【Picotron-Tutorial】Tensor并行
理论分析
分析的对象 $$Y=X@W$$
列并行
需要给每个GPU都复制一份X(往往都是早就有了),然后对于W进行列维度的切分。最后每个GPU会有不同列的结果,最后会对其进行all_gather拼接得到结果。
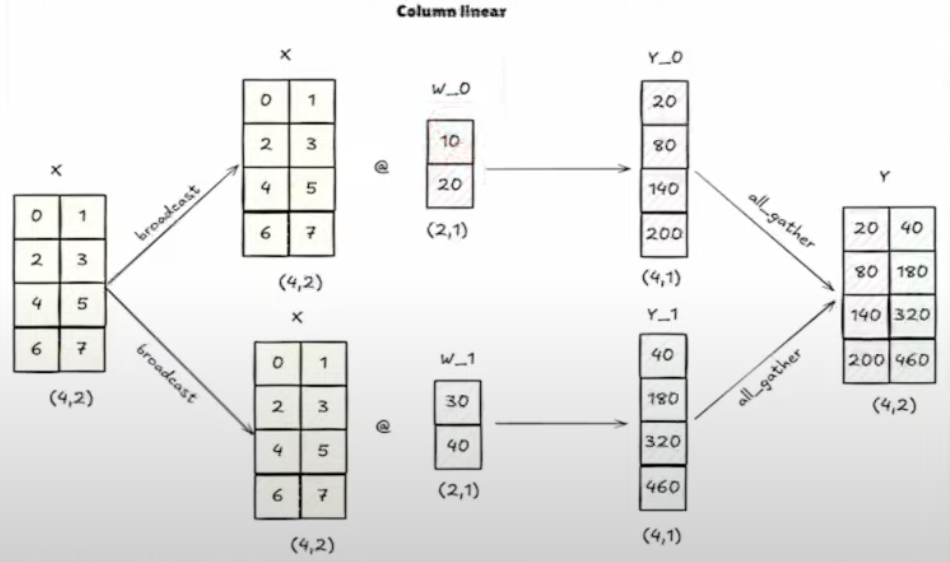
行并行
对于行并行,由于W的行数减小了,所以X的列数也要跟着变,所以首先需要将X进行列维度的拆分,划分到各个GPU卡上,然后与W进行相乘,得到的结果再进行all_reduce。
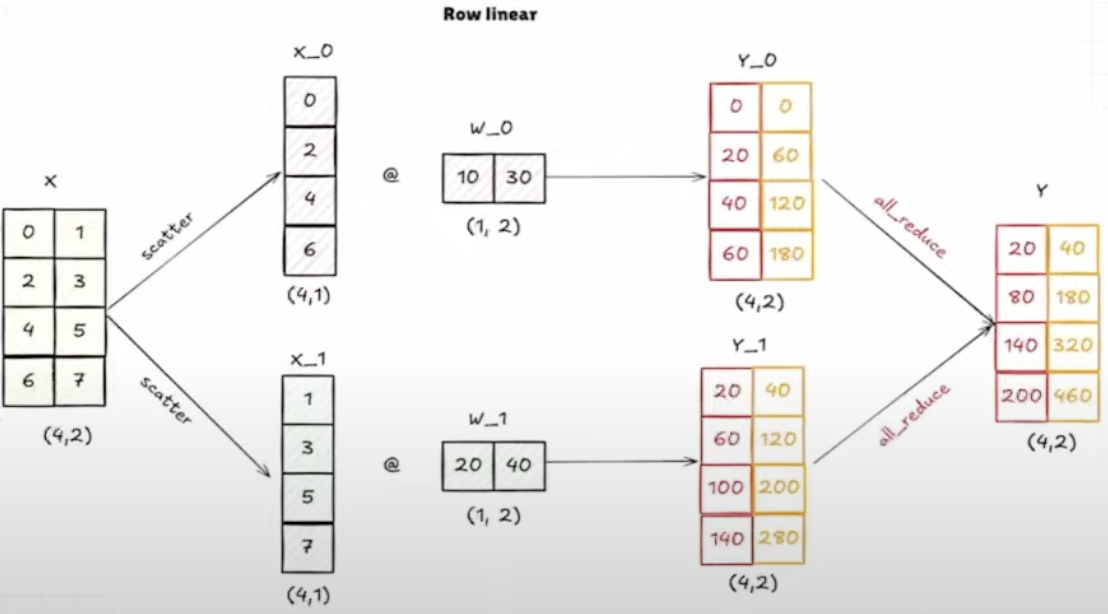
MLP模块的Tensor并行策略
以大模型中的MLP模块为例,其结构往往为
矩阵乘
Gelu
矩阵乘
所以如何设置tensor并行的策略就非常重要。
首先由于我们希望将gelu操作与一开始的矩阵乘操作放在一起运算,而行并行中最后会通过all_reduce进行一次相加,由于 Gelu(Y_0)+Gelu(Y_1) != Gelu(Y_0+Y_1),所以行并行并不能满足要求。而列并行中最后只是简单的拼接,所以还是可以做到的。所以一开始我们需要选择列并行。
然后需要讨论队后一个矩阵乘,我们需要选择什么矩阵并行的方法:
- 如果采用列并行,那么我们就需要先进行一次all_gather操作得到结果,然后再broadcast给各个卡,最后再将结果进行all_gather汇聚在一起,注意这里相当于产生了3个通信操作。
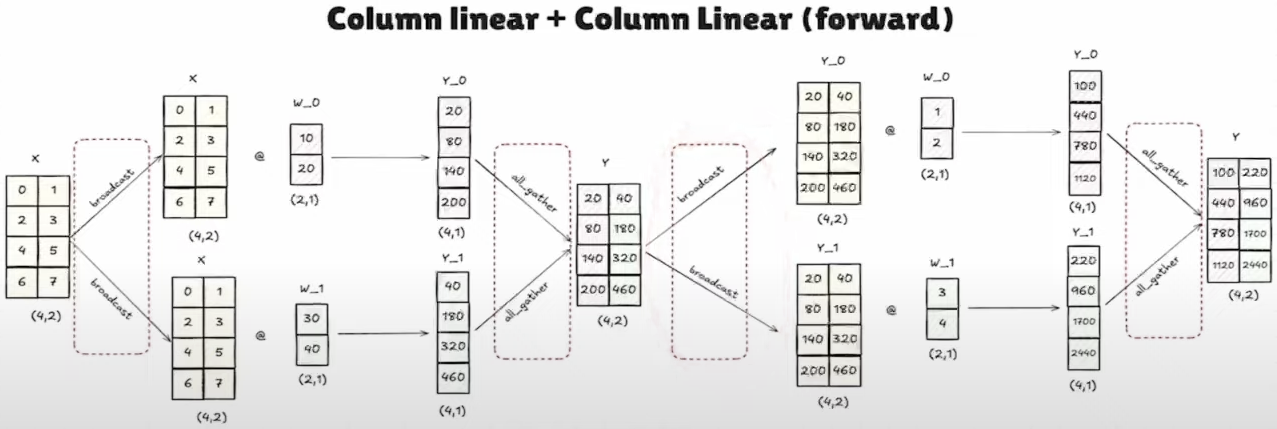
