【Megatron-LM源码分析(一)】-环境配置与训练示例跑通
环境配置
- 下载代码:
1 | |
- 切换到稳定分支:
1 | |
- 拉取指定docker镜像:
1 | |
最小示例
示例运行流程
- 进入Docker容器,将本地的
Megatron-LM挂载到宿主机的/workspace/megatron-lm上注意这里只将GPU0和GPU1引入进容器里,并且使用的是16GB的共享内存。注意将/home/xxx/Megatron-LM换成自己的本地路径。
1 | |
- 进入megatron-lm目录,运行最小示例:
1 | |
- 查看运行结果,虽然会有一些warning,但是还是能正常运行结束的。
最小示例解读
下面解读一下这最小示例examples/run_simple_mcore_train_loop.py的代码:
1 | |
初始化阶段
销毁之前的模型并行状态
获取本地rank和world_size(GPU数量)
设置当前进程使用的CUDA设备
初始化PyTorch分布式进程组
初始化Megatron-Core的模型并行:张量并行度=2,流水线并行度=1,这是稍微复杂一些的地方,其主要作用为:
依据输入的并行参数以及默认参数计算各种关键并行参数,并进行参数检查,例如检查如下的内容:
1
2
3
4model_size = tensor_model_parallel_size * pipeline_model_parallel_size * context_parallel_size
if world_size % model_size != 0:
raise RuntimeError(f"world_size ({world_size}) is not divisible by {model_size}")其还创建了各种dp、tp、pp、ep、cp的通信组
torch.distributed.new_group,并通过全局变量进行传递。(怎么这么多全局变量啊。。。)
模型构建
构建了
