【论文阅读】The Llama 3 Herd of Models(Section 3 Pre-Training)
团队: META
背景
Llama 3发表于2024年7月,其是一个包含8B、70B和405B参数的多语言语言模型群,实验结果显示,Llama 3的旗舰模型在各种任务上的表现与当时领先的语言模型如GPT-4相当,接近最先进水平。并且其还开发了多模态扩展模型,支持图像识别、视频识别和语音理解功能。
Llama 3语言模型的开发主要分为语言模型预训练和语言模型后训练两个阶段,文中也对其进行了详细介绍,本博客此次主要介绍预训练方面的内容
方法思路
大规模训练语料库的整理和筛选
训练数据涵盖了截至2023年底的知识。
网页数据清理
内容获取:
内容过滤:对包含有害内容(包括成人内容)的域名进行筛选过滤
文本提取:移除html中的特殊标记提取纯文本内容,并且发现md格式的标记也对模型性能有害,所以也md标记进行移除
内容过滤:
数据去重:
url级:依据url去重,只保留最新的;
文档级:依据文档的MinHash移除近似内容;
行级:执行类似ccNet的高强度逐行去重。在每3000万文档的桶中,移除出现次数超过6次的行。
启发式过滤:使用启发式方法,以移除额外的低质量文档、离群值和过多重复的文档。
内容优选与特殊内容提取:
基于模型的质量过滤:应用了各种基于模型的质量分类器来筛选高质量token。
代码和推理数据:由于代码和数学的token分布与自然语言有很大不同,其构建了提取代码和数学相关网页的领域特定工具。
多语言数据:将文档分类为176种语言,并执行去重和低质量文档筛选
数据比例设计
知识分类:
- 开发了一种分类器进行分类,并使用这个分类器对过多的艺术类与娱乐类内容来减少采样
数据比例的扩展法则:
- 其在一个数据比例上训练了几个小模型,并使用这些数据比例来预测大模型的性能,然后测试不同比例下表现。
最终的数据比例包含大约50%的常识token,25%的数学和推理token,17%的代码token,以及8%的多语言token。
退火训练数据
其在经验上发现,对少量高质量的代码和数学数据进行退火训练,可以提升预训练模型在关键基准上的表现。
例如在GSM8k和MATH数据集上评估退火的效果。他们发现退火使得一个预训练的Llama 3 8B模型在GSM8k和MATH验证集上的性能分别提高了24.0%和6.4%。
