【论文阅读】Megatron-LM论文阅读
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
https://arxiv.org/abs/1909.08053
背景
在2019年就出现了大语言模型规模越来越大,单个GPU的显存难以放下的情况,过去已有方法提出了一些关于模型并行的方法,但是其往往需要重写模型,依赖于自定义编译器和框架。
方法思路
本文提出了一种针对transfer模型的层内模型并行的方法,完全依靠原生pytorch即可实现。具体而言针对以下3个位置进行了优化。
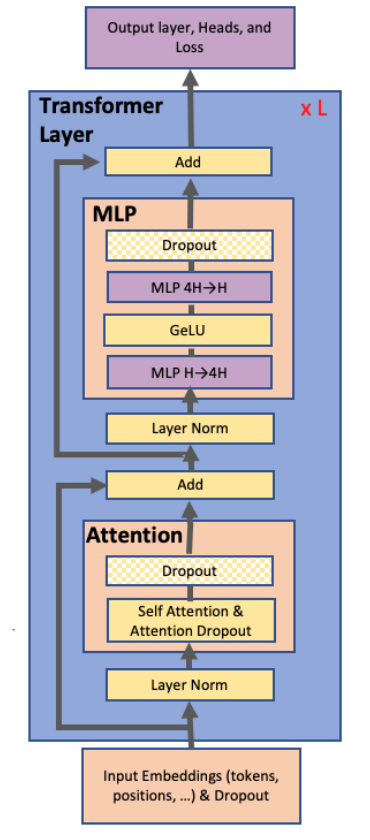
MLP层模型并行优化
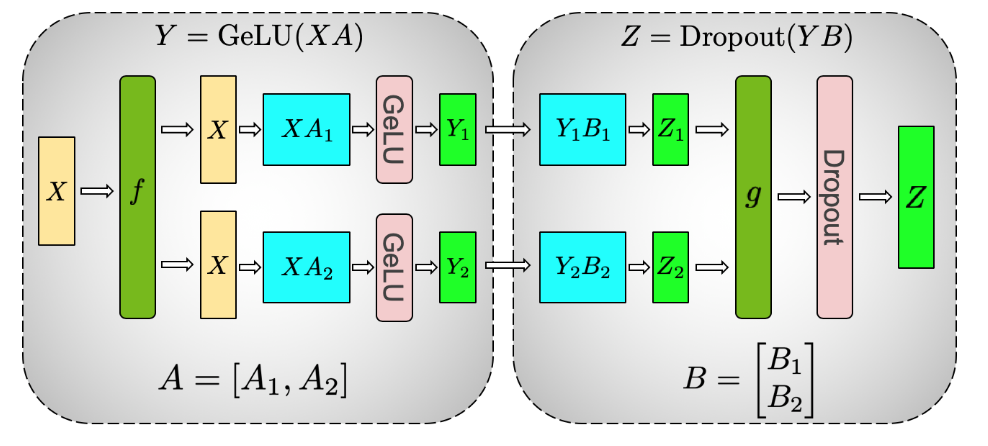
如上图所示,MLP层往往是由Gemm+Gelu+Gemm组成,为了不在Gelu前多一次聚集操作,所以采用先进行列并行再进行行并行的方式切分,只需要最后Dropout前再All reduce一次即可。
注意反向传播会在图中f的位置进行一次All Reduce
Attention层模型优化
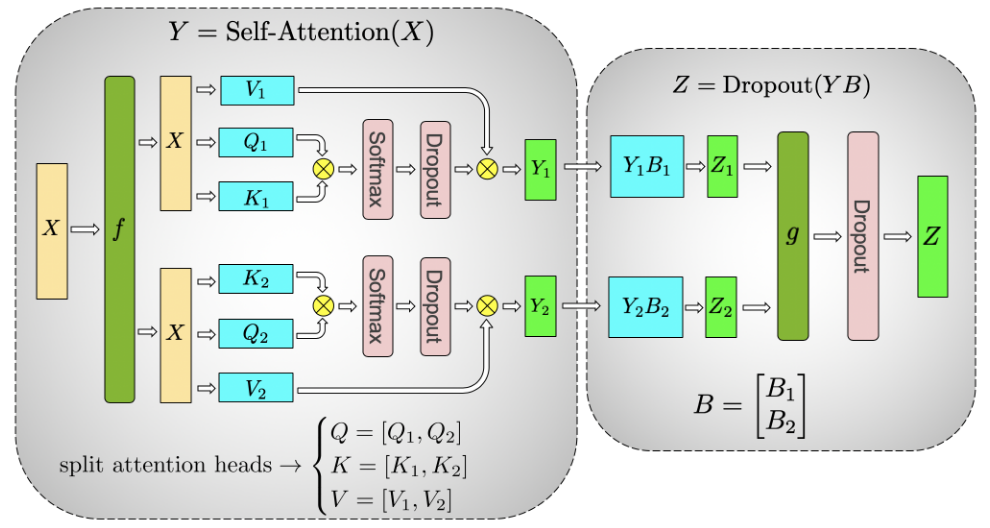
多头注意力机制天然形成了列并行,一个注意力头为划分单位。
一般的多头注意力在各个头计算完后要拼接,然后再进行一次Gemm的操作,而借助原本就是列并行,所以多头注意力可以不需要拼接,直接与行并行切分的权重进行计算,然后在Gropout前再All reduce一次即可。
注意反向传播会在图中f的位置进行一次All Reduce。
Embedding层模型并行优化
往往输入和输出会共用参数,而vocab size一般很大,所以有切分的必要。
对该参数采用列并行的方式,每个GPU拥有一定范围内的vocab内容:
对于输入:
- 如果这个token的id在GPU的范围内就给它对应列的值,否则就设0,然后对各个GPU进行All Reduce得到正确结果
对于输出:
- 正常列并行是与列并行的参数计算后再All Gather得到完整的logits,再计算交叉熵损失,如下:
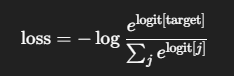