TransformerConfig,其层数为2,隐藏层维度为12,注意力头数量为4然后依据
TransformerConfig以及其他参数(词表大小100,最大序列长度64)构建了GPT模型
优化器构建
- 使用
gpt_model.parameters()来初始化了torch原生的Adam优化器
数据准备
创建数据集配置:
使用_NullTokenizer(虚拟分词器)
序列长度64
不重置position_ids和attention_mask
构建混合数据集:
使用MockGPTDataset(模拟数据集,用于测试)
1000个样本
创建torch原生的DataLoader,并用迭代器进行包装:
batch_size=8
shuffle=True
训练循环
获取
forward_backward_func- 该函数提供了如何根据
data_iterator获取数据,然后使用模型计算出output_tensor,并最终返回了output_tensor, partial(loss_func, loss_mask)
- 该函数提供了如何根据
训练了5个迭代
模型保存与加载
调用
gpt_model.sharded_state_dict()获取分片状态字典使用
dist_checkpointing.save()保存每个GPU只保存自己的模型分片
支持张量并行、流水线并行的自动分片
GPT训练示例
分词器准备
- 直接使用GPT-2 的 tokenizer,下载方式如下:
1 | |
vocab是每个token对应的序号,merges表示如何两两token合并为一个大token
训练数据准备
使用的是TinyStories,hugging face链接为:https://huggingface.co/datasets/roneneldan/TinyStories/tree/main
它包含训练集和测试集,而实际上Megatron-LM也支持自动切分数据集为训练集和测试集、验证集,所以这里只下载了训练集:
1 | |
- 由于Megatron-LM处理的数据集基本格式是jsonl,所以这里使用了一个脚本