然而在405B模型上的改进微乎其微,这表明Llama 3旗舰模型具有强大的上下文学习和推理能力,不需要特定领域的训练样本来获得强大的表现。
此外他们也发现退火训练使模型能够判断领域特定小数据集的价值。
- 其通过在40B token上线性退火训练一个训练到50%的Llama 3 8B模型的学习率到0来衡量这些数据集的价值。
模型架构
模型架构上还是标准的稠密Transformer架构,只有一些小改进:
分组查询注意力:使用分组查询注意力,包含8个键值头,以提高推理速度并在解码过程中减少键值缓存的大小。
注意力掩码:使用了一种注意力掩码,防止同一序列内不同文档之间的自注意力。在对非常长的序列进行持续预训练时,此变化很重要。
词汇表扩展:使用一个包含128K token的词汇表。该词汇表结合了来自tiktoken3 tokenizer的100K个token和28K个额外token,以更好地支持非英语语言。
RoPE基本频率超参数:将RoPE基本频率超参数增加到500,000,这使模型能够更好地支持更长的上下文。
Scaling-Laws设计&模型规模确定
Scaling-Laws实验
Scaling-Laws实验如下所示:
- 首先是得到不同计算量下最优表现的Tokens数:
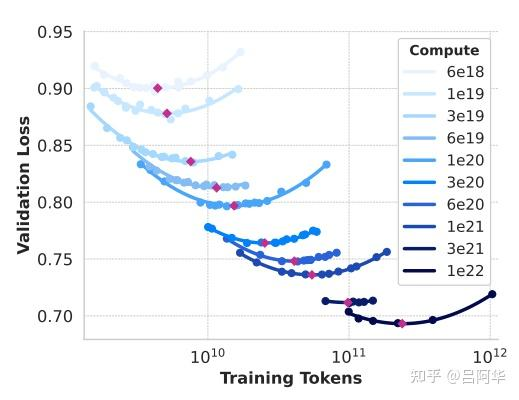
- 然后对计算量C与最优Tokens数的关系N进行拟合,拟合的幂等关系为:$N(C)=AC^\alpha$,最终拟合的结果如下
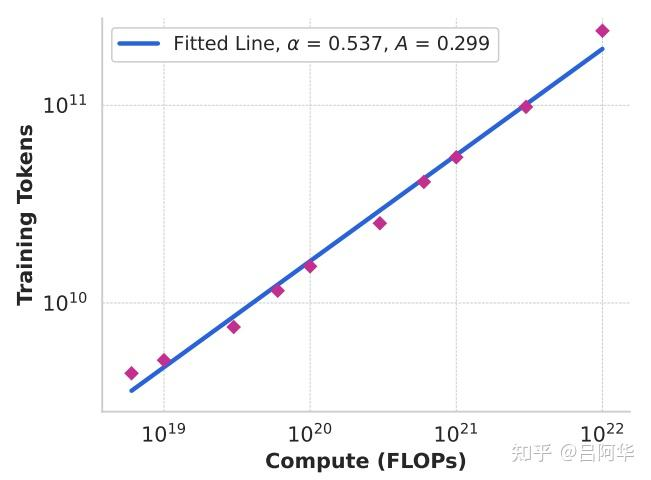
- 将Scaling-Laws外推到3.8*10^25 FLOPs,得到应该在16.55T token上训练一个402B参数模型。考虑到随着计算预算的增加,曲线在最小值附近变得平坦,所以最终选定的是405B参数模型
下游任务Scaling-Laws
前期的尝试使用的是小模型,而旗舰模型的规模确认需要借助Scaling-Laws,但是其还存在一些问题需要解决:
问题:Scaling-Laws主要是预测生成下一个Token的损失,而不是在评测集上的损失
- 解决方案:建立计算最优模型在下游任务上的负对数可能性与训练FLOPs之间的关联性,如下图左所示。
