专有名词解释
warp:对模型进行包裹,使其具备fsdp的相关的分布式能力
shard: 对参数进行切分,得到每个rank sharded的参数
unshard: 将切分的参数allgather,得到完整的参数
reshard:将完整的参数释放,只保留每个rank的sharded的参数
sharded:切分后的参数
unsharded:完整的参数
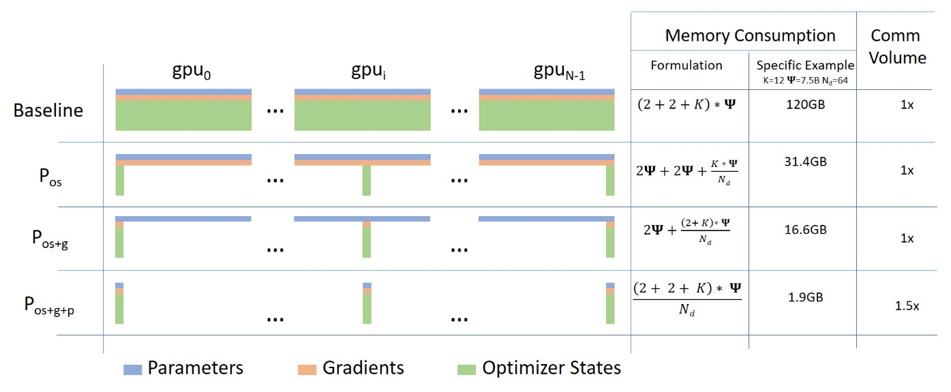
fsdp概览 如下图所示,首先对于Zero算法来说:
Zero-1切分了优化器状态
Zero-2切分了优化器状态和梯度
Zero-3切分了优化器状态和梯度和参数
对于fsdp来说,它实际上就是Zero-3。传统的数据并行会在每个GPU上维护一份模型参数,梯度,优化器状态的副本,但是FSDP将这些状态分片到所有的数据并行worker中,并且可以选择将分片的模型参数卸载到CPU上,从而使得若现在有 $n$个GPU,某一层的参数量为 $m$,那么每个GPU会维护这一层 $m/n$个参数。
通常,模型层以嵌套方式用 FSDP 包装,因此在前向或后向计算期间,只有单个 FSDP 实例中的层需要将完整参数收集到单个设备。聚合到的完整参数会在计算后立即释放,释放的内存可以用于下一层的计算。通过这种方式,可以节省峰值 GPU 内存,因此可以扩展训练以使用更大的模型大小或更大的批量大小。为了进一步最大化内存效率,当实例在计算中不活动时,FSDP 可以将参数、梯度和优化器状态卸载到 CPU。
使用示例 如下是一个使用示例,简单来说有这几个关键步骤:
定义自动 wrap 策略:只 wrap nn.Linear层
将模型用FSDP进行包裹,从而转变为fsdp_model
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 import osimport torchimport torch.nn as nnimport torch.optim as optimfrom torch.distributed.fsdp import FullyShardedDataParallel as FSDPfrom torch.distributed.fsdp.wrap import lambda_auto_wrap_policyfrom torch.distributed.fsdp import ShardingStrategyimport torch.distributed as distimport torch.multiprocessing as mpfrom torch.nn.parallel import DistributedDataParallel as DDPfrom torch.distributed.fsdp.wrap import lambda_auto_wrap_policyfrom functools import partialdef my_wrap_criteria (module ):return isinstance (module, nn.Linear)class Net (nn.Module):def __init__ (self, H ):super (Net, self).__init__()False )False )False )False )False )def forward (self, x ):return xdef main ():int (os.environ["RANK" ])int (os.environ["WORLD_SIZE" ])int (os.environ["LOCAL_RANK" ])"nccl" , rank=rank, world_size=world_size)512 print ("fsdp_model:" , fsdp_model)1e-3 )32 , H).cuda()32 , H).cuda()for epoch in range (3 ):print (f"[Rank {rank} ] Epoch {epoch} Loss: {loss.item()} " )if __name__ == "__main__" :
fsdp初始化 1 2 class FullyShardedDataParallel (nn.Module, _FSDPState):
注意fsdp的初始化过程是“惰性”的(lazy),只有在forward调用的时候才会进行初始化,从而对模型进行shard。
Warp 具体的_auto_wrap的调用是在使用FullyShardedDataParallel包裹module后进行初始化的时候实现的,如下:
1 2 3 4 5 6 7 8 _auto_wrap(
判断模块是否需要划分的函数 pytorch中提供了多种对模型进行自动切分和包装的方法,下面介绍几个常用的:
CustomPolicy 这支持自定义包装策略,关键是允许通过lambda_fn来进行自定义。lambda_fn可以返回bool值,这代表和root执行同样的分片参数,也可以返回args,这代表自定义的分片参数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 class CustomPolicy (_Policy ):""" 功能: 这是一个高度灵活的 FSDP(Fully Sharded Data Parallel)自动包装策略。 它允许用户通过提供一个自定义的 lambda 函数来精确控制对哪个模块应用 FSDP 包装, 以及使用什么样的参数。 工作机制: 策略的核心是用户传入的 `lambda_fn`。FSDP 会遍历模型中的每一个模块,并用该模块 作为参数调用 `lambda_fn`。根据 `lambda_fn` 的返回值,决定如何操作: - 返回 `False`:不包装当前模块。 - 返回 `True`:使用 FSDP 的默认参数包装当前模块。 - 返回一个非空字典:包装当前模块,并使用该字典中的键值对来覆盖或补充 FSDP 的默认参数。 这允许为特定模块设置不同的分片策略(ShardingStrategy)或其他配置。 使用场景: 当你需要比 `ModuleWrapPolicy`(基于类名包装)更精细的控制时,此策略非常有用。 例如,你可能想为模型的大部分 Transformer 层使用默认包装,但为最后的输出层(如 lm_head) 指定一个不同的分片策略,或者完全不包装某个特定的层。 """ def __init__ (self, lambda_fn: Callable [[nn.Module], Union [bool , dict [str , Any ]]] ):""" 构造函数。 参数: - lambda_fn (Callable): 一个函数,它接受一个 `nn.Module` 实例作为输入, 并返回一个布尔值或一个字典,用于决定包装行为。 """ def _run_policy ( self, root_module: nn.Module, ignored_modules: set [nn.Module], root_kwargs: dict [str , Any ], ) -> dict [nn.Module, dict [str , Any ]]:""" (内部方法)执行策略的核心逻辑,遍历所有模块并应用 lambda 函数来决定包装方案。 参数: - root_module (nn.Module): 整个模型。 - ignored_modules (set[nn.Module]): 需要忽略的模块集合。 - root_kwargs (dict[str, Any]): 应用于根 FSDP 模块的参数,作为包装子模块时的默认参数。 返回: 一个字典,键是需要被包装的目标模块实例,值是应用于该模块的 FSDP 参数。 """ dict [nn.Module, dict [str , Any ]] = {}for module in root_module.modules():if module in ignored_modules:continue if not isinstance (res, (dict , bool )):raise ValueError(f"传递给 CustomPolicy 的 lambda_fn 应返回 " f"False/True 或一个 kwarg 字典,但它返回了 {res} " if not res:continue if isinstance (res, dict ):return target_module_to_kwargs
使用示例:
1 2 3 4 5 6 7 8 9 model = init_transformer_model(...)def lambda_fn (module: nn.Module ):if module is model.lm_head:return {"sharding_strategy" : ShardingStrategy.SHARD_GRAD_OP}elif isinstance (module, TransformerBlock):return True return False
Module结构学习 对于module,其记录子结构的变量为_modules: dict[str, Optional["Module"]],即对于函数:
1 self.block1 = SomeModule()
底层实际做了如下事情(在 setattr 中):
1 self._modules["block1" ] = SomeModule()
也就是说所有子模块都保存在 self._modules 中(有顺序的字典)。
