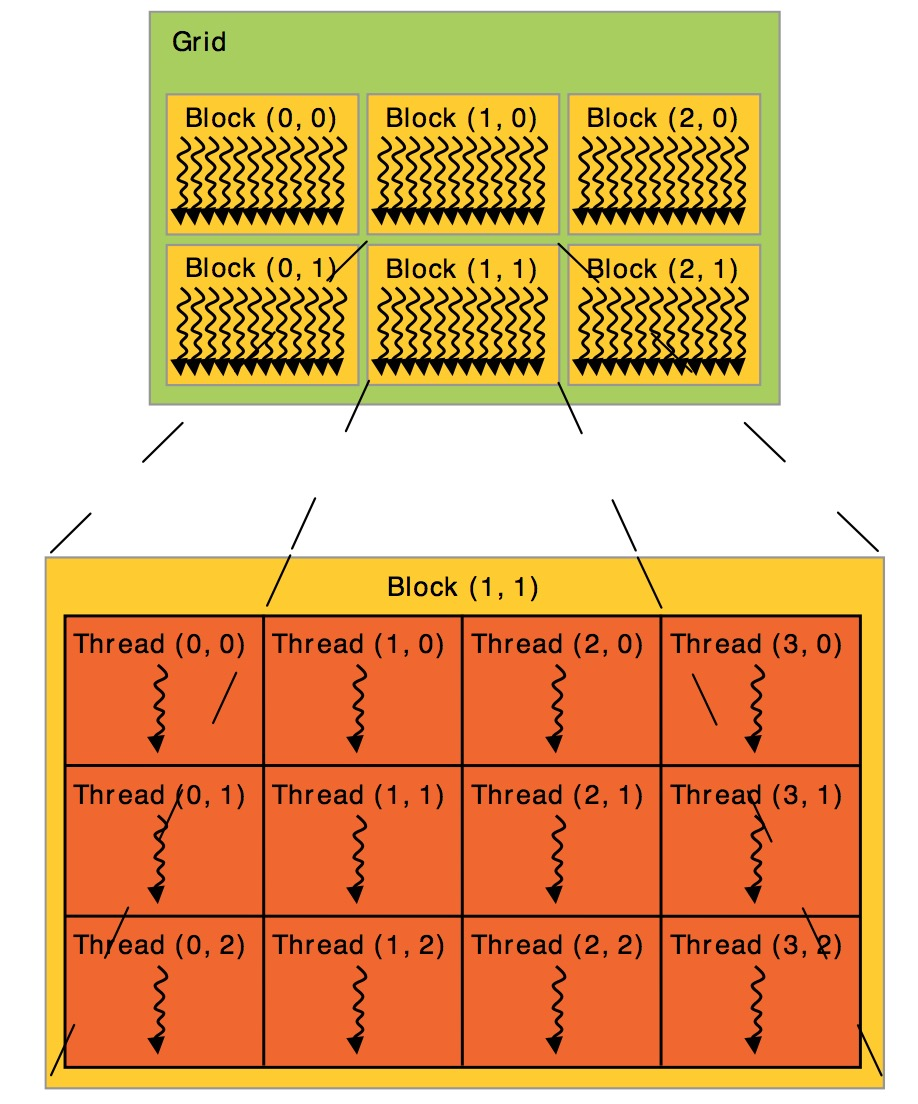
总的来说,CUDA 可以分为 Grid,Block 和 Thread 三个层次结构:
线程层次结构Ⅰ-Grid:Kernel 在 device 上执行时,实际上是启动很多线程,一个 Kernel 所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间,grid 是线程结构的第一层次。
线程层次结构Ⅱ-Block:Grid 分为多个线程块(block),一个 block 里面包含很多线程,Block 之间并行执行,并且无法通信,也没有执行顺序,每个 block 包含共享内存(shared memory),可以共享里面的 Thread。
线程层次结Ⅲ-Thread:CUDA 并行程序实际上会被多个 threads 执行,多个 threads 会被群组成一个线程 block,同一个 block 中 threads 可以同步,也可以通过 shared memory 通信。
将这些线程与硬件进行对应的关系如下所示:
| 软件 | 硬件 |
|---|---|
| Thread | SP/CUDA Core |
| Block | SM |
| Grid | 一组SM |
注意往往32个Thread会组成一个Warp,Warp的调度流程如下:
线程启动后,被分组成若干个 warp(每 32 个线程为一组)
每个 warp 被分配到某个 SM 上执行
SM 的 warp scheduler 轮询多个 warp,选择 ready warp 发射指令
同一个warp中的thread可以以任意顺序执行,active warps被SM资源限制。当一个warp空闲时,SM就可以调度驻留在该SM中另一个可用warp。在并发的warp之间切换是没什么消耗的,因为硬件资源早就被分配到所有thread和block,所以新调度的warp的状态已经存储在SM中了。
GPU 的线程切换只是切换了寄存器组(一个 SM 中有高达 64k 个寄存器),延迟超级低,几乎没有成本。一个 CUDA Core 可以随时在八个线程之间反复横跳,哪个线程数据准备好了就执行哪个。
- warp 内所有线程执行同一条指令,但使用不同数据(即 data-parallel)
