【Megatron-LM源码分析(二)】-GPT模型pretrain流程
本次查看Megatron-LM的版本是core_r0.14.0,查看的GPT训练文件是pretrain_gpt.py
入口函数
main入口函数代码如下:
1 | |
其功能主要为:
临时函数,告诉数据集构建器这是一个分布式训练环境,需要在多个进程间协调数据集构建
可选地启用进程内重启功能,为训练函数添加故障恢复能力,允许在 GPU 故障时自动重启而不中断整个作业
调用核心pretrain函数并传入自定义相关函数作为参数进行训练
进程重启功能
其调用的是maybe_wrap_for_inprocess_restart函数,如下所示:
1 | |
其主要功能是查看是否带有inprocess_restart启动参数,如果没有就不操作,如果有就继续操作,包括:
调用inprocess_restart对pretrain关键函数进行包装
创建TCPStore,TCPStore类似于是一个分布式KV存储系统,充当控制面。它作用有:
底层采用TCP协议,所以如果NCCL或训练的通信组出错也不会受影响。注意使用的是
int(os.environ['MASTER_PORT']) + 1端口,以避免端口冲突wait_for_workers=True参数确保等待所有worker都正常运行用以控制保证所有的worker都进入了新一轮的训练
其容错的运行流程类似如下
1 | |
不过注意的是如果一个节点确实损坏了,它无法找到新的节点来替代,只能不断地重启了,除非有足够的热备节点
调用inprocess_restart对pretrain关键函数进行包装的代码如下:
1 | |
其主要功能为:
查看是否成功从
import nvidia_resiliency_ext.inprocess as inprocess引入inprocess,如果没有就直接返回提醒设置日志级别
构建Layers:(这里的Layers有啥作用没咋看懂)
设置最小 / 最大存活 rank以及是否采用RESERVE模式
如果是node粒度还需要再构建node层级的layers,以做到node级别的移除
构建 abort 之后 / restart 之前 执行的清理逻辑finalize,包含的处理逻辑有
destroy_state:destroy process group
释放 NCCL communicator
清理 Megatron 内部全局状态
empty_cache(可选):清除从cache
在OOM场景下很有用
再就是构建状态机中Initialize / Abort / Completion / Terminate这四个状态:
initialize:等待至少
min_world_size个 rank 可用abort(失败时触发):负责停 Transformer Engine,abort torch.distributed,通知 nested restarter开始重启
completion(正常结束):标记这一轮执行完成,不触发 restart
terminate(彻底失败): 直接终止,不再尝试恢复
包装训练函数:
设置了上述的状态机
设置了很多timeout
将端口设置为
int(os.environ['MASTER_PORT']) + 2以避免端口冲突
pretrain参数
pretrain是训练的核心入口,它更加类似于一个训练流程的驱动,用户负责通过参数提供数据、模型、loss计算方法等,它负责对其进行组装然后将分布式训练策略、checkpoint、log等方法进行执行。
其函数定义如下,下面对其进行分组介绍:
1 | |
数据相关参数
train_valid_test_dataset_provider负责告诉Megatron如何划分出train_ds、valid_ds、test_ds这3类数据集。- 本示例中传入的函数如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27def train_valid_test_datasets_provider(train_val_test_num_samples):
"""Build the train test and validation datasets.
Args:
train_val_test_num_samples : A list containing the number of samples in train test and validation.
"""
args = get_args()
config = core_gpt_dataset_config_from_args(args)
if args.sft:
dataset_type = SFTDataset
else:
if args.mock_data:
dataset_type = MockGPTDataset
else:
dataset_type = GPTDataset
print_rank_0("> building train, validation, and test datasets for GPT ...")
train_ds, valid_ds, test_ds = BlendedMegatronDatasetBuilder(
dataset_type, train_val_test_num_samples, is_dataset_built_on_rank, config
).build()
print_rank_0("> finished creating GPT datasets ...")