这里调用了root_module.modules()来获取root_module的子modules(),该函数实际上就是用深度优先遍历的方式去遍历self._modules ,具体的方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 def modules (self ) -> Iterator["Module" ]:r"""返回一个遍历网络中所有模块的迭代器。 功能: - 这是一个便捷方法,用于获取模型及其所有子模块的实例,而不需要它们的名称。 - 它在内部调用 `self.named_modules()`,但忽略了每个元组中的名称部分。 产生: Module: 网络中的一个模块。 注意: 与 `named_modules` 一样,重复的模块实例默认只返回一次。在下面的例子中, `l` 只会被返回一次。 示例:: >>> l = nn.Linear(2, 2) >>> net = nn.Sequential(l, l) >>> for idx, m in enumerate(net.modules()): ... print(idx, '->', m) 0 -> Sequential( (0): Linear(in_features=2, out_features=2, bias=True) (1): Linear(in_features=2, out_features=2, bias=True) ) 1 -> Linear(in_features=2, out_features=2, bias=True) """ for _, module in self.named_modules():yield moduledef named_modules ( self, memo: Optional [set ["Module" ]] = None , prefix: str = "" , remove_duplicate: bool = True , r"""返回一个迭代器,该迭代器遍历网络中的所有模块,同时产生模块的名称和模块本身。 这是一个深度优先(pre-order,先序)的遍历。 参数: memo: 用于存储已添加到结果中的模块集合的备忘录。主要用于内部递归调用。 prefix: 将被添加到模块名称前面的前缀。主要用于内部递归调用。 remove_duplicate: 是否在结果中移除重复的模块实例。 产生: (str, Module): (名称, 模块) 的元组。 注意: 默认情况下,重复的模块只返回一次。在下面的例子中,`l` 只会被返回一次。 示例:: >>> l = nn.Linear(2, 2) >>> net = nn.Sequential(l, l) # net 中有两个对同一 l 实例的引用 >>> for idx, m in enumerate(net.named_modules()): ... print(idx, '->', m) 0 -> ('', Sequential( (0): Linear(in_features=2, out_features=2, bias=True) (1): Linear(in_features=2, out_features=2, bias=True) )) 1 -> ('0', Linear(in_features=2, out_features=2, bias=True)) # 注意:尽管有两个 l,但 ('1', l) 不会再次出现,因为 l 已经被访问过。 """ if memo is None :set ()if self not in memo:if remove_duplicate:yield prefix, selffor name, module in self._modules.items():if module is None :continue "." if prefix else "" ) + nameyield from module.named_modules(
这是transformer模型中比较常用的策略,主要就是自定义要划分的模块的类型,然后自动划分。具体使用的时候需要用functools.partial进行包装。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 def transformer_auto_wrap_policy ( module: nn.Module, recurse: bool , nonwrapped_numel: int , transformer_layer_cls: Set [Type [nn.Module]], bool :""" 功能: 这是一个专门为 Transformer 模型设计的便捷包装策略。它本质上是 `_module_wrap_policy` 的一个别名或封装。 目的: 提供一个语义上更清晰的函数名 (`transformer_auto_wrap_policy`),让用户在处理 Transformer 模型时, 能更直观地理解其作用。它特别适用于包装 Transformer 的编码器/解码器层(例如 `TransformerEncoderLayer`)。 要点: - 它直接调用 `_module_wrap_policy`,并将 `transformer_layer_cls` 作为 `module_classes` 传递过去。 - 正确地包装共享参数(如词嵌入层)非常重要,因为它们必须位于同一个 FSDP 实例中。 这个策略通过将所有指定的层(通常是 Transformer block)包装起来,有助于确保模型中其他部分(如共享的嵌入层) 最终被包含在更高层级的 FSDP 实例中,从而被正确处理。 """ return _module_wrap_policy(module, recurse, nonwrapped_numel, transformer_layer_cls)def _module_wrap_policy ( module: nn.Module, recurse: bool , nonwrapped_numel: int , module_classes: Set [Type [nn.Module]], bool :""" 功能: 这是一个核心的辅助函数,用于实现基于模块类的自动包装策略。 FSDP 的自动包装过程是一个从上到下(top-down)的遍历,但包装决策是从下到上(bottom-up)做出的。 此函数在这个过程中被调用,以决定是否应该包装当前的模块。 工作机制: 该函数的行为取决于 `recurse` 参数: 1. 当 `recurse=True` 时:表示 FSDP 正在递归地深入模块树(DFS 过程)。 在这种情况下,函数总是返回 `True`,告诉 FSDP 继续向下遍历,直到到达叶子模块或一个已经被包装的子模块。 2. 当 `recurse=False` 时:表示 FSDP 已经完成对当前模块所有子模块的遍历,现在需要对当前模块本身做出决策。 这时,函数会检查 `module` 是否是 `module_classes` 中指定的任何一个类的实例。 - 如果是,则返回 `True`,表示“请包装我这个模块”。 - 如果不是,则返回 `False`,表示“不要包装我,继续向上返回”。 参数: module (nn.Module): 当前正在被考虑的模块。 recurse (bool): 控制函数行为的标志。`True` 表示继续递归,`False` 表示需要做出包装决策。 nonwrapped_numel (int): 尚未被包装的参数数量(在此函数中未使用,但在其他更复杂的策略中可能有用)。 module_classes (Set[Type[nn.Module]]): 一个包含模块类的集合。任何属于这些类的模块都将被包装。 返回: 一个布尔值。如果 `recurse=True`,总是返回 `True`。如果 `recurse=False`,返回是否应该包装 `module`。 """ if recurse:return True return isinstance (module, tuple (module_classes))
使用示例:
1 2 3 4 5 6 7 fsdp_m = FSDP(True ,
具体进行自动划分 注意观察下面的函数中的fsdp_fn为FullyShardedDataParallel,即这个fsdp_fn的作用是把module包装成FullyShardedDataParallel类型。
这里有两种划分的调用方式:
如果 policy是 _Policy的实例(推荐方式),则使用策略对象来决定哪些模块需要被包装。
如果 policy 是一个可调用对象(旧版方式),则使用递归的方式进行包装。
暂时先只看第一种_Policy的实例的方法,其执行顺序如下:
执行_run_policy得到root_module下所有符合包装规则的module以及args
如果配置了混合精度就特殊处理一下
验证要包装的模块中的冻结参数(即 requires_grad=False 的参数)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 def _auto_wrap ( root_module: nn.Module, policy: Union [Callable , _Policy], ignored_modules: set [nn.Module], ignored_params: set [nn.Parameter], root_kwargs: dict [str , Any ], fsdp_fn: Callable , """ 根据 `policy`,以后序遍历的方式自动包装 `root_module` 模块树中的模块。 此函数是 FSDP 自动包装功能的核心入口。 它根据传入的 `policy` 类型,选择不同的包装逻辑: 1. 如果 `policy` 是 `_Policy` 的实例(推荐方式),则使用策略对象来决定哪些模块需要被包装。 2. 如果 `policy` 是一个可调用对象(旧版方式),则使用递归的方式进行包装。 前提条件: `root_kwargs` 应该包含除 `module` 之外的所有FSDP构造函数参数。 """ if isinstance (policy, _Policy):if root_kwargs.get("mixed_precision" ) is not None :"mixed_precision" ]._module_classes_to_ignore,"mixed_precision" ]._module_classes_to_ignoreset (target_module_to_kwargs.keys()),"use_orig_params" , False ),return "module" : root_module,"auto_wrap_policy" : policy,"wrapper_cls" : fsdp_fn,"ignored_modules" : ignored_modules,"ignored_params" : ignored_params,"only_wrap_children" : True , if root_kwargs.get("mixed_precision" ) is not None :"mixed_precision" ]._module_classes_to_ignore"mixed_precision" ]._module_classes_to_ignore,"auto_wrap_policy" ] = policy
_construct_wrap_fn&_post_order_apply 首先构建一个warp函数,该函数对于target model且不是root的会调用fsdp_fn执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 def _construct_wrap_fn ( root_module: nn.Module, target_module_to_kwargs: dict [nn.Module, dict [str , Any ]], fsdp_fn: Callable , Callable [[nn.Module], Optional [nn.Module]]:""" 此函数是一个高阶函数,它的作用是构建并返回一个"包装函数"(`fn`)。 这个返回的函数将被传递给 `_post_order_apply`,用于在后序遍历中实际应用FSDP包装。 功能: - 它利用闭包捕获 `root_module`、`target_module_to_kwargs` 和 `fsdp_fn`。 - 返回的 `fn` 封装了决定是否包装一个特定模块以及如何包装它的全部逻辑。 参数: - root_module (nn.Module): 模型的根模块,用于在包装时进行排除检查。 - target_module_to_kwargs (dict): 由包装策略生成的字典,指明了哪些模块需要被包装以及它们各自的FSDP配置。 - fsdp_fn (Callable): FSDP的包装器,如 `FullyShardedDataParallel` 类。 返回: - 一个可调用对象 `fn`,该函数接受一个模块作为输入,如果该模块需要被包装,则返回包装后的模块,否则返回 `None`。 """ def fn (module: nn.Module ) -> Optional [nn.Module]:""" 这个内部函数是实际执行替换逻辑的单元。 它会被 `_post_order_apply` 在遍历模型树时对每个模块调用。 """ if module in target_module_to_kwargs and module is not root_module:return fsdp_fn(module, **kwargs)return None return fn