问题:Scaling-Laws可能噪声大且不可靠,因为它们基于小计算预算的预训练运行开发
- 解决方案:利用Scaling-Laws模型和使用更高计算FLOPs训练的旧模型,建立下游任务上负对数可能性与任务准确度之间的关联性。如下图右所示,其添加了Llama 2模型。
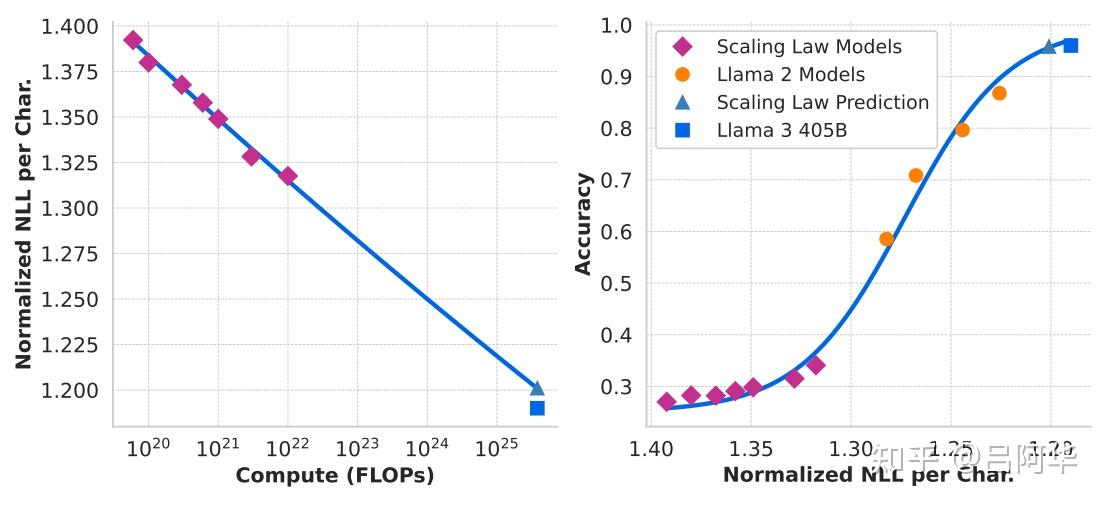
团队发现这种两步扩展法则预测在四个数量级的范围内外推时非常准确:它仅略微低估了Llama 3旗舰模型的最终表现。
基础设施、扩展和效率
基础设施
Llama 3的训练迁移到了Meta的生产集群,从而提高了可靠性:
计算资源:Llama 3 405B在多达16,000个H100 GPU上进行训练,每个服务器配备8个GPU和2个CPU。在一个服务器内,8个GPU通过NVLink连接。训练任务由Meta的全球规模训练调度器MAST调度。
存储资源:Tectonic——Meta的通用分布式文件系统,用于构建Llama 3预训练的存储架构。它提供240PB的存储容量,来自7500台配备SSD的服务器,并支持2TB/s的可持续吞吐量和7TB/s的峰值吞吐量。
网络资源:Llama 3 405B使用基于Arista 7800和Minipack2开放计算项目机架交换机的融合以太网RDMA(RoCE)结构。Llama 3家族中的较小模型使用Nvidia Quantum2 InfiniBand结构进行训练。RoCE和InfiniBand集群都利用了400Gbps的GPU间互连
网络架构采用三层Clos网络架构,连接了24,000个GPU。在底层一个Minipack2机架顶部(ToR)交换机连接2个服务器,每个服务器包含8个GPU。在中层有192个集群交换机连接了3,072个GPU,形成了一个pod。在顶层,同一数据中心建筑内的八个这样的pod通过聚合交换机连接,形成一个24,000个GPU的集群。
此外还有一些网络负载均衡、流量拥塞控制的技术
并行策略及优化
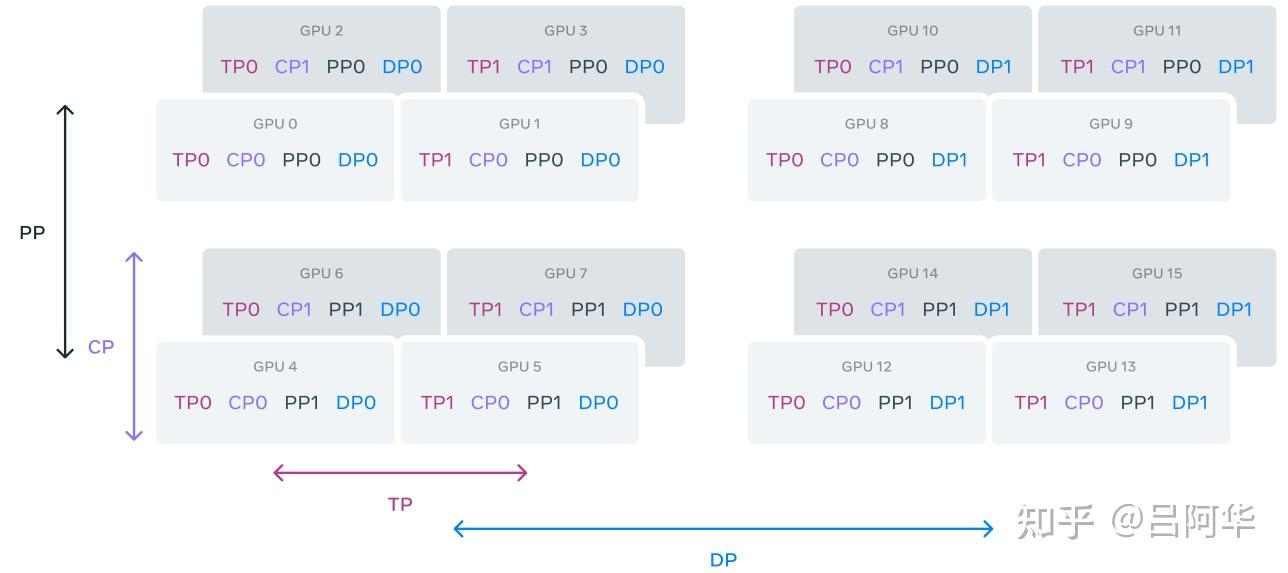
模型训练采用了4D并行,如下图所示,其结合了张量并行(Tensor Parallelism, TP)、流水线并行(Pipeline Parallelism, PP)、上下文并行(Context Parallelism, CP)和完全分片的数据并行(FSDP)。其还做了一些优化:
