【论文阅读】ScheMoE:An Extensible Mixture-of-Experts Distributed Training System with Tasks Scheduling
发表会议:EuroSys ‘24(CCF-A)
团队:哈工大、香港科技、华为
背景
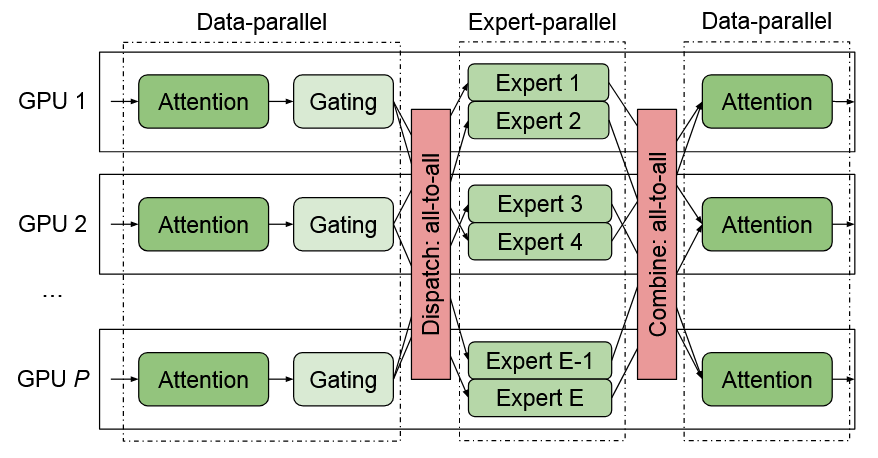
- Moe架构的大模型愈发流行,而Moe流程中存在将数据通过通信转发给对应GPU上专家的行为,如下图是数据并行与专家并行的示例,这种通信行为会导致系统训练效率降低。
现有的优化Moe训练效率的方法有正交的3类:
设计负载平衡的路由函数,使GPU计算更加平衡
设计高效的通信方法,如节点间和节点内分层的All2All算法、数据压缩算法
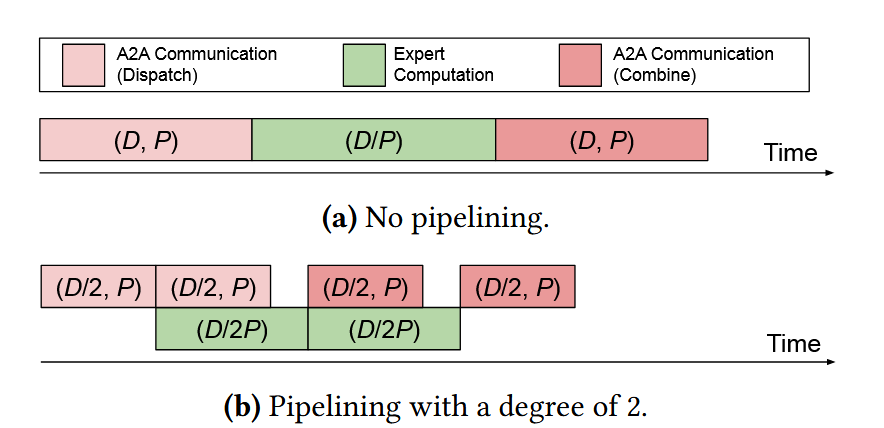
通过将大矩阵转化为小矩阵来允许设计任务调度算法流水线并行通信任务和计算任务
在系统优化方面,上述的b、c更加重要,而现有相关的Moe优化系统的主要不足在于:
可拓展性不足,难以有效支持新的通信优化算法
All2All优化算法在利用集群内的节点间与节点内带宽有不足
调度算法在并行通信任务和计算任务方面最次优
故本文提出了一个具有最优任务调度的可扩展且高效的MoE系统ScheMoE,该系统支持对关键操作的高效模块化拓展,并提出了自适应最优调度算法来流水线通信和计算任务,提出了一种All2All通信优化算法Pipe-A2A。
方法思路
ScheMoE系统