- 如果采用行并行,那么就不需要中间的进行结果汇聚的操作了,直接进行行并行的计算然后再进行all_reduce即可。注意这样做的话我们就只需要一次通信即可。
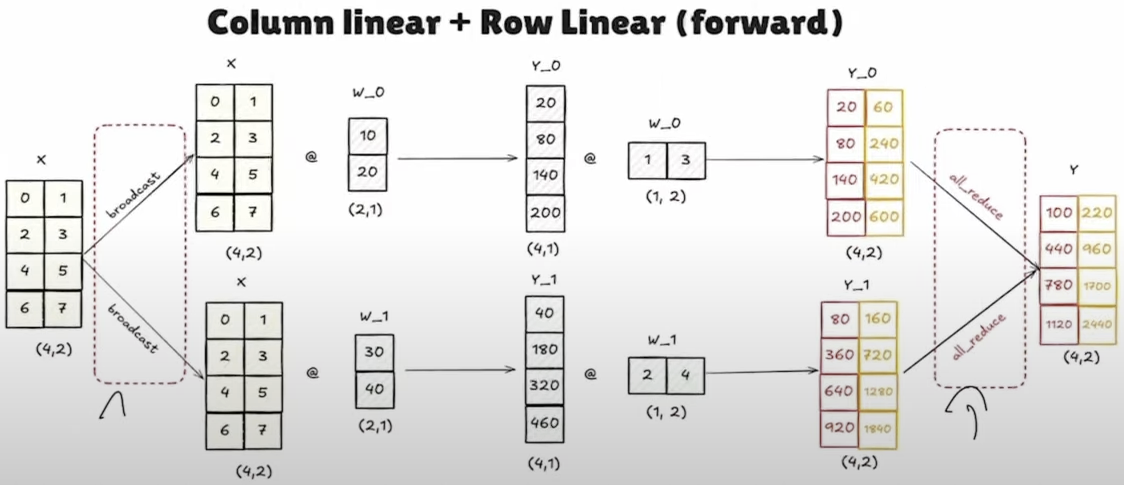
综上,最后采取列并行+行并行的矩阵并行运算的方法才是最合适的方法。
Attention模块的Tensor并行策略
attention模块内主要的计算步骤如下:
- 与W_q, W_k, W_v进行矩阵乘得到Q、K、V
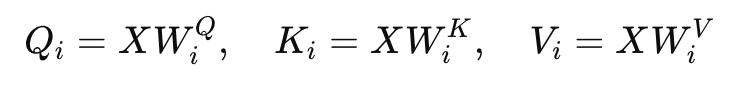
- 得到各个注意力头的attention输出
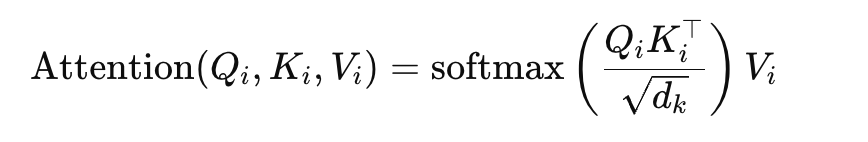
- 拼接各个attention,然后与W矩阵相乘得到最终的attention
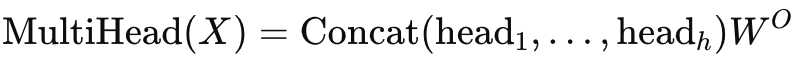
其实整体与MLP模块的分析类似,我们会先采取列并行的方式来划分W_q, W_k, W_v,然后采用行并行的方式来划分W_o,这样最后计算的时候就不需要汇总了,而是直接计算即可。
Embedding的Tensor并行策略
Embedding层的主要作用是通过各个token的id去embedding矩阵中获取对应的行作为输入。
所以在进行tensor并行的时候,只能对embedding矩阵采取行并行的切分方法,但是注意我们不会对输入进行切分,具体在使用的时候还会有一些其他的注意事项。