流水线并行优化:
- 预训练通常需要灵活调整批次大小,但是流水线并行限制了批次大小必须是流水线阶段数量的倍数,所以其修改了流水线调度算法,如下图所示,其使用了交错流水线,层数是4,交错度是2,但是批次选取为了5。

- 此外其也发现流水线的第一阶段由于向量和预热微批次的原因需要更多的内存,第二阶段因为需要计算输出和损失所以需要更多的计算,所以分别从第一阶段和最后一阶段减少一个Transformer层。这意味着第一阶段的第一个模型分块只有向量,而最后一阶段的最后一个模型分块只有输出投影和损失计算。
上下文并行优化:
其利用上下文并行(CP)在扩展Llama 3的上下文长度时提高内存效率,并实现最长可达128,000个长度的序列训练,在CP中,模型沿序列维度进行分割。
不同于现有的CP实现以环形结构重叠通信和计算,Llama 3的CP实现采用了基于全收集的方法,在这种方法中,首先全收集键(K)和值(V)张量,然后计算本地查询(Q)张量块的注意力输出。这有利于支持不同类型的注意力掩码,并且由于使用了GQA,通信的K和V张量比Q张量小得多,因此注意力计算的时间复杂度比全收集大一个数量级,使全收集开销可以忽略不计。
网络感知的并行配置:
基于网络带宽和延迟的需求,团队将并行维度按顺序排列为[TP,CP,PP,DP]。DP(即FSDP)是最外层的并行,因为它可以通过异步预取分片模型权重和减少梯度来容忍更长的网络延迟。最内存的并行需要最高的网络带宽和最低的延迟,因此通常限制在同一服务器内。最外层的并行可以跨越多跳网络,并应能够容忍较高的网络延迟。
其还开发了一个内存消耗估算器和性能投影工具,帮助他们探索各种并行配置,投影整体训练性能并有效识别内存差距。
可靠性优化
可靠性优化:
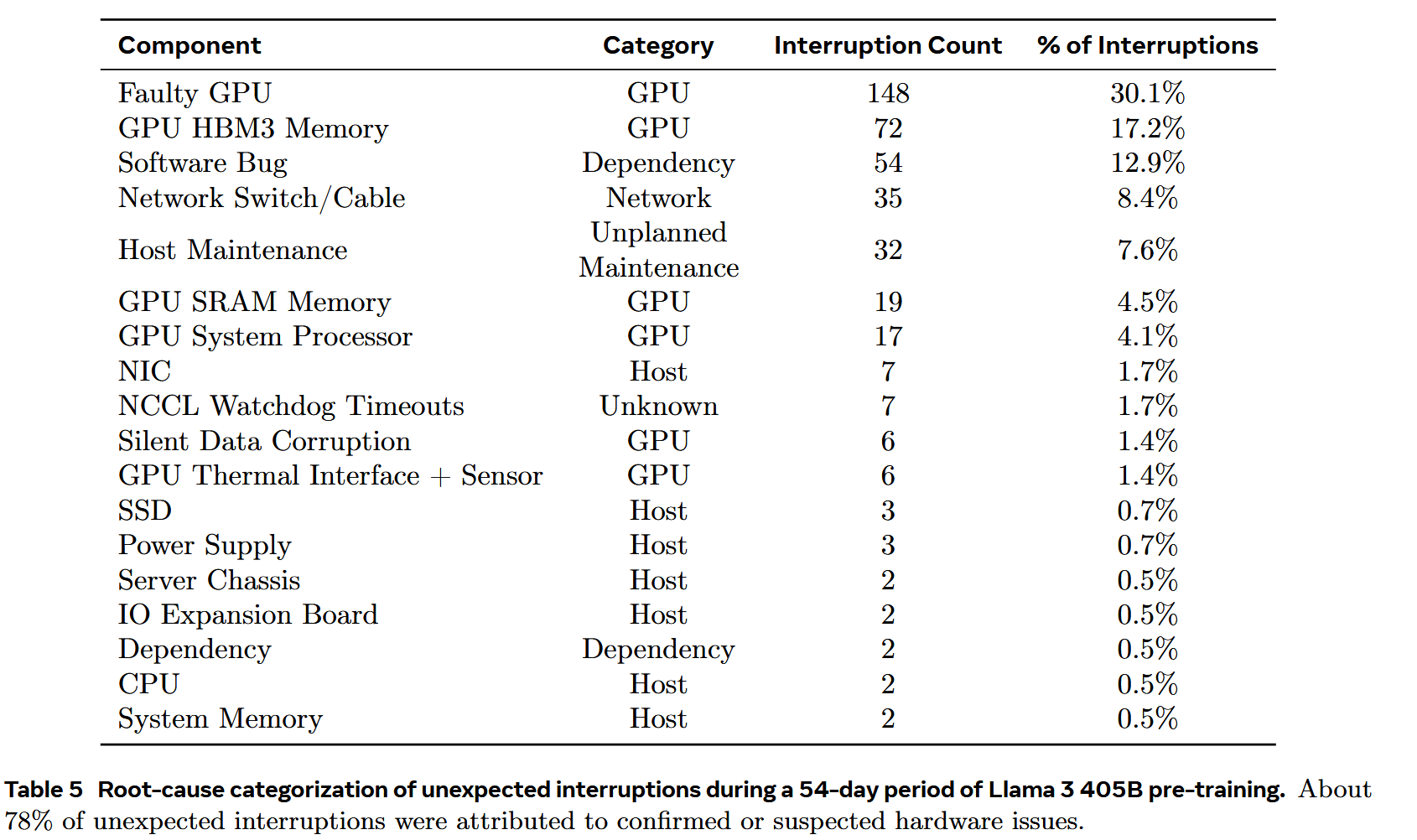
Llama 3在支持自动化集群维护,(如固件和Linux内核升级)的同时,仍实现了超过90%的有效训练时间。在预训练的54天快照期间,团队总共经历了466次作业中断。其中:
47次是由于自动化维护操作(如固件升级)或操作员发起的操作(如配置或数据集更新)而计划的中断
