【Picotron-Tutorial】上下文并行
理论分析
上下文并行的核心思想是将序列并行的方法(也就是沿序列长度进行拆分)的思路应用到已经采用张量并行的模块上。
对于上下文并行,就像序列并行一样,我们将沿序列维度拆分输入,但这次我们对整个模型进行拆分,而不仅仅是对之前Tensor+Sequence并行中涉及的部分模型。
拆分序列是横向的切割,所以不会影响大多数模块,如MLP和LayerNorm,因为它们对每个token的处理是独立的。
在计算梯度后,会启动一次all-reduce操作以在上下文并行组内同步梯度。
不过注意力模块需要特别注意,在注意力模块中,每个token需要访问来自所有其他序列token的键/值对,或者在因果注意力的情况下,至少需要关注每个前面的token。
由于上下文并行是沿序列维度将输入分布到各个GPU上,注意力模块将需要各个GPU之间进行充分通信,以交换必要的键/值数据。为了降低通信的影响衍生了各种同步方式。
环形注意力(Ring Attention)
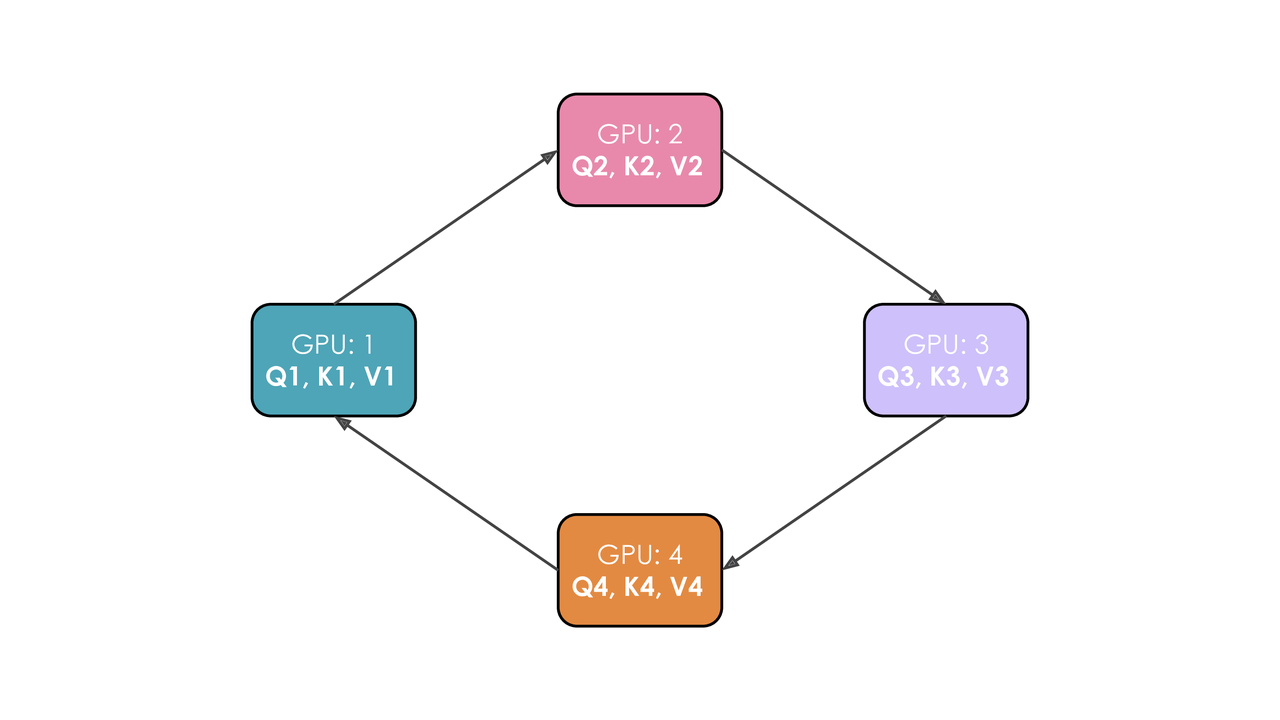
假设我们有4个GPU和4个token的输入。最初,输入序列沿序列维度均匀拆分,因此每个GPU仅拥有一个token及其对应的Q/K/V值。
假设Q1、K1和V1分别表示第一个token的查询、键和值,并且它们位于第1个GPU上。
注意力计算需要4个时间步来完成。在每个时间步中,每个GPU依次执行以下三个操作:
以非阻塞的方式将“当前的键和值”发送给下一台机器(在非阻塞模式下的最后一个时间步除外),以便在此步骤尚未完成时即可开始下一步骤
在本地对已拥有的“当前键和值”计算注意力得分,这通常涉及执行 $$\frac{Softmax(QK^T)}{\sqrt[]{d}}∗V$$
等待接收来自上一台GPU的键和值,然后返回到步骤1,此时“当前的键和值”即为刚刚从上一台GPU接收到的键/值对。
不过有一个大问题,那就是环形注意力的简单实现会导致因果注意力矩阵形状造成的GPU间工作不平衡。让我们通过考虑带有因果注意力掩码的注意力得分矩阵来观察Softmax计算:
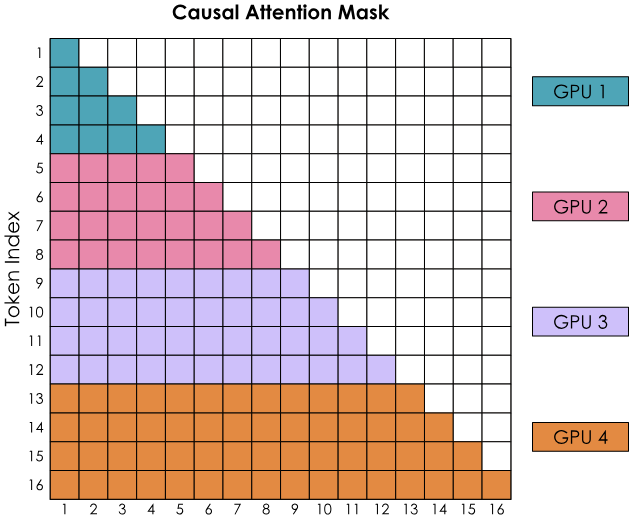