- 但是由于这里All Gather的数据量达到了Batch Size * Vocab Size * Mode Size,所以就改成每个GPU计算自己对应列的各个logits后再计算交叉熵所需要的各个logit的指数和,以及如果target在自己的范围内,就返回对应的logits,如此就把交换的信息量降低为了Batch Size * Vocab Size 级别。
实验效果
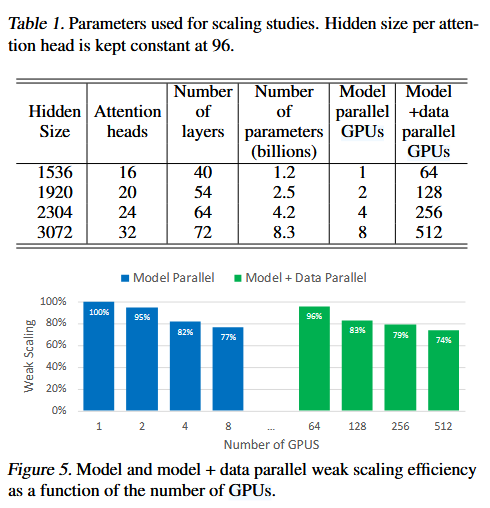
对于8.3B的模型在512卡上进行数据并行+模型并行,最终实现了77%的线性缩放,并且通过训练更大的模型也证明了模型规模的增大带来的模型能力的提升。
总结
主要是围绕了Tensor并行来展开,针对Transformer模型做了针对性的优化,形成了后面的共识,也做了一系列在当时来看的大型实验。此外开源工具Megatron-LM做的很好,现在也依然是主流的预训练框架。
Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
https://arxiv.org/abs/2104.04473
背景
21年时,大语言模型的发展已经使得多GPU服务器都难以适应训练大模型
由于训练数据的增多,需要更多GPU并行训练来降低训练时间,而单纯的依靠数据并行会导致:
Batch size太小导致GPU利用率下降,需要增加通信成本
Batch size大小受到设备数量限制
现有的一些其他方法提出了模型并行的相关技术:
张量并行的问题:
All Reduce若通过服务器间链路会导致通信耗时大
高度的张量并行会导致多个小矩阵相乘,降低利用率
流水线并行的问题:
- 为了严格保持优化器语义,每个batch结束时,需要跨服务器进行梯度同步,导致长时间的等待,即气泡,而气泡含量往往与Micro batch size/pipeline size负相关,所以往往会设置很大的batch size以提高效率
用户可以单独使用或者组合各个并行技术进行训练,但是组合是有难度的,所以就带来了一个经典问题:
How should parallelism techniques be combined to maximize the training throughput of large models given a batch size while retaining strict optimizer semantics?