return train_ds, valid_ds, test_ds其输入参数为
train_val_test_num_samples,如注释所言,其代表的train、val、test对应的sample的数量在函数里其根据参数得到
dataset_type然后还有函数
is_dataset_built_on_rank作为参数,该函数用于决定是否在当前进程构建数据集,其函数如下,实际效果是只在PP并行组的第一个和最后一个中的TP组的第一个rank构建数据集。
1
2
3
4
5def is_dataset_built_on_rank():
return (
parallel_state.is_pipeline_first_stage(ignore_virtual=True)
or parallel_state.is_pipeline_last_stage(ignore_virtual=True)
) and parallel_state.get_tensor_model_parallel_rank() == 0然后其构建了
BlendedMegatronDatasetBuilder这个数据集处理类,并调用其build()函数得到了train_ds, valid_ds, test_ds。BlendedMegatronDatasetBuilder的功能主要如下,后面会再找机会详细介绍负责从多个数据源构建混合数据集
支持分布式训练环境下的数据集协调
提供高效的数据集缓存和并行构建机制
模型相关参数
model_provider参数负责提供一个原始模型,即提供一个在CPU上的没有进行fp16转换没有ddp切割的原始模型。- 本示例中传入的函数如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103def model_provider(
pre_process=True, post_process=True, vp_stage: Optional[int] = None
) -> Union[GPTModel, megatron.legacy.model.GPTModel]:
"""Builds the model.
If you set the use_legacy_models to True, it will return the legacy GPT model and if not the mcore GPT model.
Args:
pre_process (bool, optional): Set to true if you need to compute embedings. Defaults to True.
post_process (bool, optional): Set to true if you need to want to compute output logits/loss. Defaults to True.
Returns:
Union[GPTModel, megatron.legacy.model.GPTModel]: The returned model
"""
args = get_args()
if has_nvidia_modelopt and modelopt_args_enabled(args): # [ModelOpt]
return model_provider_modelopt(pre_process, post_process)
use_te = args.transformer_impl == "transformer_engine"
if args.record_memory_history:
torch.cuda.memory._record_memory_history(
True,
# keep 100,000 alloc/free events from before the snapshot
trace_alloc_max_entries=100000,
# record stack information for the trace events
trace_alloc_record_context=True,
)
def oom_observer(device, alloc, device_alloc, device_free):
# snapshot right after an OOM happened
print('saving allocated state during OOM')
snapshot = torch.cuda.memory._snapshot()
from pickle import dump
dump(
snapshot,
open(f"oom_rank-{torch.distributed.get_rank()}_{args.memory_snapshot_path}", 'wb'),
)
torch._C._cuda_attach_out_of_memory_observer(oom_observer)
print_rank_0('building GPT model ...')
# Experimental loading arguments from yaml
if args.yaml_cfg is not None:
config = core_transformer_config_from_yaml(args, "language_model")
else:
config = core_transformer_config_from_args(args)
if args.use_legacy_models:
model = megatron.legacy.model.GPTModel(
config,
num_tokentypes=0,
parallel_output=True,
pre_process=pre_process,
post_process=post_process,
)
else: # using core models
if args.spec is not None:
transformer_layer_spec = import_module(args.spec)
else:
if args.num_experts:
# Define the decoder block spec
transformer_layer_spec = get_gpt_decoder_block_spec(
config, use_transformer_engine=use_te, normalization=args.normalization, qk_l2_norm=args.qk_l2_norm, vp_stage=vp_stage
)
elif args.heterogeneous_layers_config_path is not None:
transformer_layer_spec = get_gpt_heterogeneous_layer_spec(config, use_te)
else:
# Define the decoder layer spec
transformer_layer_spec = _get_transformer_layer_spec(use_te, config)
mtp_block_spec = None
if args.mtp_num_layers is not None:
if hasattr(transformer_layer_spec, 'layer_specs') and len(transformer_layer_spec.layer_specs) == 0:
# Get the decoder layer spec explicitly if no decoder layer in the last stage,
# Only happens with block spec (TransformerBlockSubmodules) when using MoE.
transformer_layer_spec_for_mtp = _get_transformer_layer_spec(use_te, config)
else:
transformer_layer_spec_for_mtp = transformer_layer_spec
mtp_block_spec = get_gpt_mtp_block_spec(
config, transformer_layer_spec_for_mtp, use_transformer_engine=use_te, vp_stage=vp_stage
)
model = GPTModel(
config=config,
transformer_layer_spec=transformer_layer_spec,
vocab_size=args.padded_vocab_size,
max_sequence_length=args.max_position_embeddings,
pre_process=pre_process,
post_process=post_process,
fp16_lm_cross_entropy=args.fp16_lm_cross_entropy,
parallel_output=True,
share_embeddings_and_output_weights=not args.untie_embeddings_and_output_weights,
position_embedding_type=args.position_embedding_type,
rotary_percent=args.rotary_percent,
rotary_base=args.rotary_base,
rope_scaling=args.use_rope_scaling,
mtp_block_spec=mtp_block_spec,
vp_stage=vp_stage,
)
return model该函数的参数为:
pre_process: 是否计算嵌入层(输入处理)post_process: 是否计算输出 logits/损失vp_stage: 虚拟 pipeline stage(用于梯度累积优化)
获取训练参数,如果启用 NVIDIA ModelOpt,委托给专门的 model provider
依据参数决定是否使用 Transformer Engine(NVIDIA 的高性能 transformer 实现)
依据参数决定是否启用内存历史记录用于调试 OOM 问题,以及是否自动保存内存快照到文件
依据yaml文件或者是输入参数args获取config
然后进入核心模型分支,依据参数获取transformer_layer_spec和mtp_block_spec
最后根据各参数构建出GPTModel
model_type:用于告诉 Megatron 模型的“拓扑语义”,其有这三类:encoder_or_decoder = 1:传统的编码器-解码器模型,或仅包含解码器的自回归模型
retro_encoder = 2:Retrieval-Enhanced Transformer (RETRO) 模型中的编码器组件,RETRO 是一种特殊的 transformer 架构,使用外部知识库进行检索增强
retro_decoder = 3:RETRO 模型中的解码器组件,负责最终的文本生成
get_embedding_ranks:指定哪些 rank 持有 word embeddingget_position_embedding_ranks:指定哪些 rank 持有 position embedding
Forward执行参数
forward_step_func:最核心的训练函数,其定义了一次 iteration 的“前向 + loss 计算”逻辑,
其主要负责:
从
data_iterator里取 batch调用
model(...)计算 loss
返回:
loss(标量 tensor)
dict(用于 logging 的指标)
示例中的代码如下所示,基本与上述功能一样,但是返回不一样了,合理怀疑是现在代码改了但是注释没改,返回的是计算结果以及计算loss的组合,此外还多了一些指标采集和专门的分支处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39def forward_step(data_iterator, model: GPTModel, return_schedule_plan: bool = False):
"""Forward training step.
Args:
data_iterator : Input data iterator
model (GPTModel): The GPT Model
return_schedule_plan (bool): Whether to return the schedule plan instead of the output tensor
"""
args = get_args()
timers = get_timers()
# Get the batch.
timers('batch-generator', log_level=2).start()
global stimer
with stimer(bdata=True):
tokens, labels, loss_mask, attention_mask, position_ids = get_batch(data_iterator)
timers('batch-generator').stop()
with stimer:
if args.use_legacy_models:
output_tensor = model(tokens, position_ids, attention_mask, labels=labels)
else:
if return_schedule_plan:
# MoE 专家并行重叠通信模式
assert args.overlap_moe_expert_parallel_comm, \
"overlap_moe_expert_parallel_comm must be enabled to return the schedule plan"
schedule_plan = model.build_schedule_plan(
tokens, position_ids, attention_mask, labels=labels, loss_mask=loss_mask
)
return schedule_plan, partial(loss_func, loss_mask, model=model)
else:
# 标准前向传播
output_tensor = model(
tokens, position_ids, attention_mask, labels=labels, loss_mask=loss_mask
)
# [ModelOpt]: model is needed to access ModelOpt distillation losses
return output_tensor, partial(loss_func, loss_mask, model=model)- 其中的get_bach也是自定义的,如下,依据rank所属的并行组来获取数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def get_batch(data_iterator):
"""Generate a batch."""