GPU 控制部件面积比较小,为了节约控制器,一个 Warp 内部的所有 CUDA Core 的 PC(程序计数器)一直是同步的,但是访存地址是可以不同的,每个核心还可以有自己独立的寄存器组,它们使用不同的数据执行相同的命令,这种执行方式叫做 SIMT(Single Instruction Multi Trhead)。
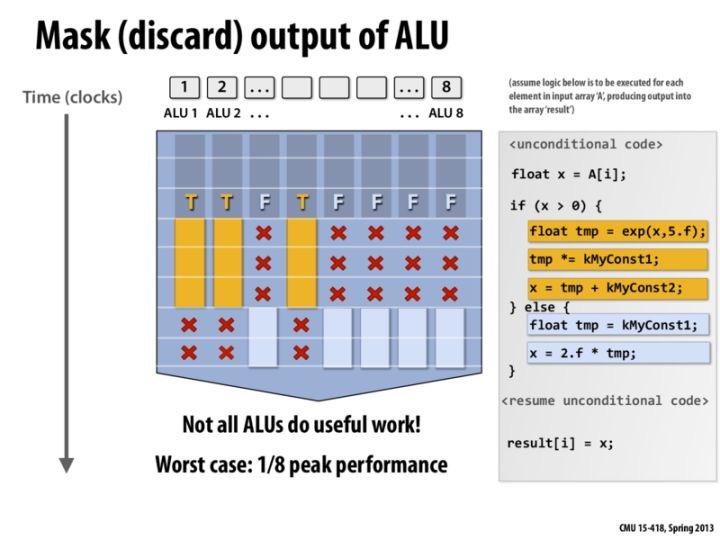
- 遇到分支时,warp divergence 会导致串行化执行不同路径
极端情况下,每一个Core的指令流都不一样,那么甚至还可能导致一个 Warp 中仅有一个 Core 在工作,效率降低为 1/32.
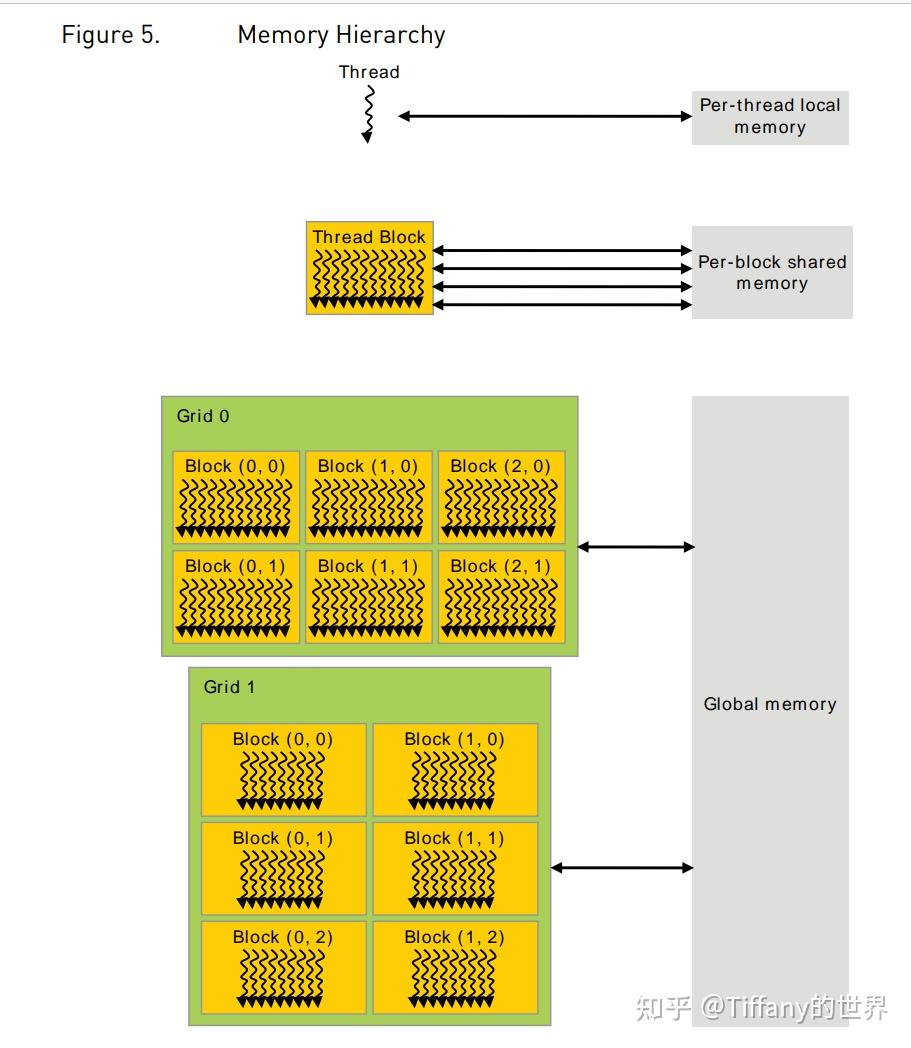
内存模型简介
CUDA threads在执行时,可以访问多个memory spaces,每个线程有自己的私有的local memory。每个block有一个shared memory,block的所有线程都可以访问。最后,所有线程都可以访问global memory。
历史架构演进
| 架构名称 | 中文名字 | 发布时间 | 核心参数 | 特点&优势 | 纳米制程 | 代表型号 |
|---|---|---|---|---|---|---|
| Fermi | 费米 | 2010 | 16 个 SM,每个 SM 包含 32 个 CUDA Cores,一共 512 CUDA Cores | 首个完整 GPU 计算架构,支持与共享存储结合的 Cache 层次 GPU 架构,支持 ECC GPU 架构 | 40/28nm, 30 亿晶体管 | Quadro 7000 |
| Kepler | 开普勒 | 2012 | 15 个 SMX,每个 SMX 包括 192 个 FP32+64 个 FP64 CUDA Cores | 游戏性能大幅提升,首次支持 GPU Direct 技术 | 28nm, 71 亿晶体管 | K80, K40M |
| Maxwell | 麦克斯韦 | 2014 | 16 个 SM,每个 SM 包括 4 个处理块,每个处理块包括 32 个 CUDA Cores+8 个 LD/ST Unit + 8 SFU | 每组 SM 单元从 192 个减少到每组 128 个,每个 SMM 单元拥有更多逻辑控制电路 | 28nm, 80 亿晶体管 | M5000, M4000GTX 9XX 系列 |