应该如何结合并行技术来最大化给定批量大小的大型模型的训练吞吐量,同时保留严格的优化器语义?
故本文展示了如何高效组合数据并行、张量并行与流水线并行以拓展训练大模型。
方法思路
张量并行与流水线并行结合
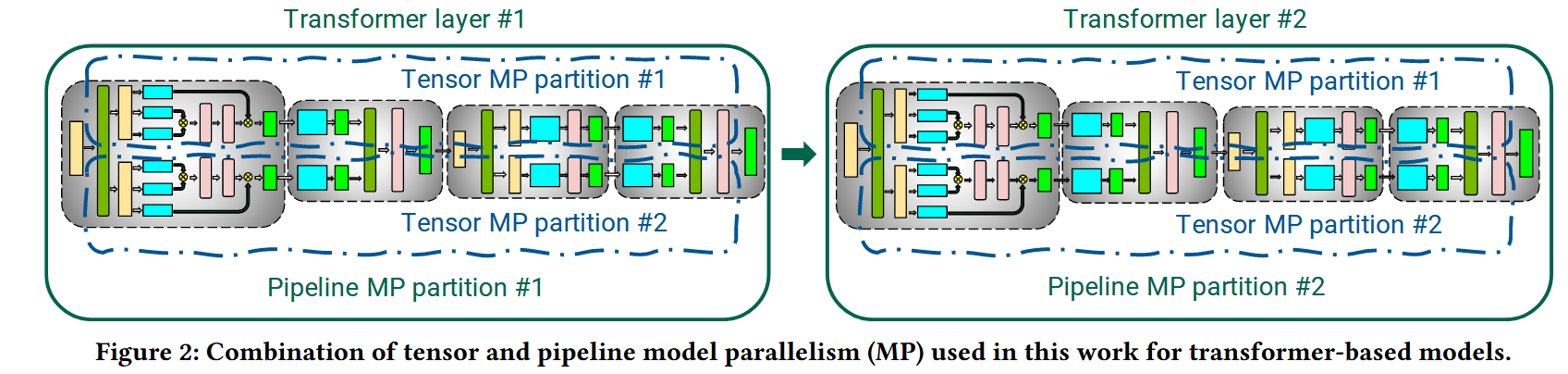
张量并行如上一篇论文所述,在MHA与MLP中进行切分,注意张量并行必须在服务器内才高效
流水线并行在多个Transformer层中进行切分
流水线并行调度优化
最简单的AFAB调度如下,其气泡含量为:(p-1)/m,其中p是流水线条数,m是micro batch size。要想减少气泡最简单的就是增加m,但是由于需要保持m个micro batch激活,会导致显存占用过大
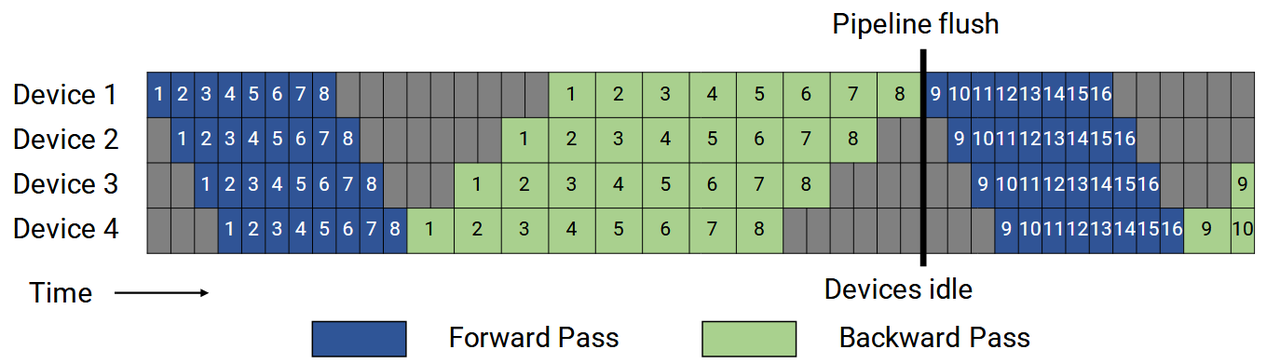
更进一步的优化是使用1F1B,如下所示,虽然气泡含量依旧是(p-1)/m,但是只需要保留p个micro batch的激活,可以更好地增加m