# TODO: this is pretty hacky, find a better way
if (not parallel_state.is_pipeline_first_stage(ignore_virtual=True)) and (
not parallel_state.is_pipeline_last_stage(ignore_virtual=True)
):
return None, None, None, None, None
# get batches based on the TP rank you are on
batch = get_batch_on_this_tp_rank(data_iterator)
# slice batch along sequence dimension for context parallelism
batch = get_batch_on_this_cp_rank(batch)
return batch.values()
process_non_loss_data_func:可选参数,用来处理不参与反向传播的数据,例如专门把一些数据dump到TensorBoardnon_loss_data_func:在 evaluation 阶段执行自定义逻辑
参数与配置扩展
extra_args_provider:允许“业务代码”向 Megatron 的 argparse 注入自定义参数args_defaults:覆盖 / 预设 Megatron 参数默认值
分布式 / 容错相关参数
store:提供一个外部的控制接口,如前述进程重启功能所示,在实例中就将控制面TCPStore传递给了该参数inprocess_call_wrapper: in-process restart 自动注入的“调用包装器”,负责捕获:Python exception、CUDA error,然后上报给 inprocess controller,决定是retry还是abort或是terminate等,普通用户不用传,开启 inprocess_restart 时自动生效
pretrain流程概览
- pretrain的代码如下所示,上面已经对pretrain的传入参数进行了解析,下面先对其整体流程做进一步梳理
1 | |
初始化
如果参数
inprocess_call_wrapper不为空,说明需要容错,那么再次进入pretrain的时候,为了避免还接入到原本的控制面,需要调用inprocess_call_wrapper.iteration进行命名空间更新,来接入新的store。初始化megatron-lm的通信组、并行设置、关键参数等等,下面会具体介绍
获取全局参数,megatron-lm是单例设计,获取参数都是通过
get_*来通过获取全局变量获得FT(Fault Tolerance)初始化,FT更偏向于是利用checkpoint进行容错,inprocess是对进程运行时的容错
设置PyTorch JIT fusion进行算子融合,如果有必要还会对其进行预热
通过min操作的all reduce来获取最小的训练开始时间,已记录相关日志
如果参数控制需要不落盘的内存级的checkpoint,就引入相关的包并设置对应的上下文
根据并行化策略等得到model、optimizer、opt_param_scheduler,下面会具体介绍
构建数据迭代器,如果采用了Virtual Pipeline并行,那么每个 pipeline stage都会有自己专门的 data iterator
训练
- 如果参数指示跳过train,那么就不执行train,继续执行后面的,如果没有,那么就执行
iteration, num_floating_point_operations_so_far = train(...)进行训练,下面会具体介绍。并且如果迭代次数不是保存checkpoint的倍数那么就会专门对最后的模型进行保存
收尾
如果参数指示需要valid,那么就调用
evaluate_and_print_results使用valid_data_iterator获取数据执行一次valid,下面会具体介绍如果参数指示需要test,那么就调用
evaluate_and_print_results使用test_data_iterator获取数据执行一次test得到wandb的句柄并关闭
确保async checkpoint 完成,并将所有 IO 收尾
关闭FT和Logger
pretrain核心流程解析
initialize_megatron
initialize_megatron代码如下:
1 | |
initialize_megatron流程如下:
检查是否包含cuda
解析参数,注意这里还使用了
pretrain函数传递进来的extra_args_provider对checkpoint做格式转换并考虑从checkpoint中获取训练参数,如果使用异步checkpoint还负责启动保存checkpoint的IO worker
校验参数,设置全局参数
初始化日志
初始化容错的rerun状态机
如果使用
lazy_mpu_init,就先设置一些模型并行参数,返回finish_mpu_init,等待外部调用其初始化如果不使用
lazy_mpu_init,就先调用finish_mpu_init初始化,再自动从 checkpoint 恢复,再提前编译依赖,再做 TP 通信重叠初始化。
finish_mpu_init
finish_mpu_init是初始化的核心模块,其代码如下:
1 | |
finish_mpu_init流程如下:
调用
_initialize_distributed初始化通信组设置随机随机种子,Megatron 的 RNG 体系是:DP 可以不同,TP / PP 必须一致
如果是专家并行,还需要设置MoE 辅助损失缩放
_initialize_distributed
对于关键的_initialize_distributed,其代码如下:
1 | |
流程如下:
通过
torch.distributed.is_initialized()检查是否初始化torch.distributed,如果没有就调用torch.distributed.init_process_group(**init_process_group_kwargs)初始化。注意这里使用了pretrain传入的TCPStore。然后为了防止 NCCL communicator 因进程重启而失效,还强制触发一次 NCCL 初始化。检查设备数是否大于0,如果是就检查是否已经进行模型并行初始化,如果没有就调用
mpu.initialize_model_parallel进行初始化。
mpu.initialize_model_parallel代码如下:
1 | |
mpu.initialize_model_parallel的核心目的是依据并行策略设置创建一堆并行通信组,实现各worker的rank与并行组的映射。这包括了TP、PP、DP、Context Parallel(CP)、Expert Parallel(EP)。其首先构建了一个
RankGenerator,这是rank与并行组匹配的核心RankGenerator的相关代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185class RankGenerator(object):
"""A class for generating rank groups for different modes of parallelism."""