然后对于_post_order_apply函数,他就是会执行上面构造的fn,然后以后序遍历的方式去遍历所有的子模块(注意不会替换root 模块),替换的方法就是setattr。
为什么要避免替换root呢,因为root这时候已经是FullyShardedDataParallel类型了,不需要重复进行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 def _post_order_apply ( root_module: nn.Module, fn: Callable [[nn.Module], Optional [nn.Module]], """ 此函数遵循后序遍历(post-order traversal)将 `fn` 应用于 `root_module` 模块树中的每个模块。 如果 `fn` 返回一个 :class:`nn.Module`,那么它将在树中用新返回的模块替换原始模块。 否则,`fn` 应返回 `None`,在这种情况下,模块不会被更改。 后序遍历意味着,对于任何给定的模块,函数 `fn` 会先被应用于其所有子模块,然后再应用于该模块本身。 参数: - root_module (nn.Module): 整个模型层级结构的根模块。 - fn (Callable[[nn.Module], Optional[nn.Module]]): 一个可调用对象,它接收一个模块作为输入。 - 如果需要替换该模块,则返回一个新的 nn.Module 实例。 - 如果不需要改变该模块,则返回 None。 """ set [nn.Module] = {root_module}def _post_order_apply_inner ( module: nn.Module, module_name: str , parent_module: Optional [nn.Module], ):for child_module_name, child_module in module.named_children():if child_module not in visited_modules:if optional_module is not None :assert isinstance (parent_module, nn.Module), (f"非根模块应该设置其父模块,但对于 {module} 得到了 {parent_module} " assert module_name, (f"非根模块应该设置其模块名称,但对于 {module} 得到了一个空模块名" assert isinstance (optional_module, nn.Module), (f"fn 应返回 None 或 nn.Module,但得到了 {optional_module} " setattr (parent_module, module_name, optional_module)"" , None )
初始化param_handle 在Warp之后,初始化param_handle的顶层调用:
1 2 3 4 5 6 7 _init_param_handle_from_module(
_init_param_handle_from_module 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 @no_type_check def _init_param_handle_from_module ( state: _FSDPState, fully_sharded_module: nn.Module, device_id: Optional [Union [int , torch.device]], param_init_fn: Optional [Callable [[nn.Module], None ]], sync_module_states: bool , """从一个模块 `fully_sharded_module` 初始化一个 `FlatParamHandle`。 `FlatParamHandle` 是 FSDP 的核心组件,它将模块的多个原始参数展平(flatten) 并合并成一个单一的、连续的 `FlatParameter`。这个函数负责完成这一过程。 """ "" if (is_meta_module or is_torchdistX_deferred_init) and param_init_fn is not None :elif is_meta_module:elif is_torchdistX_deferred_init:lambda submodule: _get_module_fsdp_state(submodule) is None and submodule not in state._ignored_modules,for ignored_module in state._ignored_modulesfor buffer in ignored_module.buffers()list (_get_orig_params(fully_sharded_module, state._ignored_params))if sync_module_states:if state.sharding_strategy in HYBRID_SHARDING_STRATEGIES:return state
_get_orig_params 得到fully_sharded_module中所有的参数,也就是tensor矩阵。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 def _get_orig_params ( module: nn.Module, ignored_params: set [nn.Parameter], """ 返回一个遍历 `module` 中原始参数的迭代器。 这个迭代器不会返回以下几种参数: 1. 在 `ignored_params` 集合中的参数。 2. 任何 `FlatParameter` 实例(这可能因为嵌套使用 FSDP 而出现)。 3. 任何已经被展平的原始参数(这只在 `use_orig_params=True` 模式下有意义)。 """ try :while True :next (param_gen)if param not in ignored_params and not _is_fsdp_flattened(param):yield paramexcept StopIteration:pass
_init_param_handle_from_params 注意初始化了FlatParamHandle后立刻进行了shard
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 @no_type_check def _init_param_handle_from_params ( state: _FSDPState, params: list [nn.Parameter], fully_sharded_module: nn.Module, if len (params) == 0 :return assert not state._handle"cpu" )if state.cpu_offload.offload_params and handle.flat_param.device != cpu_device:
FlatParamHandle 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 class FlatParamHandle :""" 一个管理扁平化参数(:class:`FlatParameter`)的句柄。 这包括分片和视图管理。 参数: params (Sequence[nn.Parameter]): 要被展平到扁平化参数中的参数序列。 fully_sharded_module (nn.Module): 被 FSDP 包装的模块。 device (torch.device): 计算和通信设备,通常是 GPU。 sharding_strategy (ShardingStrategy): 应用于此句柄的 `FlatParameter` 的分片策略。 offload_params (bool): 是否将此句柄的 `FlatParameter` 卸载到 CPU。 mp_param_dtype (Optional[torch.dtype]): 用于参数的混合精度类型。 mp_reduce_dtype (Optional[torch.dtype]): 用于梯度归约的混合精度类型。 keep_low_precision_grads (bool): 是否保持低精度的梯度。 use_orig_params (bool): 如果为 True,FSDP 会保留原始参数变量,并从 `named_parameters()` 返回它们。 这允许在同一个 `FlatParameter` 内对不同原始参数使用不同的优化器超参数。 如果为 False,FSDP 会在每次迭代中重新构建参数。 """ def __init__ ( self, params: Sequence [Union [nn.Parameter, Tensor]], fully_sharded_module: nn.Module, device: torch.device, sharding_strategy: HandleShardingStrategy, offload_params: bool , mp_param_dtype: Optional [torch.dtype], mp_reduce_dtype: Optional [torch.dtype], keep_low_precision_grads: bool , process_group: dist.ProcessGroup, use_orig_params: bool , *, fsdp_extension: Optional [FSDPExtensions] = None , ):super ().__init__()list (params)if len (params) == 0 :raise ValueError(f"不能用一个空的参数列表来构造 {self.__class__.__name__} " "" ) == "1" "" ) == "1" "" ) == "1" "" ) == "1" Optional [int ] = None False False False 0 ].dtypeassert self._fwd_bwd_param_dtype is not None if align_addresseselse 0 False )
