Pytorch torch.distributed 举例学习 单机通信 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import osimport torchimport torch.distributed as distimport torch.multiprocessing as mpdef setup (rank, world_size ):'MASTER_ADDR' ] = '127.0.0.1' 'MASTER_PORT' ] = '29500' 'nccl' , rank=rank, world_size=world_size)def cleanup ():def demo_all_reduce (rank, world_size ):1 ).to(rank) * rankprint (f"[{rank} ] Before all_reduce: {tensor.item()} " )print (f"[{rank} ] After all_reduce: {tensor.item()} " )def main ():4 True )if __name__ == "__main__" :
一些注意事项:
mp.spawn可以同时启动多个训练进程,并传入不同的rank参数
dist.init_process_group(backend='nccl', rank=rank, world_size=world_size)是初始化一个默认的通信进程组。
初始化时需要指定使用什么通信backend,这里选择的是经典的nccl
然后还需给出当前的进程的rank,相当于是在告诉后端什么rank加入到了这个进程组
然后还需要指定world_size,即有多少个进程参与了通信。注意只有world_size个进程都完成了通信,一个通信操作才算完成。
还可以指定init_method指定分布式各进程之间如何发现彼此,完成初始化同步。常见取值 :
类型 示例 含义
TCP 地址
‘tcp://127.0.0.1:29500’
所有进程通过该地址建立连接
环境变量
‘env://‘
读取 MASTER_ADDR, MASTER_PORT 等环境变量
文件系统
‘file:///tmp/shared_init’
所有进程通过同一个文件进行同步(通常用于单机多进程)
默认值 :如果你设置了 MASTER_ADDR 和 MASTER_PORT,可以使用 'env://' 来简洁初始化。
创建多个通信组 注意上面相当于是在创建一个默认的通信组,如果有创建多个通信组的需求,必须在创建默认的通信组后再自行创建,主要有两种方法:
一种是直接通过dist.new_group来创建一个group进行通信。如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import torchimport torch.distributed as distimport osdef setup (rank, world_size ):'MASTER_ADDR' ] = '127.0.0.1' 'MASTER_PORT' ] = '29500' 'nccl' , rank=rank, world_size=world_size)if rank in [0 , 1 ]:0 , 1 ])else :2 , 3 ])print (f"[Rank {rank} ] tensor after all_reduce in group: {tensor.item()} " )
另一种是是通过dist.new_subgroups_by_enumeration来批量创建多个group进行通信,这适合需要创建多个group的场景,更加高效,其输入的参数类型为list[list[int]]。如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import osimport torchimport torch.distributed as distfrom torch.multiprocessing import spawndef init_distributed (rank, world_size ):'MASTER_ADDR' ] = 'localhost' 'MASTER_PORT' ] = '29500' 'RANK' ] = str (rank)'WORLD_SIZE' ] = str (world_size)'nccl' , init_method='env://' , rank=rank, world_size=world_size)2 , 2 , 2 assert world_size == dp * pp * tpfor d in range (dp) for p in range (pp)]for d in range (dp) for t in range (tp)]for p in range (pp) for t in range (tp)]next (g for g in tp_group_list if g is not None )next (g for g in pp_group_list if g is not None )next (g for g in dp_group_list if g is not None )print (f"[Rank {rank} ] dp={dp_rank} , pp={pp_rank} , tp={tp_rank} | " f"TP group: {tp_groups[dp_rank * pp + pp_rank]} | " f"PP group: {pp_groups[dp_rank * tp + tp_rank]} | " f"DP group: {dp_groups[pp_rank * tp + tp_rank]} " )if __name__ == '__main__' :8
输出如下:
1 2 3 4 [Rank 0 ] dp=0, pp=0, tp=0 | TP group: [0 , 1 ] | PP group: [0 , 2 ] | DP group: [0 , 4 ]Rank 1 ] dp=0, pp=0, tp=1 | TP group: [0 , 1 ] | PP group: [1 , 3 ] | DP group: [1 , 5 ]Rank 2 ] dp=0, pp=1, tp=0 | TP group: [2 , 3 ] | PP group: [0 , 2 ] | DP group: [2 , 6 ]...