对于一个经典的MoE系统,其一个模块主要包含7个事件,如下图所示:
压缩
A2A
解压
专家计算
压缩
A2A
解压
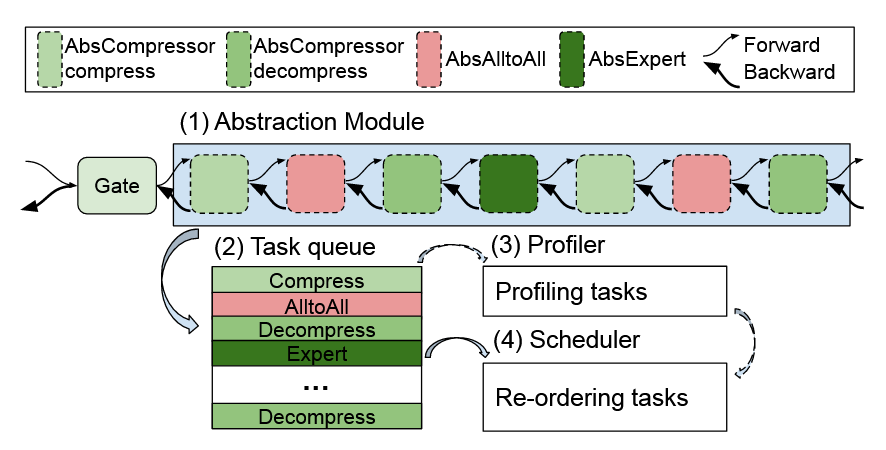
系统在设计时对这些流程中的计算任务(数据压缩、数据解压和专家计算)和通信任务(A2A通信)都做了良好的抽象,用户可以通过拓展基础类继续实现自己的方法
系统还有自己的任务队列、分析器与任务调度器(方便拓展自定义调度算法)
调度优化
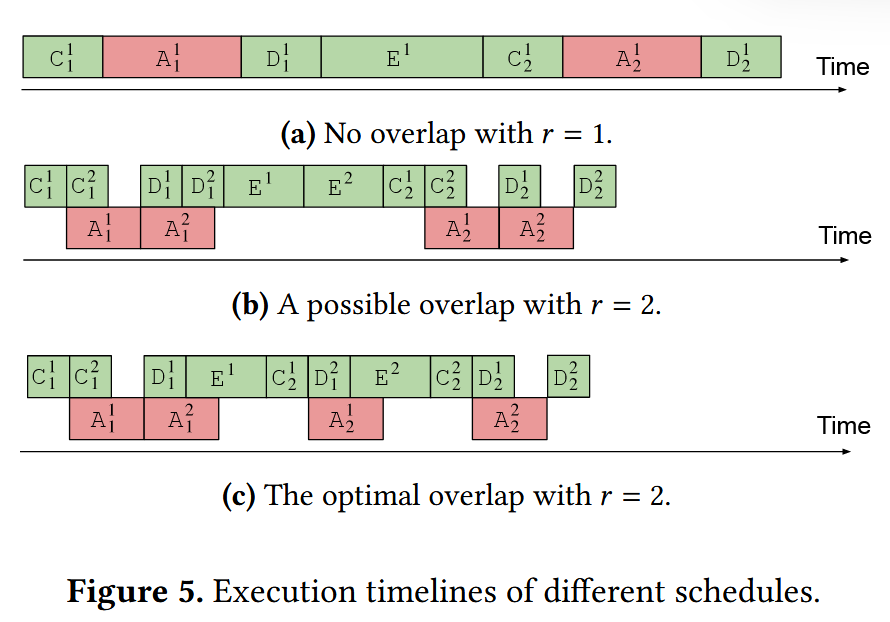
其依旧使用将大矩阵转化为小矩阵的流水线并行的方法,并且限制只有计算与通信可以折叠
通过理论分析得出在这种多套7个事件并行重叠中最优结果的一些规律,使得最终最优重叠如下图(c)所示
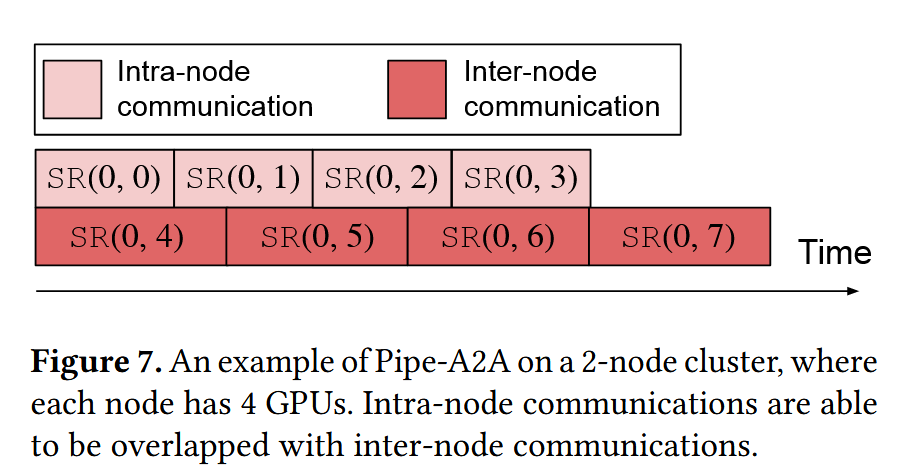
通信优化
- 其引入了两个异步通信流,分别是节点内通信流和节点间通信流,从而允许这两个通信流可以并行执行,如下图所示,这样就使得相比顺序执行速度更快
实验效果
- 实验在具有8个节点、32GPU的集群上开展,实验验证了各个子优化算法的有效性,并且实验验证了ScheMoE平均比现有最先进系统快1.09×-1.3倍。
总结
对MoE系统的讲解还是很受益的
本文的重点还是在提出系统方面,算法方面的创新感觉并不强,对于这类就7个流程下的计算与通信的重叠可能能继续深挖的点确实也不多,此外这个通信优化还是有点疑虑,应该是一个很明显的优化点才对,之前的工作肯定也有尝试过,可能还是存在某些情况使得两个异步通信流不是很受欢迎。