这个方法是 FSDP 魔法的起点。它像一个高效的管家,将一堆零散的参数( params )整齐地排列、打包,并贴上详细的标签(元数据),最终形成一个易于管理的单一实体( FlatParameter )。这个过程不仅处理了复杂的共享参数和内存对齐问题,还为后续的分布式操作(如 reduce-scatter )做好了准备。一旦这个方法执行完毕, FlatParamHandle 就拥有了一个完整的、随时可以被分片和恢复的扁平化参数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 def _init_flat_param_and_metadata ( self, params: list [Union [Tensor, nn.Parameter]], module: nn.Module, aligned_numel: int , use_orig_params: bool , None :""" 初始化 ``FlatParameter`` 及其元数据。 注意:此方法只应在构造时调用一次,之后 ``FlatParameter`` 的元数据被假定为静态的。 """ if len (params) == 0 :raise ValueError("期望非空的 `params`" )if aligned_numel < 0 :raise ValueError(f"期望非负的 `aligned_numel` 但得到了 {aligned_numel} " set (params) list [ParamInfo] = [] list [int ] = [] list [torch.Size] = [] list [tuple [int , ...]] = [] list [str ] = [] list [SharedParamInfo] = [] dict [Union [Tensor, nn.Parameter], tuple [nn.Module, str , str ]list [Union [Tensor, nn.Parameter]] = [] list [Union [Tensor, nn.Parameter]] = [] list [bool ] = [] 0 for submodule_name, submodule in module.named_modules(remove_duplicate=False ):for param_name, param in _named_parameters_with_duplicates(False if param not in params_set:continue if param in shared_param_memo:else : if aligned_numel > 0 :if numel_to_pad > 0 and numel_to_pad < aligned_numel:False , deviceTrue )False )if aligned_numel > 0 :if numel_to_pad > 0 and numel_to_pad < self.world_size:False , deviceTrue )0 ,
flatten_tensors_into_flat_param 最后的结果就是进行了张量展开,获得了一个扁平的张量,形状为:[参数数量,参数长度]。即每个参数param都变成了一维,最后各个param都拼接在了一起。所以这些参数最后在物理地址上都是连续的,方便操作。
1 2 3 4 5 6 7 8 def flatten_tensors_into_flat_param ( self, tensors: list [Tensor], aligned_numel: int , requires_grad: bool , return FlatParameter(flat_param_data, requires_grad=requires_grad)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 def flatten_tensors ( self, tensors: list [Tensor], aligned_numel: int , """ 将 `tensors` 展平为单个扁平张量。 如果 `aligned_numel` 大于 0,展平过程会包含可选的填充, 其中 `aligned_numel` 给出了实现地址对齐所需的元素数量。 注意:填充对齐算法必须与 `_init_flat_param_metadata` 方法保持同步。 我们分离这两个方法是因为初始化只发生一次,而此方法可能在训练过程中 被多次调用(例如,用于保存检查点)。 """ if len (tensors) == 0 :raise ValueError("期望 `tensors` 列表不为空" )if aligned_numel < 0 :raise ValueError(f"期望 `aligned_numel` 为非负数,但得到了 {aligned_numel} " list [Tensor] = [] if aligned_numel > 0 :0 for tensor in tensors:if numel_to_pad > 0 and numel_to_pad < aligned_numel:False , deviceif _is_truly_contiguous(tensor)else _detach_if_needed(tensor).as_strided((tensor.numel(),), (1 ,))if numel_to_pad > 0 and numel_to_pad < self.world_size:False , deviceelse :if _is_truly_contiguous(tensor)else _detach_if_needed(tensor).as_strided((tensor.numel(),), (1 ,))for tensor in tensorsreturn torch.cat(flat_tensors, dim=0 )
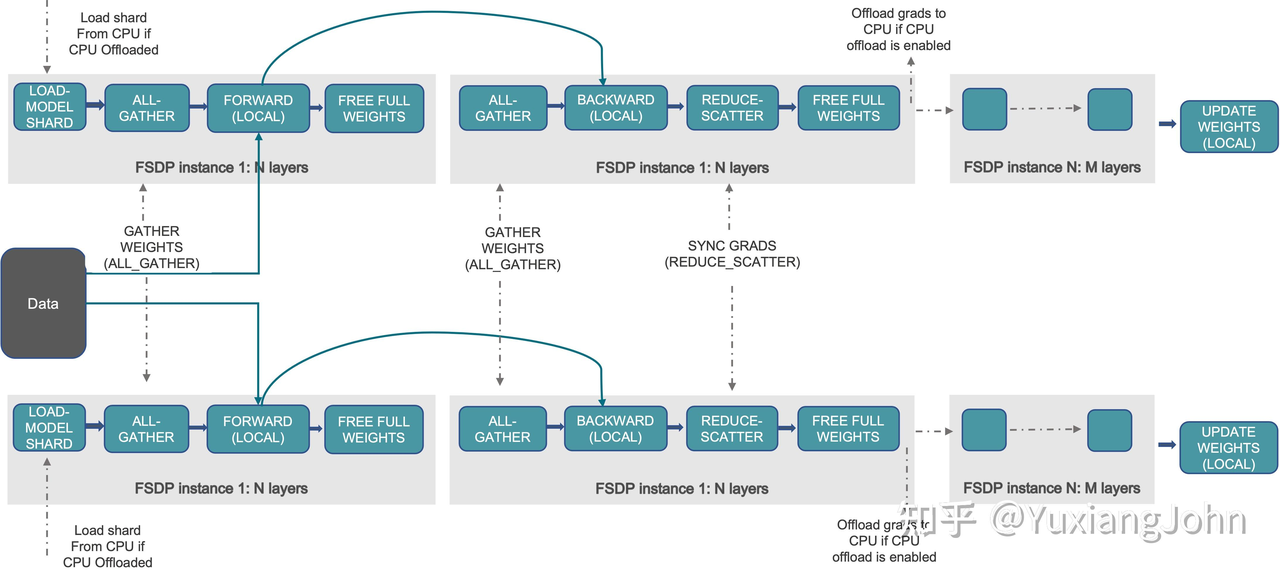
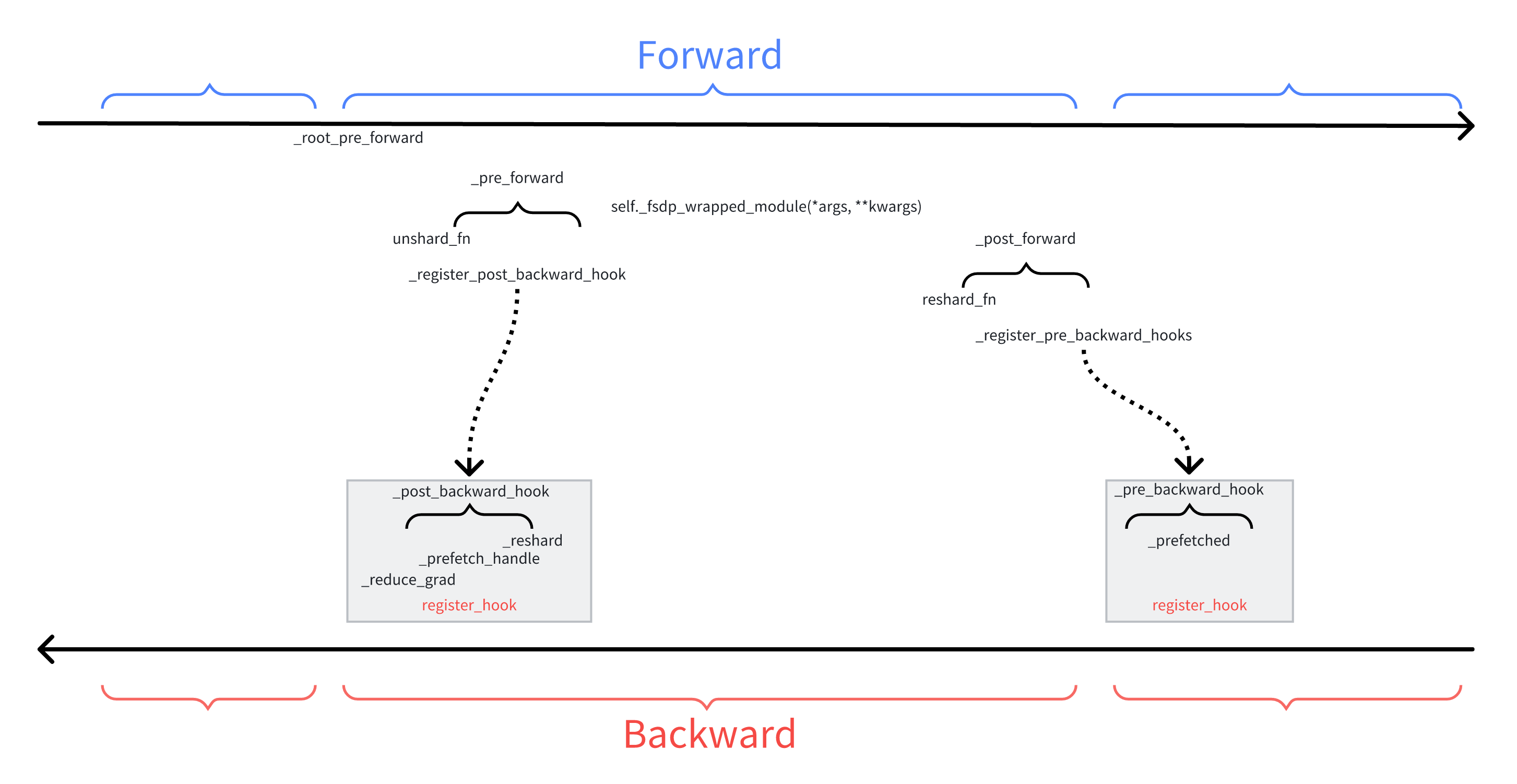
fsdp模型forward 最外部的代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def forward (self, *args: Any , **kwargs: Any ) -> Any :"""Run the forward pass for the wrapped module, inserting FSDP-specific pre- and post-forward sharding logic.""" with torch.autograd.profiler.record_function("FullyShardedDataParallel.forward" None if handle:"Expected `FlatParameter` to be on the compute device " f"{self.compute_device} but got {handle.flat_param.device} " ,return _post_forward(
_pre_forward 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 @no_type_check def _pre_forward ( state: _FSDPState, handle: Optional [FlatParamHandle], unshard_fn: Callable , module: nn.Module, args: tuple [Any , ...], kwargs: dict [str , Any ], tuple [tuple [Any , ...], dict [str , Any ]]:""" 执行前向传播前的逻辑。这包括: 1. 对当前分片的参数进行反分片(unshard),使其恢复为完整参数。 2. 为这些参数注册后向传播钩子(post-backward hooks)。 3. 将前向传播的输入(args, kwargs)转换为指定的计算精度。 """ with torch.profiler.record_function("FullyShardedDataParallel._pre_forward" ):if handle and handle._training_state == HandleTrainingState.BACKWARD_PRE:return args, kwargsif handle:if unshard_fn is not None :if handle and handle._offload_params and handle.flat_param._cpu_grad is None :"cpu" )and not state._handle._force_full_precisionif should_cast_forward_inputs and state.mixed_precision.cast_forward_inputs:Optional [torch.dtype] = state.mixed_precision.param_dtypereturn args, kwargs
