深度学习中反向传播及优化器使用详解
反向传播
偏导数
参考资料:
简要说明:
对于复合函数,如果要求其对于某一个参数的偏导数,那么就需要把其他参数看为常数,然后求导。
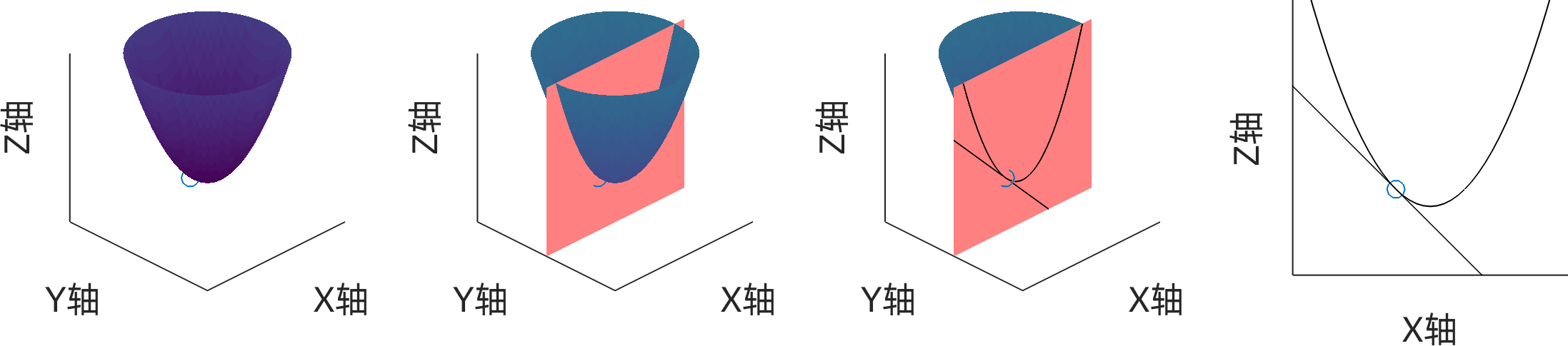
几何意义:可以认为是沿着某一个轴的导数。如下图所示,对于曲面 $z=f(x,y)$对x的偏导就是求这个曲面上的某点对于x轴的斜率。
全微分
参考资料:
简要说明:
对于多元函数,若每个参数都进行微小的变化,那么整个函数的z变化就是:$\mathrm{d}z=\sum_{i=1}^N\frac{\partial f}{\partial x_i}\mathrm{d}x_i$
几何意义:对于曲面 $z=f(x,y)$,若它在 $(x_0, y_0)$附近的曲面光滑,那么考虑一个足够小的区域,可以把这附近近似为一个平面,若在$x$与$y$方向都都进行小幅的移动,则$z$的增量就等于先在$x$方向进行移动的增量再加上$y$方向移动的增量。
链式法则
参考资料:
简要说明:
证明:
假设现在有函数: $z(x,y)=f[u(x,y),v(x,y)]$
根据全微分关系有: $\mathrm{d}z=\frac{\partial f}{\partial u}\operatorname{d}u+\frac{\partial f}{\partial v}\operatorname{d}v$
对于 $du、dv$又有:$\mathrm{d}u=\frac{\partial u}{\partial x}\mathrm{d}x+\frac{\partial u}{\partial y}\mathrm{d}y, F\quad\mathrm{d}v=\frac{\partial v}{\partial x}\mathrm{d}x+\frac{\partial v}{\partial y}\mathrm{d}y$
带入可得: $\begin{gathered}
\mathbf{d}z=\frac{\partial f}{\partial u}{\left(\frac{\partial u}{\partial x}\right.}\mathrm{d}x+\frac{\partial u}{\partial y}\left.\mathrm{d}y\right)+\frac{\partial f}{\partial v}{\left(\frac{\partial v}{\partial x}\right.}\mathrm{d}x+\frac{\partial v}{\partial y}\left.\mathrm{d}y\right) \ =\left(\frac{\partial f}{\partial u}\frac{\partial u}{\partial x}+\frac{\partial f}{\partial v}\frac{\partial v}{\partial x}\right)\mathrm{d}x+\left(\frac{\partial f}{\partial u}\frac{\partial u}{\partial y}+\frac{\partial f}{\partial v}\frac{\partial v}{\partial y}\right)\mathrm{d}y
\end{gathered}$根据全微分的定义就可以得到: $\begin{aligned}
\frac{\partial z}{\partial x} & =\frac{\partial f}{\partial u}\frac{\partial u}{\partial x}+\frac{\partial f}{\partial v}\frac{\partial v}{\partial x}, \