txt_convert_to_jsonl.py进行格式转化,如下,在容器中运行该脚本后会得到data/TinyStoriesV2-GPT4-valid.jsonl
1 | |
- 然后还需要用Megatron-LM的脚本借助分词器进一步转化为bin+idx的格式。运行脚本如下,最终会得到
data/TinyStoriesV2-GPT4-train_text_document.bin和data/TinyStoriesV2-GPT4-train_text_document.idx
1 | |
857m GPT3模型训练脚本
在examples/gpt3下有175b的GPT模型训练的脚本train_gpt3_175b_distributed.sh,不过可惜我只有4块4090,所以我稍微修改了一下脚本,改为训练其给出的857m的模型,该训练脚本train_gpt3_857m_distributed.sh如下所示:
1 | |
改变的内容有:
在GPT模型结构上,修改为:
num-layers 24
hidden-size 1024
num-attention-heads 16
为了避免显存不足,训练步数train-iters改为10000,global-batch-size改为16,取消rampup-batch-size
并行训练策略改为TP度为2,PP度也为2
注意这些只是为了能跑起来写的,参数没有得到很好的设计
857m GPT3模型训练
- 首先进入容器内,这次将本地全部4块GPU都挂载进去:
1 | |
- 创建tb_log、checkpoint需要的文件夹
1 | |
- 直接执行下面这个脚本训练即可:
1 | |
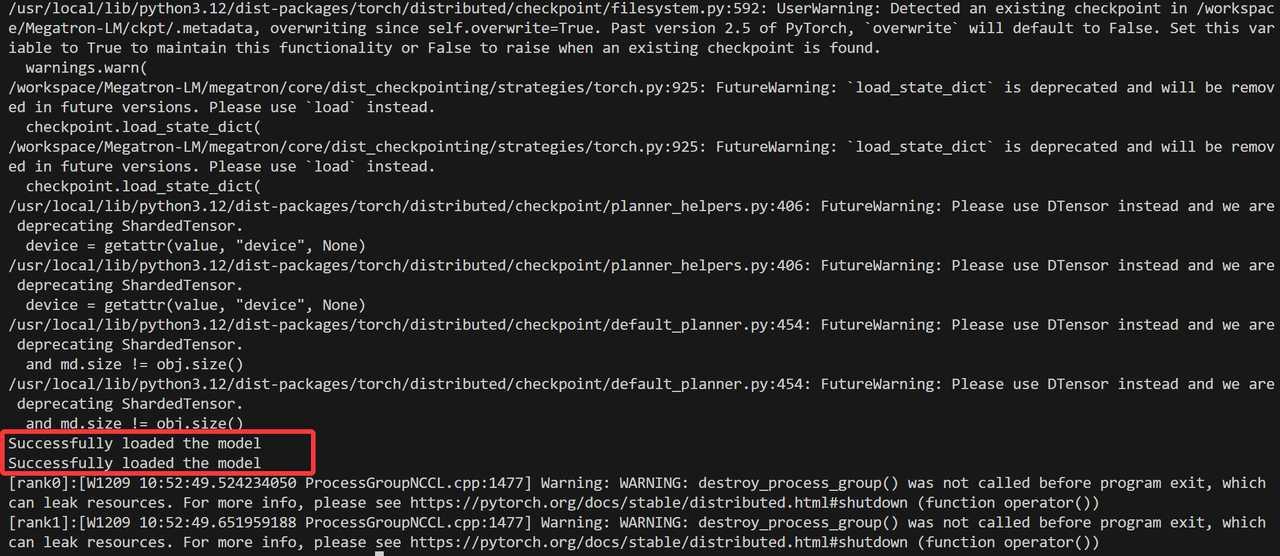
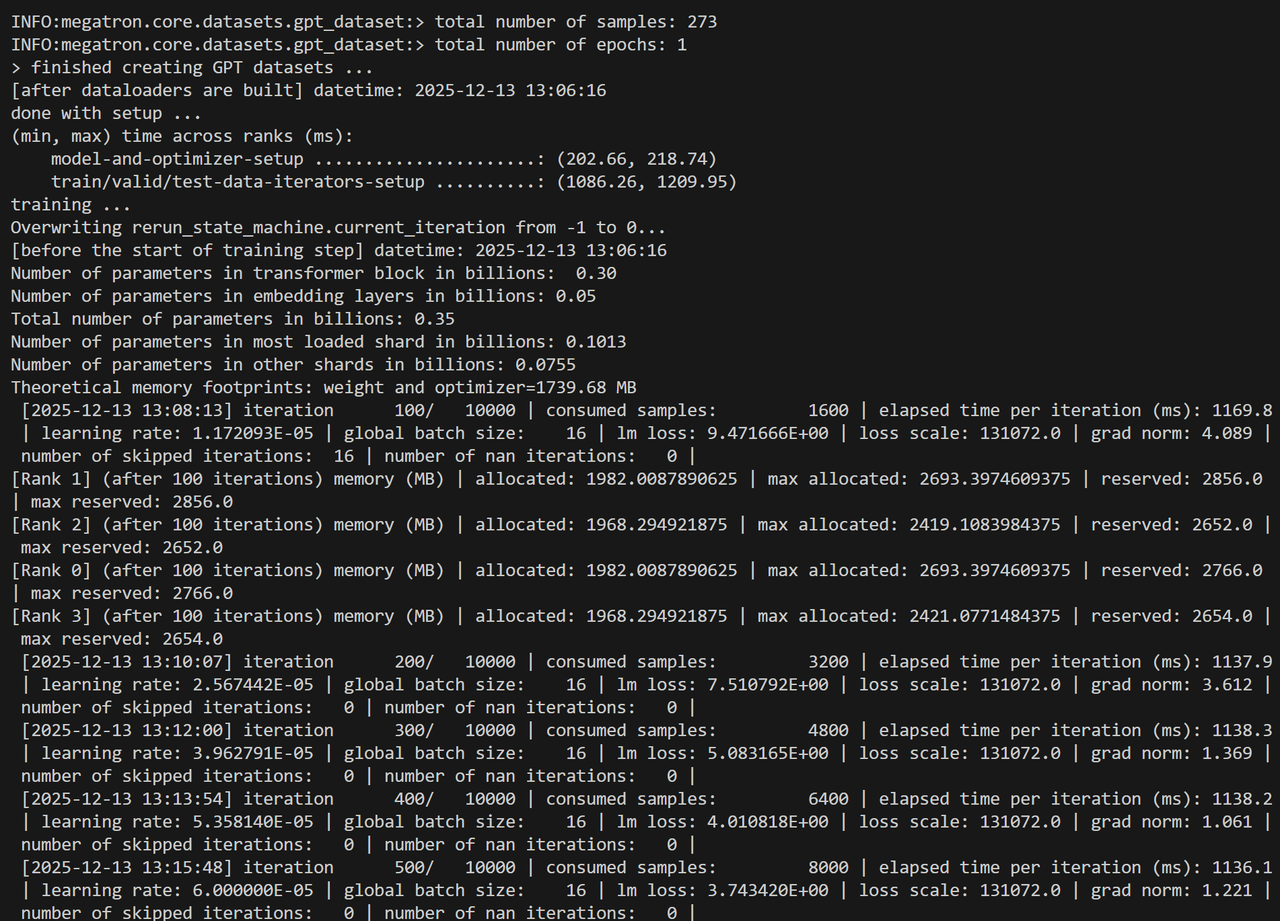
- 运行截图如下所示:
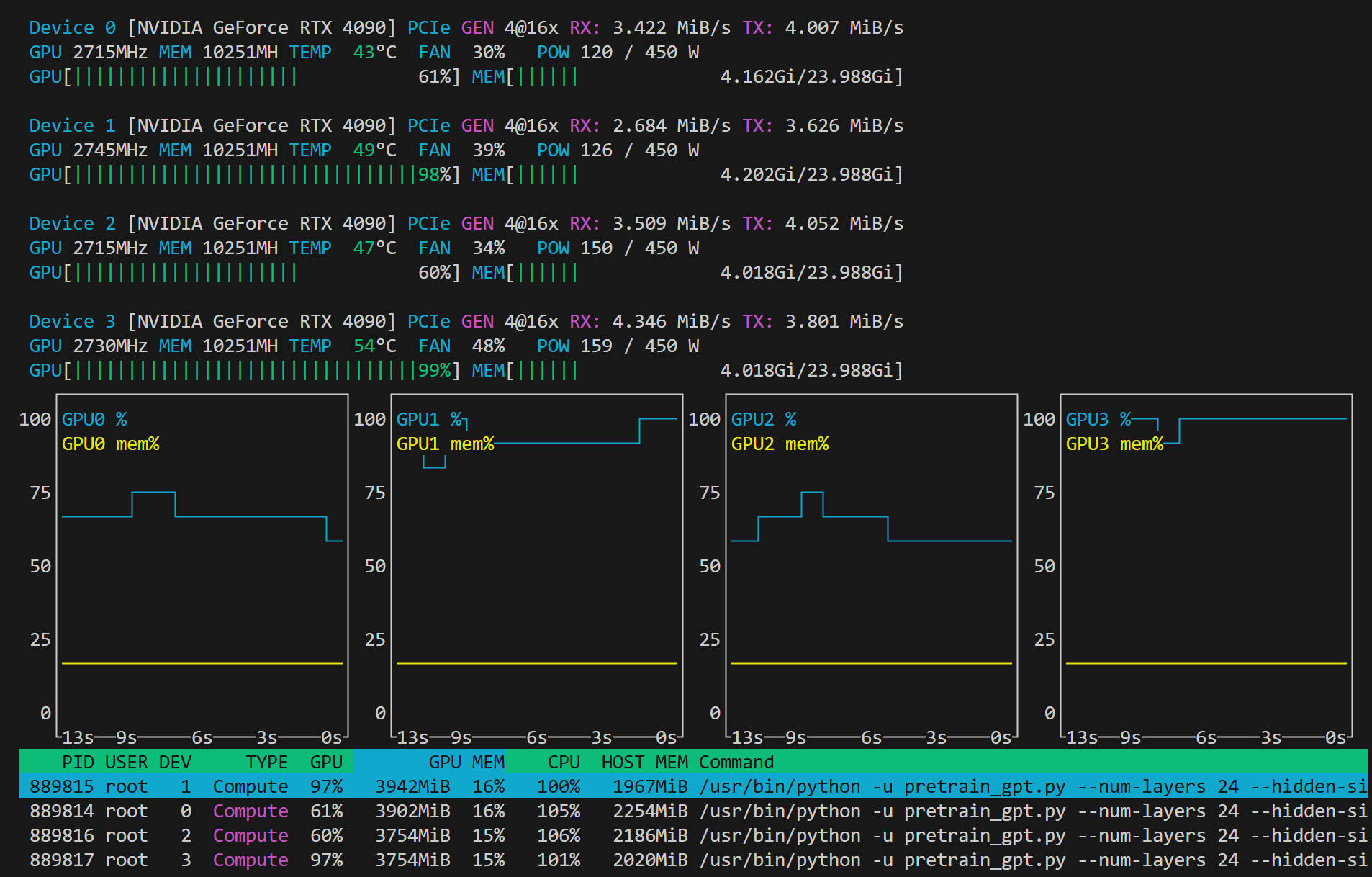
- nvtop查看GPU占用情况如下图所示