_pre_forward_unshard 对于_pre_forward,可以看到其传入的是_pre_forward_unshard函数,该函数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 def _pre_forward_unshard ( state: _FSDPState, handle: Optional [FlatParamHandle], None :"""Unshards parameters in the pre-forward.""" if not handle:return if not handle._prefetched:False if not torch.distributed._functional_collectives.is_torchdynamo_compiling():if state._unshard_event is not None :None else :with torch.profiler.record_function("FullyShardedDataParallel._pre_forward_prefetch" @no_type_check def _unshard ( state: _FSDPState, handle: FlatParamHandle, unshard_stream: torch.Stream, pre_unshard_stream: torch.Stream, None :""" Unshards the handles in ``handles``. If the handles are in :meth:`summon_full_params` and are using mixed precision, then they are forced to full precision. Postcondition: handle's ``FlatParameter`` 's data is the padded unsharded flat parameter on the compute device. """ if not handle:return with state._device_handle.stream(pre_unshard_stream):if ran_pre_unshard:if state.limit_all_gathers:if event:with torch.profiler.record_function("FullyShardedDataParallel.rate_limiter" with state._device_handle.stream(unshard_stream):
其中最关键的是unshard函数,该函数用来将参数重新收集回来:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 // ... existing code ...def unshard (self ):""" Run the unshard logic. This includes all-gathering the flat parameter and switching to using the unsharded flat parameter. If the handle does not need unsharding, then this only switches to using the unsharded flat parameter. For ``NO_SHARD``, this is a no-op. If FSDP is in :meth:`summon_full_params` and the handle uses parameter mixed precision, then the parameter is forced to full precision. """ if not self.needs_unshard():if self.uses_sharded_strategyelse self.flat_paramreturn
_alloc_padded_unsharded_flat_param 该函数负责获取收集全参数的变量,并给他分配足够的内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 // ... existing code ...def _alloc_padded_unsharded_flat_param (self ):""" Allocate the *padded* unsharded flat parameter. The unpadded unsharded flat parameter is always a view into the padded one. This padded parameter is saved to a different attribute on the ``FlatParameter`` depending on if we force full precision. """ return unsharded_flat_param
_get_padded_unsharded_flat_param 注意这里判断了是否是强制使用全精度,如果是,就会返回flat_param._full_prec_full_param_padded,并且释放掉flat_param._full_param_padded,如果不是,就直接返回flat_param._full_param_padded。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 // ... existing code ...def _get_padded_unsharded_flat_param (self ) -> torch.Tensor:""" Return a reference to the padded unsharded flat parameter depending on the calling context. This should only be called if using a sharded strategy. """ if self._force_full_precision and self._uses_param_mixed_precision:if flat_param._full_param_padded.untyped_storage().size() > 0 :else :return unsharded_flat_param
_alloc_storage 该函数调用了底层存储对象的 resize 方法,将其大小调整为所需的元素数量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def _alloc_storage (tensor: torch.Tensor, size: torch.Size ) -> None :""" Allocate storage for ``tensor`` with the given size. Returns: bool: ``True`` if this method allocated storage and ``False`` if the storage was already allocated. """ with torch.no_grad():if not torch.distributed._functional_collectives.is_torchdynamo_compiling():if not already_allocated:0 ,"Tensor storage should have been resized to be 0 but got PLACEHOLDEr" ,
_all_gather_flat_param 这个函数是通过all_gather操作来进行实际的参数收集:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 // ... existing code ...def _all_gather_flat_param ( self, padded_unsharded_flat_param: Tensor, ) -> Tensor:""" All-gather the handle's flat parameter to the destination ``padded_unsharded_flat_param``. Then switch to use the all-gathered tensor. """ if self._use_fake_all_gatherelse self.process_groupif sharded_flat_param.is_cpu: list (else :if self._offload_params:return padded_unsharded_flat_param
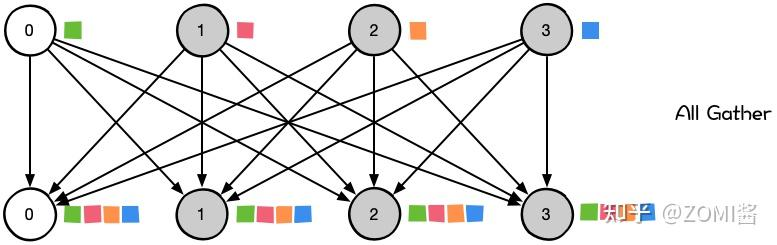
all_gather_into_tensor学习 注意到这里对于GPU使用到了dist.all_gather_into_tensor操作。这个操作的示意图如下,即将各个GPU上的分片按序收集给各个GPU上,使得每个GPU都有一个整体:
这里有一个示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import torchimport torch.distributed as distimport osdef run ():"nccl" ) 2 , device='cuda' ) * (rank + 1 )2 * world_size, device='cuda' )print (f"[rank {rank} ] output_tensor: {output_tensor.cpu().tolist()} " )if __name__ == "__main__" :int (os.environ["LOCAL_RANK" ]))
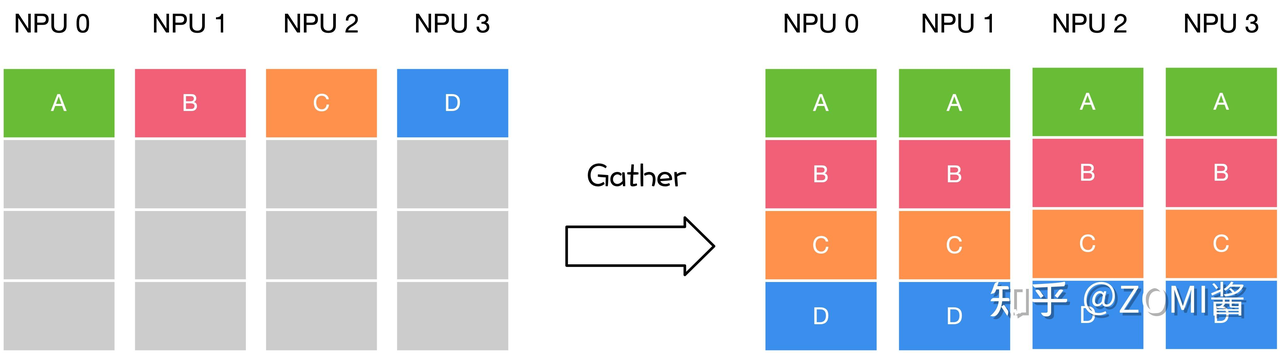
all_gather学习 此外注意到这里这里对CPU使用了all_gather,它是 PyTorch 最经典的分布式通信原语之一。
它负责把每个进程上的 tensor 收集起来,按 rank 顺序填入 tensor_list 中。
tensor_list[i] 就是第 i 个进程的 tensor。
一个简单的示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import torchimport torch.distributed as distimport osdef run ():"gloo" ) 2 ,), rank, dtype=torch.int )for _ in range (world_size)]print (f"[rank {rank} ] tensor_list = {[t.tolist() for t in tensor_list]} " )if __name__ == "__main__" :
record_stream学习 这里对于off_load模型,即将参数卸载到CPU上的操作,会使用 record_stream(stream) 注册 stream 依赖,从而告诉系统这个 tensor 来自 CPU,是通过 stream X 拷贝到 GPU 的,请不要在这个 stream 执行完之前把它删掉。
1 2 3 4 5 6 7 8 if self._offload_params:
_register_post_backward_hook 主要用于在梯度计算完后对参数进行重新分片