其余419次是计划外的中断,具体见下表,大约78%的非计划中断归因于确认的硬件问题,如GPU或主机组件故障,或疑似与硬件相关的问题,如隐性数据损坏和未计划的单个主机维护事件。GPU问题是最大的类别,占所有非计划问题的58.7%。尽管故障数量众多,但在此期间仅需三次人工干预,其余问题由自动化处理。
预训练流程
预训练Llama 3 405B的流程包括三个主要阶段:(1)初始预训练,(2)长上下文预训练,和(3)退火。
初始预训练
使用AdamW优化器,最大学习率为 8*10^(-5) ,前8000步采用线性预热策略,然后在120万步内按余弦学习率计划逐步衰减至 8*10^(-7)。
批次大小调整:
训练初期采用较小的批次大小(初始批次大小为4M tokens,序列长度为4096)以提高稳定性
训练了252M tokens后,将批次大小和序列长度加倍至8M和8192 tokens以提高效率
预训练了2.87T tokens后,再次将批次大小加倍至16M
数据配比调整:
在训练过程中增加了非英语数据的比例,以提高Llama 3的多语言性能
还增加了数学数据的比例,以提高模型的数学推理能力
在预训练的后期阶段,增加了更近期的网络数据以更新模型的知识截止点,同时减少了质量较低的数据子集。
长上下文预训练
因为自注意力层的计算量随序列长度呈二次增长,所以为了节省训练成本,没有在早期阶段使用长序列进行训练
其逐步增加支持的上下文长度,直到模型成功适应增加的上下文长度。通
- 过评估模型在短上下文任务中的表现是否完全恢复,以及模型是否能够完美解决“大海捞针”任务来判断是否成功适应
其分六个阶段拓展上下文窗口,从最初的8K上下文窗口开始,最终达到128K上下文窗口
长上下文预训练阶段使用了大约800B的训练tokens。
退火
在预训练的最后40M tokens期间,在保持128K tokens的上下文长度下,其线性地将学习率退火至0。
在退火阶段,增加了高质量的数据源比例。
最终在退火期间计算模型检查点的平均值(Polyak平均化),以生成最终的预训练模型。
总结
非常详细的技术报告,能够学到很实际的训练流程,但是“纸上得来终觉浅,绝知此事要躬行”,希望后面有机会深度参与了。
整体看完确实也拓展了眼界,在整个预训练过程中除了需要关注并行策略外,还需要关注数据构造、模型规模设计,以及训练流程中学习率、批次配置、数据配比的变化等。