多机通信 多机通信与单机通信在使用上还是比较类似的,因为在初始化时,其视野里都是各个进程来进行连接,所以只需要网络是互通的,本地连接和远程连接的区别并没有那么大。
如下所示的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import osimport torchimport torch.distributed as distimport torch.nn as nnimport torch.optim as optimfrom torch.nn.parallel import DistributedDataParallel as DDPdef setup ():'nccl' , init_method='env://' )int (os.environ["LOCAL_RANK" ]))def cleanup ():def demo_basic (rank, world_size ):"cuda" , int (os.environ["LOCAL_RANK" ]))10 , 1 ).to(device)int (os.environ["LOCAL_RANK" ])])0.001 )64 , 10 ).to(device)64 , 1 ).to(device)for epoch in range (5 ):print (f"[Rank {dist.get_rank()} ] Epoch {epoch} Loss: {loss.item()} " )if __name__ == "__main__" :int (os.environ["RANK" ]), world_size=int (os.environ["WORLD_SIZE" ]))
假设现在需要在两台机器上运行那么就需要指定其中一台主机为master节点,然后分别执行如下的启动命令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 // 主机0 (master节点)2 \0 \4 \26.104 .249 .162 \29500 \1 2 \1 \4 \26.104 .249 .162 \29500 \
还可以设置如下的环境变量来进行相关的控制:
支持的通信操作 下面是参考官方文档,列举的torch.distributed模块实现的集合通讯操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 0 )0 )0 , op=dist.ReduceOp.SUM)0 )0 )0 )0 )10 )True )
NCCL原理浅析 一般GPU间的通信采取的都是NCCL
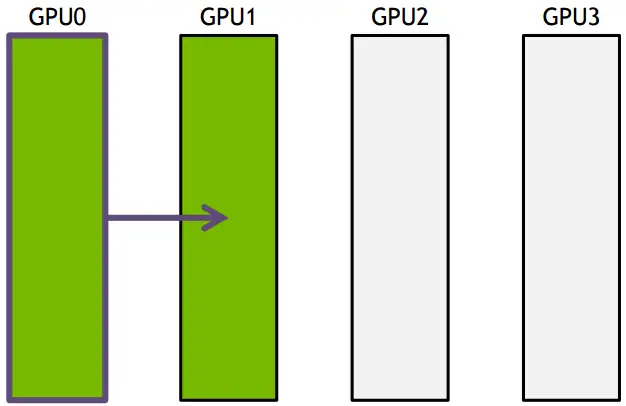
Ring-base collectives 一开始NCCL采取的是ring-base collectives,即将所有的通信节点通过首尾连接形成一个单向环,数据在环上依次传输。以broadcast为例, 假设有4个GPU,GPU0为sender将信息发送给剩下的GPU,按照环的方式依次传输,GPU0–>GPU1–>GPU2–>GPU3,若数据量为N,带宽为B,整个传输时间为(K-1)N/B。时间随着节点数线性增长,不是很高效。