\
\frac{\partial z}{\partial y} & =\frac{\partial f}{\partial u}\frac{\partial u}{\partial y}+\frac{\partial f}{\partial v}\frac{\partial v}{\partial y}\mathrm{~.}
\end{aligned}$拓展到任意多变量的情况: $z(x_1,\ldots,x_N)=f[u_1(x_1,\ldots,x_N),\ldots,u_M(x_1,\ldots,x_N)]$
我们就可以得到链式法则:$\Large\frac{\partial z}{\partial x_i}=\sum_j\frac{\partial f}{\partial u_j}\frac{\partial u_j}{\partial x_i}$
举例分析
假设现在有一个计算式为 $e=(a+b)(b+1)$,可以首先取 $c=a+b,d=b+1$,从而将其转化为 $e=cd$,然后根据链式法则可以求b的偏导: $\frac{\partial e}{\partial b}=\frac{\partial e}{\partial c}\frac{\partial c}{\partial b}+\frac{\partial e}{\partial d}\frac{\partial d}{\partial b}=d1+c1=(b+1)+(a+b)$。
取 $a=3, b=2$,将计算图绘制如下:
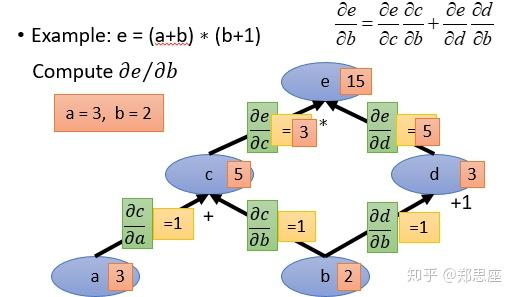
该图中是将数值作为了节点,将运算符作为了边。注意也有一些说法是反过来的。
在计算图中我们可以将各个变量的值计算出来,然后进行反向传播,计算去其对于各个变量的偏导数。对于 $b$,带入链式法则的公司,得到其偏导为 $\frac{\partial e}{\partial b}=\frac{\partial e}{\partial c}\frac{\partial c}{\partial b}+\frac{\partial e}{\partial d}\frac{\partial d}{\partial b}=31+51=8$。
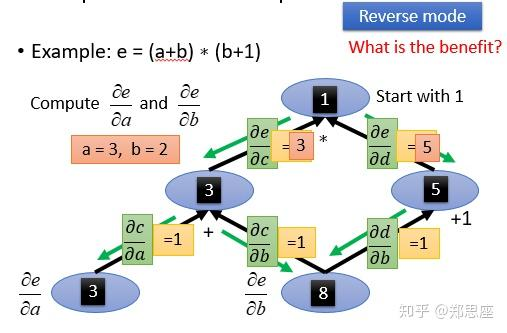
带入计算图中可以更为简单地理解为其偏导就是各个链路的偏导乘积的和。所以如果我们需要同时计算 $a$和 $b$的偏导,我们可以将e节点认定为1,然后进行反向传播,求出各节点的偏导,然后进行复用,如下图所示:
举例pytorch验证
使用pytorch实现上述的计算式,如下,最后的输出与我们上述分析的一致。
1 | |
优化器
上述我们知道了如何计算梯度,但是在实际的深度学习中,我们往往还需要构建模型,然后利用优化器对模型参数进行更新。
所以进一步,我们需要:
把
b设为“模型参数”(可优化的变量);将
e = (a + b)(b + 1)作为模型的“前向计算”;定义损失函数(比如
loss = e ** 2,希望e趋近于 0);使用
optimizer优化变量b。
完整代码及输出如下:
1 | |
注意我们这里定义了 $loss=e^2$,所以在原计算图的最上面会多出一个节点,然后会多出一条边,这条边对应的偏导是 $\frac{\partial loss}{\partial e}=2e$。
对于Epoch 1,手动计算其相对于 $b$的导数为 $2e\frac{\partial e}{\partial b}=2158=240$。然后因为采取的是SGD且学习率为0.01,所以更新 $b = 2 - 0.01240= -0.4$。
而一般来说,我们会将其封装成模型进行使用,如下所示:
1 | |