| Pascal | 帕斯卡 | 2016 | GP100 有 60 个 SM,每个 SM 包括 64 个 CUDA Cores,32 个 DP Cores | NVLink 第一代,双向互联带宽 160GB/s,P100 拥有 56 个 SM HBM | 16nm, 153 亿晶体管 | P100, P6000, TTX1080 |
| Volta | 伏特 | 2017 | 80 个 SM,每个 SM 包括 32 个 FP64+64 Int32+64 FP32+8 个 Tensor Cores | NVLink2.0,Tensor Cores 第一代,支持 AI 运算,NVSwitch1.0 | 12nm, 211 亿晶体管 | V100, TiTan V |
| Turing | 图灵 | 2018 | 102 核心 92 个 SM,SM 重新设计,每个 SM 包含 64 个 Int32+64 个 FP32+8 个 Tensor Cores | Tensor Core2.0,RT Core 第一代 | 12nm, 186 亿晶体管 | T4,2080TI, RTX 5000 |
| Ampere | 安培 | 2020 | 108 个 SM,每个 SM 包含 64 个 FP32+64 个 INT32+32 个 FP64+4 个 Tensor Cores | Tensor Core3.0,RT Core2.0,NVLink3.0,结构稀疏性矩阵 MIG1.0 | 7nm, 283 亿晶体管 | A100, A30 系列 |
| Hopper | 赫柏 | 2022 | 132 个 SM,每个 SM 包含 128 个 FP32+64 个 INT32+64 个 FP64+4 个 Tensor Cores | Tensor Core4.0,NVLink4.0,结构稀疏性矩阵 MIG2.0 | 4nm, 800 亿晶体管 | H100 |
| Blackwell | 布莱克韦尔 | 2024 | - | Tensor Core5.0,NVLink5.0, 第二代 Transformer 引擎,支持 RAS | 4NP, 2080 亿晶体管 |
具体可以看这个:
https://github.com/chenzomi12/AISystem/blob/main/02Hardware/03GPUBase/04History.md