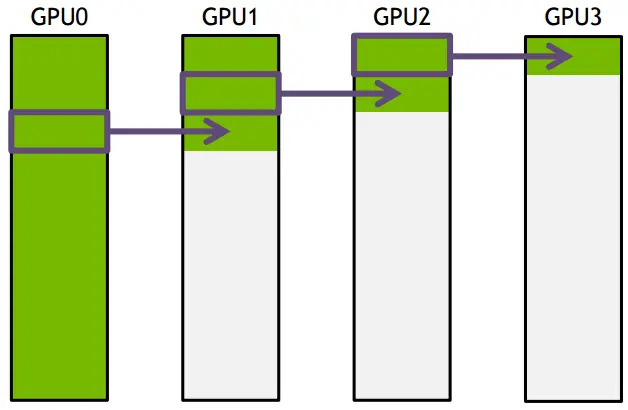
下面把要传输的数据分成S份,每次只传N/S的数据量,传输过程如下所示:
GPU1接收到GPU0的一份数据后,也接着传到环的下个节点,这样以此类推,最后花的时间为
S*(N/S/B) + (k-2)*(N/S/B) = N(S+K-2)/(SB) –> N/B,条件是S远大于K,即数据的份数大于节点数,这个很容易满足。所以通信时间不随节点数的增加而增加,只和数据总量以及带宽有关 。其它通信操作比如reduce、gather以此类推。
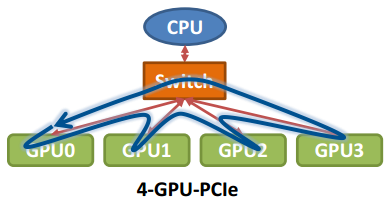
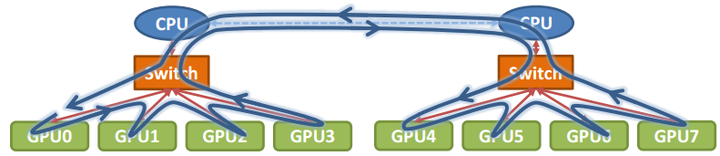
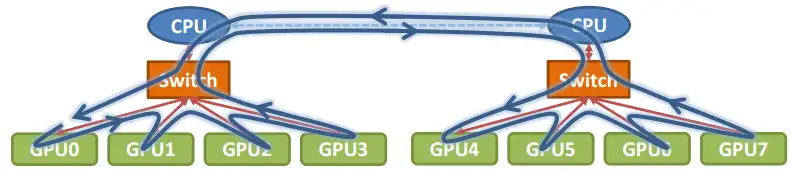
那么在以GPU为通信节点的场景下,怎么构建通信环呢?如下图所示:
单机4卡通过同一个PCIe switch挂载在一棵CPU的场景:
单机8卡通过两个CPU下不同的PCIe switch挂载的场景:
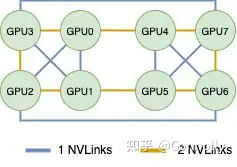
DGX-1 V100 在实际设计中,往往会采取将各GPU形成多个环的方式来进行通信加速。DGX-1的NVLink链接拓扑如下图所示,可以看到其形成了一个复杂的拓扑结构。
一般而言一个NVLink的带宽速度为25GB/s。注意上图中蓝色代表的是用一根NVLink相连,黄色代表的是用2根NVLinks相连,NVLink数量翻番往往也意味着其带宽也翻番了。例如在实际测试中,GPU0~GPU1之间的双向带宽为48GB/s,约为25GB/s * 2。GPU0和3之间的约为96GB/s,约为50GB/s *2。
NCCL在初始化的时候,会检查系统中的链路拓扑,并创建若干个环路,以达到最优的性能。以上图中的拓扑为例,NCCL会创建4种环路,分别是下面四种。这四种环相互不会影响,都是独立的链路带宽(不同方向,或者不同链路)。
Ring Channel
#NVLinks
Bus Bandwidth
0->4->7->6->5->1->2->3
2
50 GB/s
0<-4<-7<-6<-5<-1<-2<-3
2
50 GB/s
0->1->3->7->5->4->6->2
1
25 GB/s
0<-1<-3<-7<-5<-4<-6<-2
1
25 GB/s
接下来,NCCL会把需要通信的数据进行切片,每一个Channel负责通信部分的切片数据。这么一来,就同时有多个环在工作。我们知道一块V100可以插6根NVLink,NCCL这么一做,直接把6根NVLink的双向带宽全部拉满了,这理论的通信速度就达到了150GB/s。
在实际测试中,allreduce的性能最高达到了130GB/s,已经是一个很不错的结果了。
但是注意也正是这种多环路的设计使得在不是整机的时候会使得通信下降。
例如对于2卡,以GPU0和GPU1为例,其单向连接反而只有一条NVLink了,其速度降为25GB/s