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 def _register_post_backward_hook ( state: _FSDPState, handle: Optional [FlatParamHandle], None :""" 在 FlatParameter 的 AccumulateGrad 对象上注册一个后向钩子(post-backward hook), 用于在梯度计算完成后执行梯度的 reduce-scatter 操作以及参数的重新分片(reshard)。 AccumulateGrad 对象是完成 FlatParameter 梯度计算的最后一个函数, 因此钩子能确保在参数的整个梯度计算完成后才运行。 我们只在 FlatParameter 参与的 *第一个* 前向传播中注册一次钩子。 这依赖于 AccumulateGrad 对象在多次前向传播中被保留的特性。 """ if not torch.is_grad_enabled():return if not handle:return if torch.distributed._functional_collectives.is_torchdynamo_compiling():hasattr (flat_param, "_post_backward_hook_handle" )if already_registered or not flat_param.requires_grad:return else : hasattr (flat_param, "_post_backward_hook_state" )if already_registered or not flat_param.requires_grad:return is not None ,"需要 grad_fn 来访问 AccumulateGrad 对象并注册后向钩子" ,0 ][0 ] assert acc_grad is not None
acc_grad.register_hook学习 为了在 反向传播过程中准确地知道哪些参数梯度已经计算完成 ,它会在 每个参数的 AccumulateGrad 节点上注册钩子(hook) 。
首先需要获取 grad_fn,构建 autograd 路径
flat_param 是一个 leaf tensor(即 requires_grad=True 且没有 grad_fn);
使用 expand_as() 创建一个临时 view tensor,**这个 view 有 grad_fn**;
这个 grad_fn 会链接到 AccumulateGrad 节点
需要找到 AccumulateGrad
1 2 3 4 5 grad_fn (ExpandBackward0)0 ][0 ]
然后我们需要注册钩子:
使用 functools.partial() 固定住状态(state, handle);
注册的 _post_backward_hook 会在梯度写入 .grad 前后触发;
这是 FSDP 判断“这个参数的梯度已经完成了,可以 reshard / reduce / offload”的触发点。
然后记录下这个钩子对应的对象和句柄,方便:
判断是否已注册(防止重复);
后续移除 hook;
debug 或控制生命周期。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import torch1.0 , 2.0 , 3.0 ], requires_grad=True )2 ).sum ()print ("y=" ,y)0 ][0 ]def my_hook (grad_input, grad_output ):print (f"HOOK: grad_input={grad_input} , grad_output={grad_output} " )0 ]0.5 print ("Modified grad:" , g)print ("x.grad=" ,x.grad)
_post_backward_hook 这是 FSDP 的核心反向传播钩子,负责在本地梯度计算完成后,进行跨 GPU 的梯度同步(reduce-scatter)和参数重新分片(reshard)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 @no_type_check @torch.no_grad() def _post_backward_hook ( state: _FSDPState, handle: FlatParamHandle, flat_param, *unused: Any , """ 对 `handle` 的 `FlatParameter` 的梯度执行 Reduce-scatter 操作。 这是 FSDP 的核心反向传播钩子,负责在本地梯度计算完成后, 进行跨 GPU 的梯度同步(reduce-scatter)和参数重新分片(reshard)。 前置条件: - `FlatParameter` 的 `.grad` 属性包含了本地批次(local batch)的完整(unsharded)梯度。 后置条件: - 如果使用 `NO_SHARD` 策略,`.grad` 属性将是经过 all-reduce 后的完整梯度。 - 否则,`_saved_grad_shard` 属性将是经过 reduce-scatter 后的分片梯度(会与已有的梯度累加)。 """ True with torch.autograd.profiler.record_function("FullyShardedDataParallel._post_backward_hook" in (HandleTrainingState.BACKWARD_PRE, HandleTrainingState.BACKWARD_POST),f"Expects `BACKWARD_PRE` or `BACKWARD_POST` state but got {handle._training_state} " ,if flat_param.grad is None :return if flat_param.grad.requires_grad:raise RuntimeError("FSDP does not support gradients of gradients" )if not state._sync_gradients:if handle._use_orig_params:return if not torch.distributed._functional_collectives.is_torchdynamo_compiling():with state._device_handle.stream(state._post_backward_stream):if (not _low_precision_hook_enabled(state)and flat_param.grad.dtype != handle._reduce_dtypeand not handle._force_full_precisionif handle.uses_sharded_strategy:else :
_post_backward_reshard 在梯度计算好后我们可以提前将之前unshard的参数进行reshard,从而释放内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def _post_backward_reshard ( state: _FSDPState, handle: FlatParamHandle, *unused: Any , None :""" 在反向传播后执行参数的重新分片(reshard)和预取(prefetch)操作。 这个函数是后向钩子(post-backward hook)的核心逻辑之一,负责在梯度计算和 聚合之后,管理参数的内存状态,并为下一次迭代(的第一个前向传播)做准备。 """ with torch.profiler.record_function("FullyShardedDataParallel._post_backward_prefetch"
此外为了计算和通行的重叠,会为了下一次迭代提前开启unshard。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 @no_type_check def _prefetch_handle ( state: _FSDPState, current_handle: Optional [FlatParamHandle], prefetch_mode: _PrefetchMode, None :""" 根据需要(异步地)预取下一个 handle 的参数。 这个函数是 FSDP 实现计算和通信重叠的关键。它会在当前 handle 计算的同时, 提前将下一个 handle 所需的参数从分片状态(sharded)通过 all-gather 恢复为 完整状态(unsharded)。 """ if not current_handle:return if not handle:return if prefetch_mode == _PrefetchMode.BACKWARD:elif prefetch_mode == _PrefetchMode.FORWARD:else :raise ValueError(f"Invalid prefetch mode on rank {state.rank} : {prefetch_mode} " )True
_register_post_backward_reshard_only_hook 对于那些不需要梯度计算的参数,注册一个梯度计算结束后进行重分片的勾子函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 def _register_post_backward_reshard_only_hook ( state: _FSDPState, handle: Optional [FlatParamHandle], args: tuple [Any , ...], kwargs: dict [str , Any ], None :""" 为那些不需要计算梯度(requires_grad=False)的扁平化参数(FlatParameter)注册一个 仅用于重新分片(reshard)的后向钩子。 我们通过在模块的输入激活(input activations)上注册一个多重梯度钩子(multi-post-grad hook) 来做到这一点。这么做的原因是,对于 requires_grad=False 的参数,我们无法像之前一样 在其自身的 AccumulateGrad 对象上注册钩子(因为它不存在)。 通过在输入张量上挂钩,我们可以确保在所有可能依赖于该参数的梯度都计算完毕后, 才执行重新分片操作,从而安全地释放内存。 """ if not torch.is_grad_enabled():return Optional [list [torch.Tensor]] = None if not handle:return if torch.distributed._functional_collectives.is_torchdynamo_compiling():hasattr (flat_param, "_post_backward_hook_handle" )else :hasattr (flat_param, "_post_backward_hook_state" )if already_registered or flat_param.requires_grad:return if inp_tensors is None :for obj in args_flat if torch.is_tensor(obj) and obj.requires_gradassert inp_tensors is not None if torch.distributed._functional_collectives.is_torchdynamo_compiling():else :