Softmax是按行计算的,这意味着每当一个GPU收到一整行的所有token时,就可以进行计算。我们看到GPU1可以立即计算,因为它一开始就拥有token 1-4,而GPU1实际上不需要从其他GPU接收任何信息。然而,GPU2需要等待第二轮,才能收到token 1-4,从而获得token 1-8的所有值。同时,GPU1的工作量明显比其他GPU要少得多。
之字形环形注意力(Zig-Zag Ring Attention) – 平衡计算的实现
为了更好地平衡计算负载,我们需要一种更好的方式来分配输入序列。
这可以通过不将token纯粹顺序地分配给各个GPU,而是稍微混合一下顺序,从而使每个GPU上都有较早和较晚的token。这种方法被称为之字形注意力,在这种新排列中,注意力掩码将显示出计算分布较为均匀。
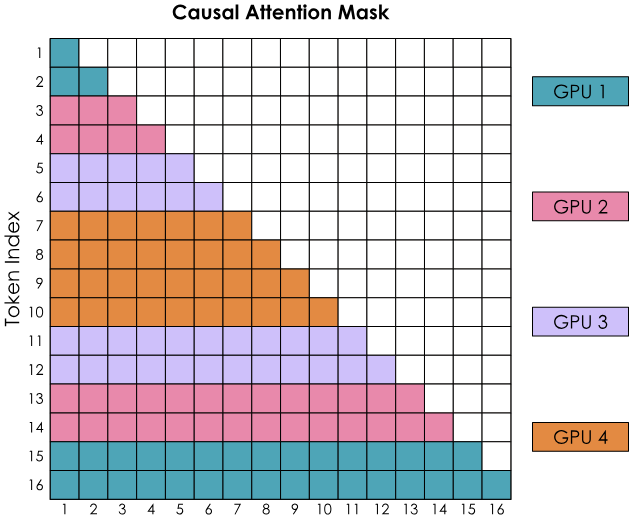
与此同时,我们也会看到,为了完成所有行的计算,每个GPU都需要来自其他所有GPU的信息。
我们有两种常见方式来重叠计算和通信:一种是通过执行一次通用的all-gather操作,同时在每个GPU上重新组合所有KV(类似于Zero-3的方式);另一种是根据需要从每个GPU逐个收集KV对:
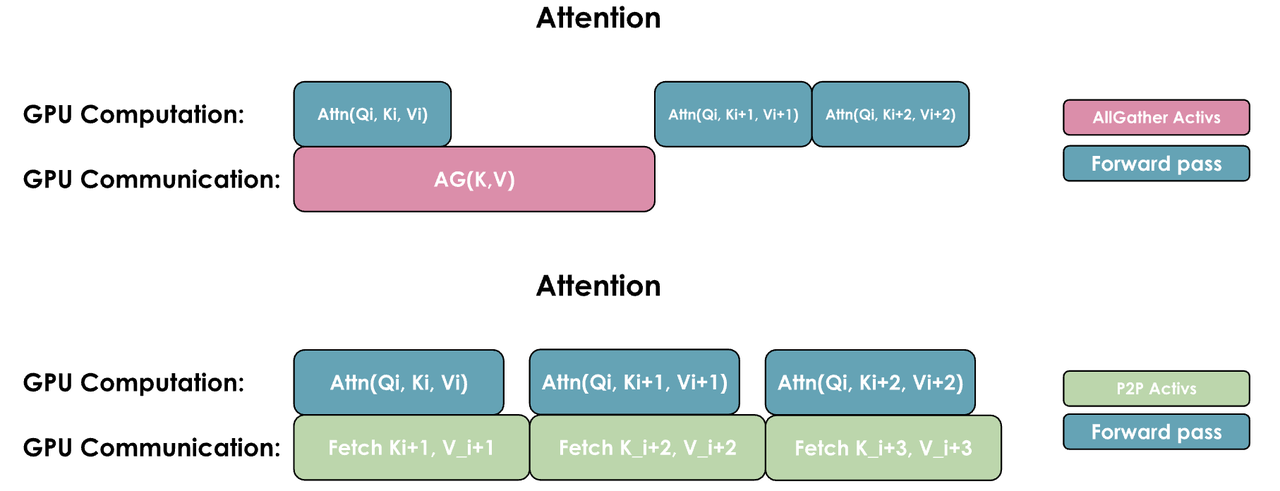
这两种实现方式的关键区别在于它们的通信模式和内存使用:
- AllGather实现:
所有GPU同时收集来自其他所有GPU的完整键/值对
需要更多的临时内存,因为每个GPU需要一次性存储完整的KV对
通信在一步内完成,但伴随较大的内存开销
- 全对全(环形)实现:
GPU以环形模式交换KV对,每次传输一个数据块
更节省内存,因为每个GPU只需临时存储一个数据块
通信被分散并与计算重叠,尽管由于多次通信步骤会带来一些额外的基础延迟
全对全方法通常在内存效率上更优,但其通信模式稍显复杂;而AllGather方法则更简单,但在注意力计算过程中需要更多的临时内存。
代码分析
ContextCommunicate
初始化时有点对点的send_rank和recv_rank。
对于send_recv函数,会创建一个异步的send_operation和recv_operation。然后会将这两个添加到_pending_operations中。