例如对于4卡,以0,1,2,3 4张卡举例,可以形成4种回路,如下。此时双NVLink连接也会被降级为单NVlink连接的速度。整体的理想速度也只有了100GB/s
Ring Channel
#NVLinks
Bus Bandwidth
0->1->2->3
1
25GB/s
0<-1<-2<-3
1
25GB/s
0->3->1->2
1
25GB/s
0<-3<-1<-2
1
25GB/s
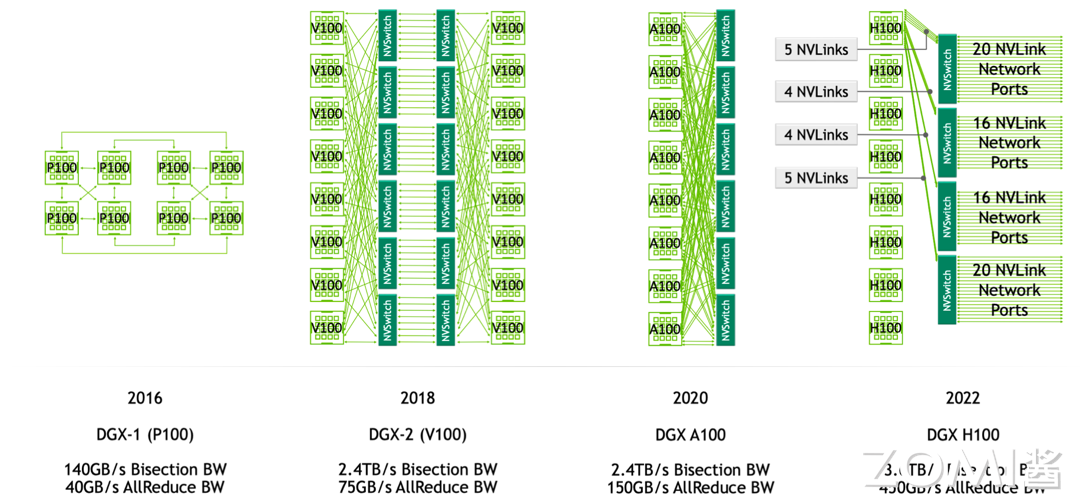
NVSwitch 随着技术的演进,为了更加全面的多卡之间的互联,MVSwitch应运而生。以下是各代GPU中的网络架构。可以看到从V系列开始,NVSwitch就被引入了进来。
在 DGX-1 P100 中有 8 张 GPU 卡,每张 GPU 卡支持 4 条 NVLink 链路,这些链路允许 GPU 之间进行高速通信。在 DGX-1 P100 中,GPU 卡被组织成两个 cube mesh,每个 cube 包含 4 个 GPU(GPU 0~3 和 GPU 4~7)。在每个 cube 内部,GPU 之间可以直接通过 NVLink 或通过 PCIe Switch 进行通信。然而,跨 cube 的通信(例如 GPU 0 和 GPU 4)需要通过其他 GPU 间接进行。
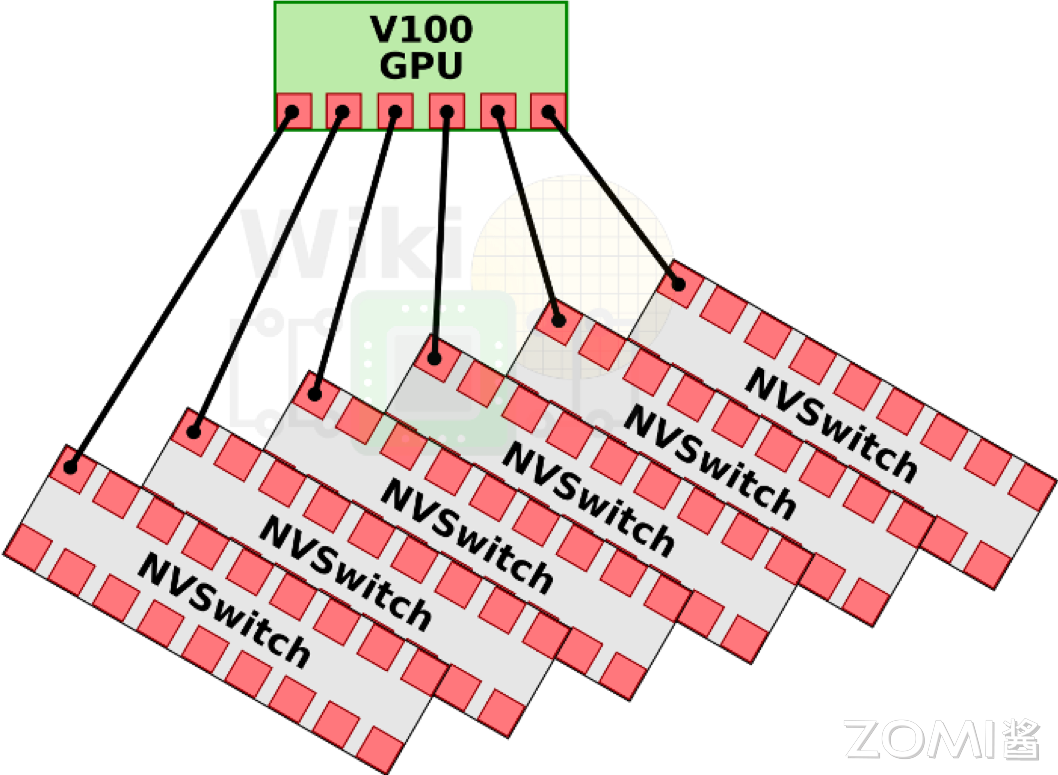
DGX-2 引入了英伟达的第一代 NVSwitch 技术,这是一个重要的进步,因为它允许更高效的 GPU 间通信。在 Volta 架构中,每张 GPU 卡支持 6 条 NVLink 链路,而不再是 4 条。此外,通过引入 6 个 NVSwitch,NVSwitch 能够将服务器中的所有 GPU 卡全部互联起来,并且支持 8 对 GPU 同时通信,不再需要任何中间 GPU 跳数,实现直接高速通信,这大大提高了数据传输的效率和整体计算性能。
DGX-A100 使用的是第二代 NVSwitch 技术。相比于第一代,第二代 NVSwitch 提供了更高的通信带宽和更低的通信延迟。在 A100 架构中,每张 GPU 卡支持 12 条 NVLink(第三代)链路,并通过 6 个 NVSwitch 实现了全连接的网络拓扑。虽然标准的 DGX A100 配置仅包含 8 块 GPU 卡,但该系统可以扩展,支持更多的 A100 GPU 卡和 NVSwitch,以构建更大规模的超级计算机。
DGX-H100 使用的是第三代 NVSwitch 和第四代 NVLink 技术,其中每一个 GPU 卡支持 18 条 NVLink 链路。在 H100 架构中,通过引入了 4 个 NV Switch,采用了分层拓扑的方式,每张卡向第一个 NV Switch 接入 5 条链路,第二个 NV Switch 接入 4 条链路,第三个 NV Switch 接入 4 条链路,第四个 NV Switch 接入 5 条链路,总共 72 个 NVLink 提供 3.6 TB/s 全双工 NVLink 网络带宽,比上一代提高 1.5 倍。
第一代 NVSwitch 支持 18 路接口,NVSwitch 能够支持多达 16 个 GPU 的全互联,实现高效的数据共享和通信。