_post_backward_reshard_only_hook 这里是注册的勾子函数,该函数会在梯度计算完成后计算,其作用是对于不需要梯度计算的参数,也在反向传播完成后将参数进行分片。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 def _post_backward_reshard_only_hook ( state: _FSDPState, handle: FlatParamHandle, *unused: Any , None :""" 仅用于重新分片的后向钩子(post-backward hook)。 这个钩子专门为那些不需要梯度(`requires_grad=False`)的参数服务。 它的主要作用是在反向传播完成后,安全地将完整的(unsharded)参数重新分片(reshard), 从而释放内存。 """ with torch.profiler.record_function("FullyShardedDataParallel._post_backward_hook_reshard_only" def _post_backward_reshard ( state: _FSDPState, handle: FlatParamHandle, *unused: Any , None :""" 执行后向传播后的重新分片和预取操作。 这个函数是后向钩子的核心部分,负责在梯度计算和聚合之后管理参数内存和为下一次迭代做准备。 """ with torch.profiler.record_function("FullyShardedDataParallel._post_backward_prefetch" @no_type_check def _should_free_in_backward ( state: _FSDPState, handle: FlatParamHandle, bool :""" 决定 FSDP 是否应该在后向钩子中释放未分片的扁平参数。 返回: bool: 如果应该释放则返回 True,否则返回 False。 """ if not handle.uses_sharded_strategy:return False return (or handle._sharding_strategy in RESHARD_AFTER_FORWARD_HANDLE_STRATEGIES
_post_forward 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 @no_type_check def _post_forward ( state: _FSDPState, handle: Optional [FlatParamHandle], reshard_fn: Callable , module: nn.Module, input : Any , output: Any , Any :""" 运行前向传播后的逻辑。这包括一个机会来重新分片(reshard)当前未分片的参数 (例如在当前前向传播中使用的参数),并在前向传播的输出上注册 pre-backward 钩子。 功能: - 这是 FSDP 前向传播钩子的核心实现,在每个 FSDP 包装的模块的 `forward` 方法之后执行。 - 主要负责在前向计算完成后,将不再需要的完整参数重新分片,以释放 GPU 内存。 - 同时,在输出张量上注册 pre-backward 钩子,以便在反向传播开始时,能够及时地将分片参数恢复为完整参数,用于梯度计算。 Args: state (_FSDPState): FSDP 的全局状态。 handle (Optional[FlatParamHandle]): 当前前向传播中使用的参数句柄。 reshard_fn (Callable): 一个可调用对象,用于重新分片当前未分片的参数。如果为 `None`,则不执行任何重新分片操作。 module (nn.Module): 刚刚执行完 `forward` 的模块。 input (Any): 模块的输入(未使用,仅为满足钩子签名要求)。 output (Any): 前向传播的输出。Pre-backward 钩子会注册在该输出中需要梯度的张量上。 后置条件: - 每个 `FlatParameter` 的 `data` 属性将指向分片后的扁平化参数,从而释放内存。 - 输出张量上已注册 pre-backward 钩子。 主要逻辑: 1. **处理激活检查点(Activation Checkpointing)**:如果与 `fully_shard` 和 `checkpoint` 一起使用,在重新计算的前向传播中会跳过此后向钩子逻辑,因为参数状态由激活检查点管理。 2. **记录执行顺序**:记录当前 handle 的前向传播完成事件,用于后续的乱序执行优化。 3. **重新分片 (Resharding)**:如果提供了 `reshard_fn`,则调用它来执行参数的重新分片,将完整的参数转换回分片状态,释放内存。 4. **注册 Pre-Backward 钩子**:调用 `_register_pre_backward_hooks`,遍历 `output` 中的张量,为那些需要梯度的张量注册一个钩子。这个钩子将在反向传播到达该张量时触发,执行参数的 unshard 操作(all-gather)。 5. **更新状态**:将 FSDP 实例和 handle 的训练状态更新为 `IDLE`,表示前向传播阶段已完成。 """ with torch.profiler.record_function("FullyShardedDataParallel._post_forward" ):if handle and handle._training_state == HandleTrainingState.BACKWARD_PRE:return outputif reshard_fn is not None :if handle:return output
_post_forward_reshard _post_forward中使用的reshard_fn就是_post_forward_reshard。
这是在前向传播后触发重新分片的入口函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @no_type_check def _post_forward_reshard ( state: _FSDPState, handle: FlatParamHandle, None :"""在前向传播后重新分片参数。""" if not handle:return not state._is_rootand handle._sharding_strategy in RESHARD_AFTER_FORWARD_HANDLE_STRATEGIES
这个函数调用参数句柄(handle)来执行实际的重新分片逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 @no_type_check def _reshard ( state: _FSDPState, handle: FlatParamHandle, free_unsharded_flat_param: bool , """ 重新分片句柄。`free_unsharded_flat_param` 指示是否释放 句柄的带填充的未分片扁平参数。 """ if state.limit_all_gathers and free_unsharded_flat_param:if not torch.distributed._functional_collectives.is_torchdynamo_compiling():False
执行重分片逻辑,需要先转为使用本地参数,再安全释放收集的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def reshard (self, free_unsharded_flat_param: bool ):""" 运行重新分片逻辑。 这包括如果 `free_unsharded_flat_param` 为真,则释放未分片的扁平参数, 并切换到使用分片的扁平参数。注意,这也隐式地将分片的扁平参数 卸载到 CPU(如果启用了 CPU offload),通过将其指向位于 CPU 上的 `_local_shard` 属性。 """ if free_unsharded_flat_param:
主要作用是将 self.flat_param (一个 nn.Parameter) 的 .data 属性从指向完整的、未分片的张量,切换为指向本地的分片张量 (self.flat_param._local_shard)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 def _use_sharded_flat_param (self ) -> None :"""切换到使用分片的扁平参数。""" if self._use_orig_params:and in_forwardand self._sharding_strategyin NO_RESHARD_AFTER_FORWARD_HANDLE_STRATEGIESif skip_use_sharded_views:if self._offload_params:"cpu" ),f"期望本地分片在 CPU 上,但实际在 {device} " ,if self._use_orig_params:if skip_use_sharded_views: else :if (and not self._skipped_use_sharded_viewsis not None and self.uses_sharded_strategyand flat_param.grad.shape == flat_param._unpadded_unsharded_sizeif accumulated_grad_in_no_sync:else :
释放放带填充的未分片扁平参数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def _free_unsharded_flat_param (self ):""" 释放带填充的未分片扁平参数。我们允许在存储未分配时也调用此函数。 要释放的张量取决于调用上下文,因为 unshard 可能强制使用了全精度, 在这种情况下,会使用一个不同的张量。 """