对于commit函数会批量提交所有_pending_operations中待处理的操作。
对于wait函数,它会等待所有已提交的任务都完成。
RingAttentionFunc
这里主要实现的是环形注意力机制。
如果有Context parrallel那么就会通过apply_context_parallel设置环境变量”CONTEXT_PARALLEL”,然后根据环境变量在attention计算的时候如果是Context parrallel就会执行ring_attention(q, k, v, sm_scale, is_causal)函数。
对于forward,它会遍历所有的world_size来依次进行处理:
如果不是最后一次,那么就对k、v执行send_recv,得到next_k、next_v,然后commit。
如果step <= comm.rank,那就说明当前的数据是在attention计算中是需要的。那么就调用ring_attention_forward来执行部分序列数据的标准的attention的计算
然后调用update_out_and_lse来执行对这种部分序列的attention的累计更新
如果不是最后一次,那么就将k、v替换为刚通过网络传输得到的next_k和next_v
对于backward,首先会创建两个通信组ContextCommunicate,主要用于 K, V 环形通信的通信对象和 K, V 梯度的环形通信的通信对象,同样也是遍历world_size次来依次处理
如果不是最后一次,那么就对k、v执行send_recv,得到next_k、next_v,然后commit。
如果当前step<=kv_comm.rank,那么就需要通过ring_attention_backward计算梯度,这里实际上是在手动计算反向传播出来的梯度。
得到梯度dq,还需要等待d_kv_comm,得到dk、dv
更新k、v为next_k、next_v
将dq、dv通过send_recv发送给下一个并进行接收
update_rope_for_context_parallel
由于现在每个GPU只有一部分的序列,所以在计算位置编码的时候不能依赖原始的位置,而是要加上当前rank之前的的。