【Picotron-Tutorial】数据并行
原生数据并行
理论分析
在原生的数据并行中,每个数据并行的组都会自己处理自己的数据,这带来的一个问题在于我们需要及时同步训练过程中的梯度以及优化器的状态。
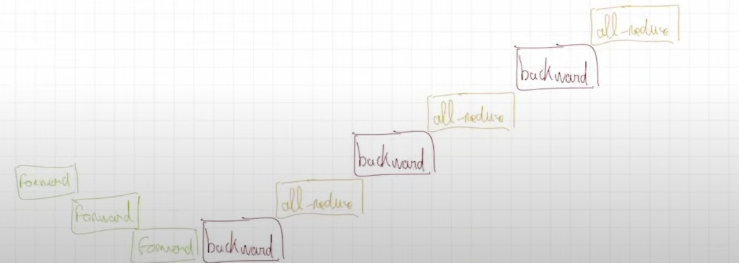
最原生的方法就是我们在前向传播后,在对每一个层进行反向传播后进行一次同步,如下图所示。由于梯度得到了及时的同步,所有优化器的状态自然也就会变得相同。
代码分析
- 修改
dataloader为分布式,从而使得每个dp进程每次获取到的数据batch是不相同的,其主要修改是加入DistributedSampler:
1 | |
- 对于原本的model需要包裹一个DataParallelNaive,即:
model = DataParallelNaive(model),这一层包裹会给每一个需要计算梯度的参数注册一个勾子函数,该函数的作用是如果model的require_backward_grad_sync=true,那么就会进行一次all_reduce获取到其他进程上的参数,然后进行平均,得到平均参数,如下:
1 | |
- 修改原本的训练进程,添加一段对于
model.require_backward_grad_sync赋值的控制,使得在最后一个dataloader.grad_acc_steps时会进行梯度平均。
1 | |
带bucket的数据并行
理论分析
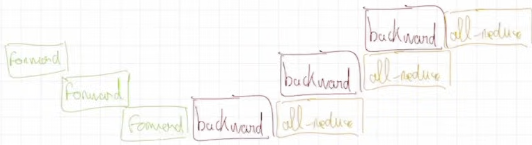
对于原生的数据并行,其最大的问题在于每层进行一次反向传播的时候都需要一个网络传输,这导致整体的速度被拖慢了。所以有提出带bucket带数据并行的方案,其特点在于将多层作为一个bucket,然后在反向传播时,只有当bucket中的所有反向传播都结束的时候才进行一次同步,同时设置该同步为异步的同步,这样就不会阻塞整体的反向传播的进程了。
代码分析
主要是需要构建3个类:
Bucket
BucketManager
DataParallelBucket
Bucket
Bucket 类代表一个梯度桶,它管理一组模型参数及其对应的梯度,并负责这些梯度的同步。
其包含了一个grad_data来存储梯度信息,这个grad_data由多个参数的grad拼接而成。
然后有一个params_with_grad_ready来记录哪些对应的参数已经完成了梯度计算,并通过一个函数来支持标记params_with_grad_ready。如果对应的参数都完成梯度计算后,它支持通过异步的all-reduce操作来同步梯度,并支持通过wait函数来等待梯度同步完成。
1 | |
BucketManager
BucketManager 负责将模型的所有参数划分到多个 Bucket 中,并管理这些桶。
用户需要指定每个桶的最大容量,以元素数量记。
会遍历模型中的各个参数,尝试将其放入桶中,如果放入不了就再新建一个桶放入
然后为每个桶创建一个连续内存来存储梯度,并将其与参数的grad进行映射,保障两个修改是同步的
支持标记param梯度计算完毕并将消息传递给对应的桶
支持等待所有的桶都同步完成
1 | |
DataParallelBucket
这是梯度分桶数据并行策略的顶层封装,它继承自 nn.Module ,可以像普通的 PyTorch模块一样使用。它主要用来包装原始的model。
它负责初始化bucketManager
给各个参数注册一个勾子函数,其负责
累加梯度到main_grad
如果是acc_grad中的最后一个计算,就:
注册一个post_backward函数,该函数会在在整个反向传播结束后被调用,其负责等待桶中所有的梯度同步完成,然后将同步后的梯度 (存储在 param.main_grad) 复制回 param.grad,以便优化器使用。
还会告诉bucketManager参数已经准备好,从而让bucketManager判断是否需要开始收集各个参数的grad
1 | |