首先获取到之前带填充的、未分片的扁平参数的引用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 def _get_padded_unsharded_flat_param (self ) -> torch.Tensor:""" 根据调用上下文,返回对带填充的、未分片的扁平参数的引用。 功能: - 此方法是获取用于 all-gather 操作的目标张量的核心逻辑。 - 它处理了混合精度训练中的一个重要情况:当需要强制使用全精度参数时,它会返回一个不同的、高精度的张量,并释放可能存在的旧的、低精度的张量,以确保数据一致性。 主要逻辑: 1. **检查分片策略**:确保此方法仅在使用了分片策略(如 `FULL_SHARD` 或 `SHARD_GRAD_OP`)时被调用。 2. **处理强制全精度和混合精度**: - 如果 `_force_full_precision`(例如,在 `summon_full_params` 中)和 `_uses_param_mixed_precision` 都为 `True`,则意味着我们需要一个全精度的参数副本进行操作。 - 在这种情况下,返回 `_full_prec_full_param_padded`,这是一个专门用于存储全精度参数的张量。 - **关键操作**:如果低精度的 `_full_param_padded` 张量仍然占用内存(意味着它可能来自上一次前向传播且未被释放),则必须将其释放。这是因为对全精度参数的修改会使这个低精度副本失效。释放后,下一次计算将强制执行新的 all-gather 来获取最新的数据,而不是使用过时的低精度缓存。 3. **标准情况**: - 在其他所有情况下(例如,不强制全精度或不使用混合精度),直接返回标准的 `_full_param_padded` 张量,该张量将作为 all-gather 的目标。 """ if self._force_full_precision and self._uses_param_mixed_precision:f"期望全精度但得到了 {self._fwd_bwd_param_dtype} " ,if flat_param._full_param_padded.untyped_storage().size() > 0 :else :return unsharded_flat_param
这是一个通用的底层工具函数,通过将张量的存储大小调整为 0 来释放其内存。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def _free_storage (tensor: torch.Tensor ):""" 释放 `tensor` 的底层存储。 返回: bool: 如果方法释放了存储,则返回 `True`;如果存储已被释放,则返回 `False`。 """ with torch.no_grad():if not torch.distributed._functional_collectives.is_torchdynamo_compiling():0 if not already_freed:0 ,"当张量不是其存储的唯一占用者时,释放它的存储是不安全的\n" f"storage offset: {tensor.storage_offset()} \n" f"storage size: {tensor._typed_storage()._size()} \n" f"tensor shape: {tensor.shape} " ,0 )
_register_pre_backward_hooks 主要是注册反向传播前置钩子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 @no_type_check def _register_pre_backward_hooks ( state: _FSDPState, module: nn.Module, outputs: Any , handle: FlatParamHandle, None :""" 在 `outputs`(前向传播的输出)中需要梯度的张量上注册反向传播前置钩子(pre-backward hooks)。 这些输出是使用 `handle` 的 `FlatParameter` 计算得出的。 功能: - 这是 FSDP 实现自动、即时(just-in-time)参数 un-sharding 的核心机制。 - 通过在模块的输出张量上注册钩子,FSDP 可以在反向传播到达该模块之前,精确地触发相应参数的 all-gather 操作。 - 这样可以确保在计算梯度时,完整的、未分片的参数是可用的,同时在其他时间保持分片状态以节省内存。 主要逻辑: 1. **检查梯度计算**:如果当前没有启用梯度计算(例如,在 `torch.no_grad()` 上下文中),则无需注册任何钩子,直接返回。 2. **重置状态**: - 对于根模块,重置 `_post_backward_callback_queued` 标志,为新的反向传播做准备。 - 对于当前 `handle`,重置 `_needs_pre_backward_unshard` 和 `_ran_pre_backward_hook` 标志,以确保钩子逻辑的正确执行。 3. **定义钩子注册函数 `_register_hook`**: - 此内部函数负责在单个张量上注册钩子。 - **条件**:仅当张量 `requires_grad` 时才注册,因为只有这些张量会参与反向传播。 - **注册**:使用 `t.register_hook()` 将 `_pre_backward_hook`(通过 `functools.partial` 包装)附加到张量上。 - **标记需求**:注册钩子后,将 `handle._needs_pre_backward_unshard` 设为 `True`,表明该 `handle` 对应的参数在反向传播中需要被 un-shard。 4. **递归应用钩子**: - 使用 `_apply_to_tensors` 工具函数,将 `_register_hook` 应用于 `outputs` 中的所有张量。这可以处理复杂的输出结构(如元组、列表、字典等)。 """ if not torch.is_grad_enabled():return outputsif state._is_root:False if handle:False False def _register_hook (t: torch.Tensor ) -> torch.Tensor:if t.requires_grad:if handle:True return treturn _apply_to_tensors(_register_hook, outputs)
具体注册的勾子函数为_pre_backward_hook,该函数主要是执行_unshard来通过 all-gather 操作获取完整的参数,并且为了重叠计算和通信,它会立即触发下一个(在反向传播顺序中)模块参数的 prefetching(预取)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 @no_type_check def _pre_backward_hook ( state: _FSDPState, module: nn.Module, handle: FlatParamHandle, grad, *unused: Any , Any :""" 为梯度计算准备 `handle` 的 `FlatParameter`。 功能: - 这是 FSDP 的核心反向传播钩子,由 `_register_pre_backward_hooks` 注册。 - 当反向传播的梯度流到达一个模块的输出张量时,这个钩子被触发。 - 它的主要职责是: 1. **Un-shard 参数**:执行 all-gather 操作,将当前模块所需的 `FlatParameter` 从分片状态恢复为完整的、未分片的张量,以便进行梯度计算。 2. **预取下一个参数**:为了重叠计算和通信,它会立即触发下一个(在反向传播顺序中)模块参数的 prefetching(预取)。 3. **状态管理**:管理 FSDP 的内部状态,例如标记钩子已运行,以及为根模块注册最终的 post-backward 回调。 主要逻辑: 1. **钩子执行保护**:检查 `_ran_pre_backward_hook` 标志,确保对于同一次前向计算涉及的同一组参数,此钩子只执行一次。 2. **根模块初始化**:如果是根 FSDP 模块,并且是反向传播的第一次调用,它会注册一个 `_post_backward_final_callback`。这个回调将在整个反向传播结束后执行,用于最终的清理工作(如梯度 reshard)。 3. **状态转换**:将 FSDP 状态机切换到 `FORWARD_BACKWARD` 和 `BACKWARD_PRE`,用于调试和断言。 4. **参数 Un-shard**: - 检查 `_needs_pre_backward_unshard` 标志。 - 如果需要 un-shard 且参数尚未被预取(`_prefetched` 为 False),则调用 `_unshard` 执行 all-gather。 - 使用 `wait_stream` 确保计算流等待 un-shard 操作完成。 5. **反向预取(Backward Prefetch)**: - 调用 `_prefetch_handle` 并传入 `_PrefetchMode.BACKWARD`,以启动下一个句柄的参数 un-sharding。这是 FSDP 的关键性能优化。 6. **梯度准备**:调用 `handle.prepare_gradient_for_backward()`,为即将到来的梯度计算做准备。 7. **标记完成**:设置 `_ran_pre_backward_hook = True`。 """ if (and hasattr (handle, "_ran_pre_backward_hook" )and handle._ran_pre_backward_hookreturn gradwith torch.profiler.record_function("FullyShardedDataParallel._pre_backward_hook" ):if state._is_root and not state._post_backward_callback_queued:elif handle:if _is_composable(state):if not handle:return gradif handle._needs_pre_backward_unshard:if not handle._prefetched:if not torch.distributed._functional_collectives.is_torchdynamo_compiling():False with torch.profiler.record_function("FullyShardedDataParallel._pre_backward_prefetch" True return grad
总结 勾子函数及运行流程
参考资料