第一代的 NVSwitch 支持的 NVLink 2.0 技术,每个接口能够提供双通道,高达 50GB/s 的带宽。这意味着通过 NVSwitch,整个系统能够实现总计 900GB/s 的惊人带宽,极大地提升了数据传输速率和计算效率。
其次,NVSwitch 基于台积电的 12nm FinFET FFN 工艺制造,这种先进的工艺技术使得 NVSwitch 能够在 100W 的功率下运行,同时集成了高达 2 亿个晶体管。
在 NVSwitch 架构中,任意一对 GPU 都可以直接互联,且只要不超过六个 NVLink 的总带宽,单个 GPU 的流量就可以实现非阻塞传输。这也就意味着,NVSwitch 支持的全互联架构意味着系统可以轻松扩展,以支持更多的 GPU,而不会牺牲性能。每个 GPU 都能利用 NVLink 提供的高带宽,实现快速的数据交换。
NVSwitch 在解决多 GPU 间的互联有以下优势和特性:
扩展性与可伸缩性:NVSwitch 的引入为 GPU 集群的扩展性提供了强大的支持。通过简单地添加更多的 NVSwitch,系统可以轻松地支持更多的 GPU,从而扩展计算能力。
高效的系统构建:例如,8个 GPU 可以通过三个 NVSwitch 构建成一个高效的互连网络(8个GPU对应8*6=48个接口,所以需要48/16=3个NVSwitch)。这种设计允许数据在所有 GPU 链路之间自由交互,最大化了数据流通的灵活性和效率。
全双向带宽利用:在这种配置下,任意一对 GPU 都能够利用完整的 300 GBps 双向带宽进行通信。这意味着每个 GPU 对都能实现高速、低延迟的数据传输,极大地提升了计算任务的处理速度。
无阻塞通信:NVSwitch 中的交叉开关(XBAR)为数据传输提供了从点 A 到点 B 的唯一路径。这种设计确保了通信过程中的无阻塞和无干扰,进一步提升了数据传输的可靠性和系统的整体性能。
优化的网络拓扑:NVSwitch 支持的网络拓扑结构为构建大型 GPU 集群提供了优化的解决方案。它允许系统设计者根据具体的计算需求,灵活地配置 GPU 之间的连接方式。
这里贴一个8卡A100的测试结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 nvidia-smi topo -m0 -31 ,64 -95 0 N/A0 -31 ,64 -95 0 N/A0 -31 ,64 -95 0 N/A0 -31 ,64 -95 0 N/A32 -63 ,96 -127 1 N/A32 -63 ,96 -127 1 N/A32 -63 ,96 -127 1 N/A32 -63 ,96 -127 1 N/Aas well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)as well as the interconnect between PCIe Host Bridges within a NUMA nodeas well as a PCIe Host Bridge (typically the CPU)
参考资料