再进一步其提出了交错的方式,上面都是一个device保留连续的一段流水线阶段,例如,假设总共有16层,上述方法就是Device 1保留1~4层,Device 2保留5~8层,以此类推。但是实际上可以交错一下,Device 1保留1~2层和9~10层,Device 2保留3~4层和11~12层,以此类推。这使得气泡含量降为(p-1)/(m*v),其中v是交错的数量,如下图所示。而注意随之而来的代价就是有v倍的通信量。

实现过程中的通信优化
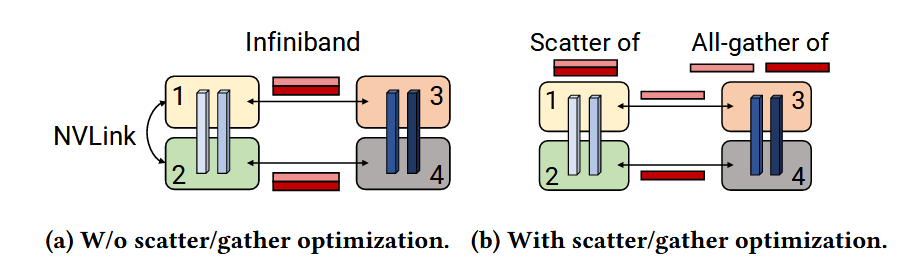
- 流水线并行需要点对点之间交换信息量,对于Tensor并行叠加流水线并行的情况,各个pipeline之间传递的信息是有冗余的,所以可以改为先pipeline两两之间传递各自的部分,然后再在一个Tensor并行组内通过All Gather进行聚合。
