【论文阅读】Reducing Activation Recomputation in Large Transformer Models
发表会议:MLSYS’22(CCF-B)
团队:NVIDIA
背景
在论文发表的2022年看来,一些研究在Transformer大模型训练中会采用激活重计算而不是存储的方式来减少激活值所占存储,但是其问题在于会引入很多冗余计算的开销,导致训练效率降低。故本文提出了序列并行和选择性激活重计算方法,并结合Tensor并行的方式大幅削减了激活重计算带来的开销。
方法思路
理论分析激活值
其理论计算了主要的激活量(注意下述默认各个元素采用16位也就是2字节存储,公式表示的也都是占用的元素字节数),变量名如下:

Transformer大模型结构如下:

Attention模块占用了:11sbh + 5as^2b
MLP模块占用了:19sbh
Layer norm模块:4sbh
上述3者组合得到一层Transformer占用的激活大小:sbh(34+5*as/h)
Tensor并行

- 如果采用了t路Tensor并行,那么会对如上图所示的Attention+MLP模块进行并行化,将每层激活值减少为sbh(10+24/t+5*as/ht)
序列并行
- Tensor并行并不能对LayerNorm和Dropout进行并行化,所以本文还引入了序列并行,以序列维度进行切分,在t维序列并行下,每层激活值减少为:sbh(10/t+24/t+5*as/ht)=sbh/t(34+5*as/h)
流水线并行
在流水线切分下,Transformer的L层被划分为L/p组,p是流水线并行的大小。
对于1F1B的流水线调度策略,每级流水线在第一阶段需要保留L/p*p=L层激活,故激活值大小为:sbhL/t(34+5*as/h)
注意不同调度策略下激活值大小会有所不同
总激活值
- 上述在考虑时没有考虑输入嵌入、最后一层层归一化和输出层所需的激活,其占用的额外激活为:

- 由于其相比原其他相加的值sbhL/t(34+5*as/h)往往比较小,所以可忽略不计
选择性激活
在上述并行优化下得到的激活值大小以及很大,故还需要进一步优化
完全激活重计算(即只保留输入激活)可以将总内存需求减少到2sbhL,如果进一步在张量并行等级优化,可以将其优化到2sbhL/t。但是这会导致过度的冗余计算,并且张量并行下会增加通信开销。
为了平衡计算与内存的开销,其核心思想是仅对占用了大量内存但是重计算方便的Transformer层进行检查点设置。
对于公式中的34其与大型矩阵计算更相关,对于5*as/h主要指的是QK^T矩阵乘法、softmax、softmax dropout和V上的注意力,这些操作有较大的输入和激活,但是其运算量低。带入GPT 3大模型的参数,计算得到5*as/h=80,大于34,占更大的部分。所以其倾向于将5*as/h相关部分的激活去掉以快速重计算,而将34相关计算的激活保留,避免缓慢的重计算。
实验效果
- 如下图所示,其验证了Sequence 并行与选择性激活区激活值的优化效果,以及两者叠加的优化效果。

- 如下图所示,也实际验证了其对模型训练过程中显存占用的优化情况

- 相比与不重计算的耗时只增加了约4%。
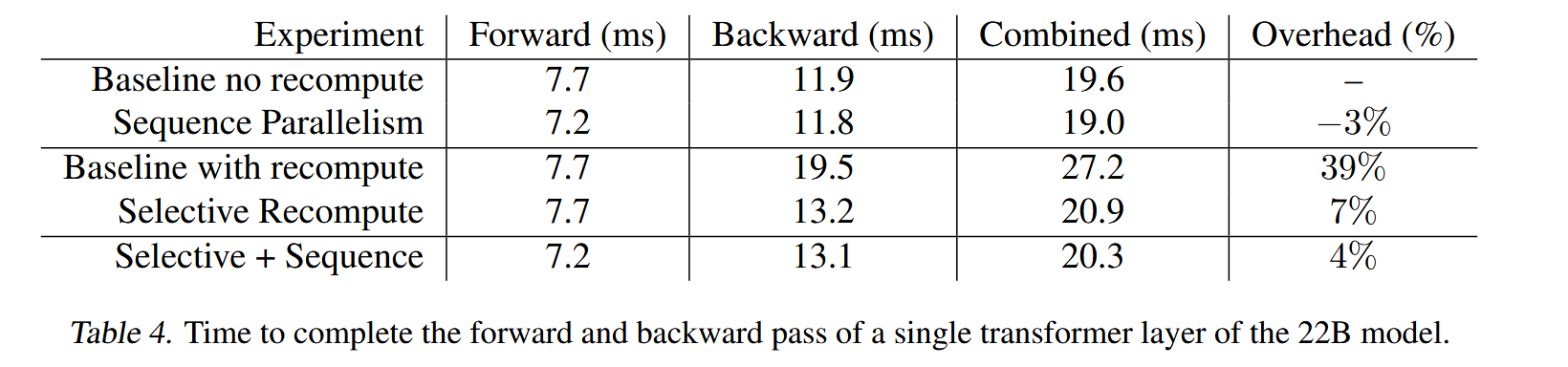
- 相比于完全重计算,吞吐也增加了30%左右。
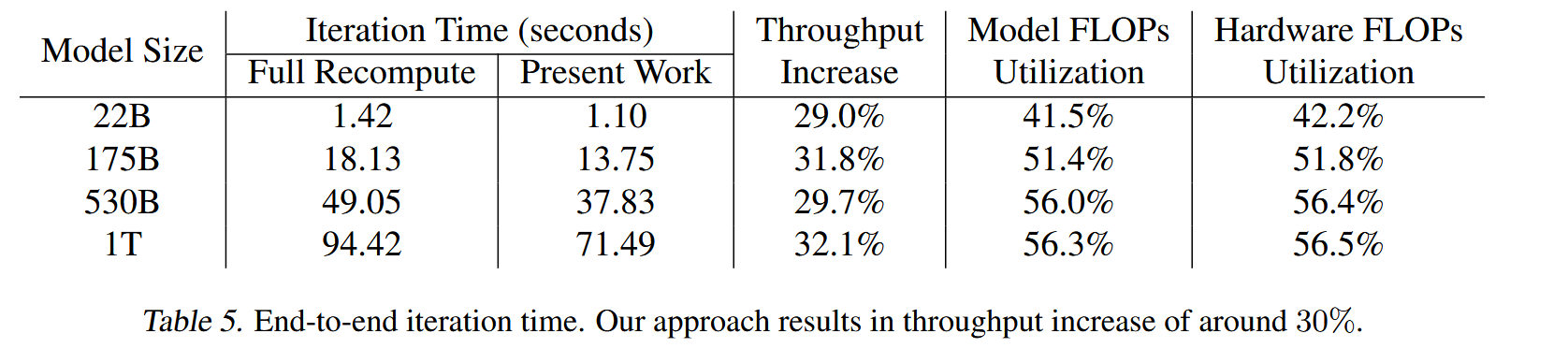
总结
对激活值理论计算的部分很精彩。
引入了Sequence并行,这在后续也成为了一大标准。
选择性激活重计算很朴素但确实很好用。