由于每块GPU只有不同id范围的embedding,所以我们首先需要将各个token对id减去embedding矩阵的起始位置,得到新的坐标
然后得到所有不在当前范围内的token的坐标,并将这些坐标mask成0
然后依据一般的embedding获取的规则去获取所有token对应的embeddings
然后再将所有超出范围的token的坐标对应的embeddings层化为0
最后将各个GPU上的embeddings层进行all_reduce即可得到最后的结果
代码分析
概览
首先调用apply_tensor_parallel函数来替换model中的部分层为矩阵并行的层。这里是直接写死各个层需要用什么并行方式。其整体来说就是先进行列并行然后再进行行并行,从而节省了中间的通信操作。
1 | |
列并行实现
其在初始化参数的时候会先按照原先的形状进行初始化,然后再将其按照并行维度进行划分,然后取自己rank对应的数据。需要注意对于矩阵乘,pytorch实现的时候是用X@W^T,所以对于列并行,实际上是会对W进行行并行。
收集结果的时候是用all_gather
1 | |
行并行实现
与列并行基本一致,就是在实现的时候是对W的列进行划分,收集结果的时候是用All_reduce。
1 | |
Embedding并行
与之前谈论的类似,先得到input_mask,然后再将input id减去start id得到masked_input,然后将input_mask对应位置的mask_input标记为0,得到embedding的结果后,再将mask_input对应位置标记为0,最后进行reduce得到结果。
1 | |