实现过程中的计算优化
将数据布局从[B,s,a,h]更改为[s,B,a,h],其中B,s,a和h分别为batch,sequence,attention-head, hidden-size
为element-wise算子如bias + GeLU和bias + dropout + add创建了融合算子
创建了两个自定义内核,以实现scale,mask和softmax的融合
实验效果
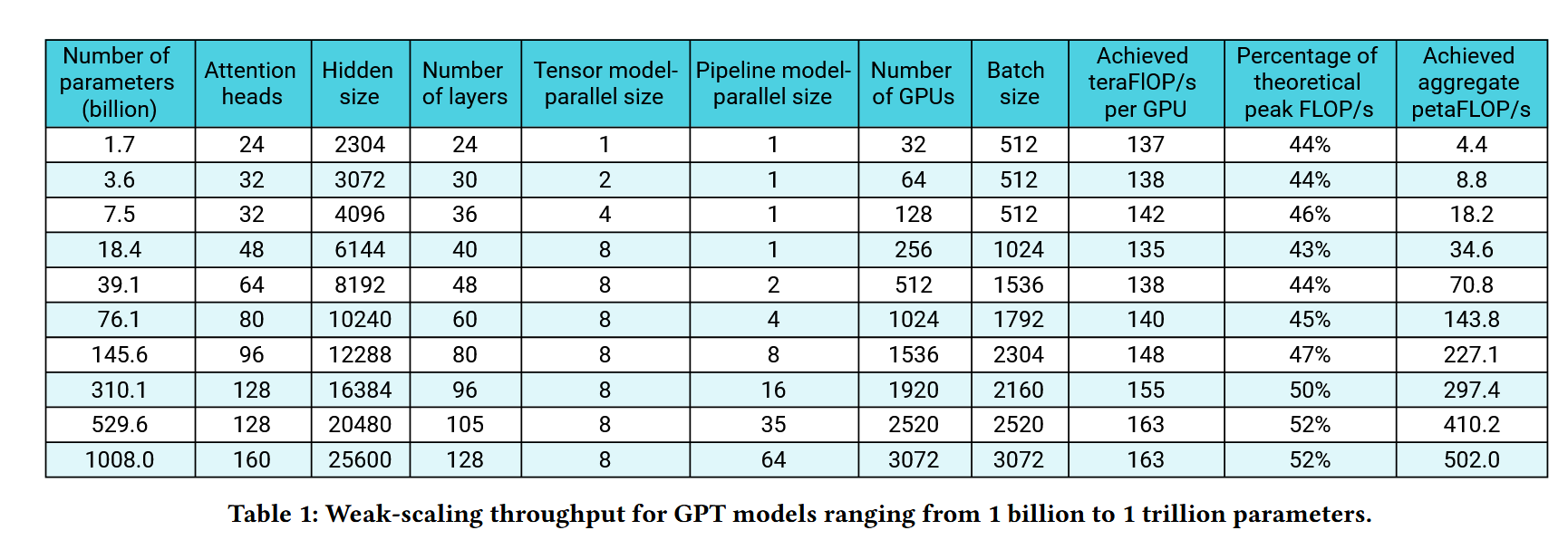
- 利用3D并行实验最大在3072个GPU上训练了1000B的模型实现了最高52%的理论计算峰值
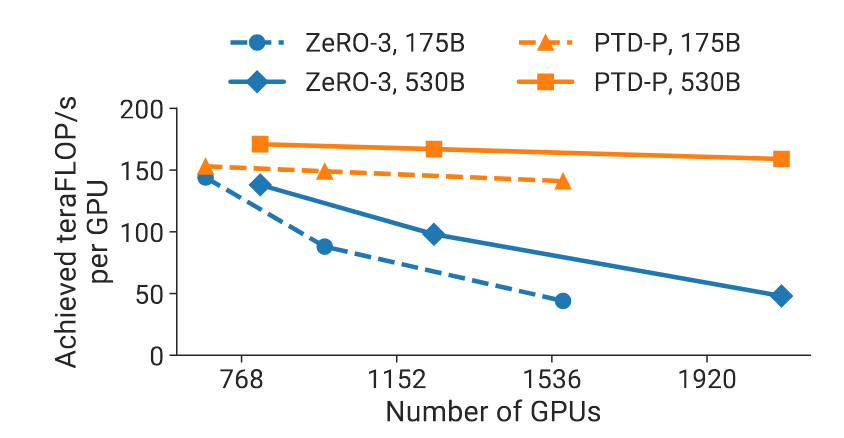
- 还将3D并行与ZERO技术进行了比较,验证了其在更大规模的GPU场景上的良好的拓展性
总结
- 很全面的探究了3D并行的相关事宜,不仅有理论分析也有详尽的实验,相关的许多见解现在依然是标准。