def __init__(
self, tp: int, ep: int, dp: int, pp: int, cp: int, order: str, rank_offset: int = 0
) -> None:
assert (
ep == 1 or cp == 1
), "Both EP and CP > 1 in not allow in one rank generator. \
CP is only included in default RankGenerator, and EP only in expert RankGenerator."
self.tp = tp
self.ep = ep
self.dp = dp
self.pp = pp
self.cp = cp
self.rank_offset = rank_offset
self.world_size = tp * dp * pp * cp * ep
self.name_to_size = {
"tp": self.tp,
"pp": self.pp,
"dp": self.dp,
"ep": self.ep,
"cp": self.cp,
}
self.order = order
order = order.lower()
for name in self.name_to_size.keys():
if name not in order and self.name_to_size[name] != 1:
raise RuntimeError(
f"The size of ({name}) is ({self.name_to_size[name]}), but you haven't"
f"specified the order ({self.order})."
)
elif name not in order:
order = order + "-" + name
self.order = order
self.ordered_size = []
for token in order.split("-"):
self.ordered_size.append(self.name_to_size[token])
def get_mask(self, order: str, token: str):
"""Create a mask for the specified tokens based on the given order.
Args:
order (str): The order of parallelism types (e.g., 'tp-dp-pp').
token (str): The specific parallelism types to include in the mask,
separated by hyphens (e.g., 'tp-dp').
"""
ordered_token = order.split("-")
token_list = token.split("-")
mask = [False] * len(ordered_token)
for t in token_list:
mask[ordered_token.index(t)] = True
return mask
def get_ranks(self, token):
"""Get rank group by input token.
Args:
token (str):
Specify the ranks type that want to get. If we want
to obtain multiple parallel types, we can use a hyphen
'-' to separate them. For example, if we want to obtain
the TP_DP group, the token should be 'tp-dp'.
"""
mask = self.get_mask(self.order, token)
ranks = generate_masked_orthogonal_rank_groups(self.world_size, self.ordered_size, mask)
if self.rank_offset > 0:
for rank_group in ranks:
for i in range(len(rank_group)):
rank_group[i] += self.rank_offset
return ranks
def generate_masked_orthogonal_rank_groups(
world_size: int, parallel_size: List[int], mask: List[bool]
) -> List[List[int]]:
r"""Generate orthogonal parallel groups based on the parallel size and mask.
Arguments:
world_size (int): world size
parallel_size (List[int]):
The parallel size of each orthogonal parallel type. For example, if
tensor_parallel_size = 2, pipeline_model_parallel_group = 3, data_parallel_size = 4,
and the parallel mapping order is tp-pp-dp, then the parallel_size = [2, 3, 4].
mask (List[bool]):
The mask controls which parallel methods the generated groups represent. If mask[i] is
True, it means the generated group contains the i-th parallelism method. For example,
if parallel_size = [tp_size, pp_size, dp_size], and mask = [True, False , True], then
the generated group is the `tp-dp` group, if the mask = [False, True, False], then the
generated group is the `pp` group.
Algorithm:
For orthogonal parallelism, such as tp/dp/pp/cp, the global_rank and
local_rank satisfy the following equation:
global_rank = tp_rank + dp_rank * tp_size + pp_rank * tp_size * dp_size (1)
tp_rank \in [0, tp_size)
dp_rank \in [0, dp_size)
pp_rank \in [0, pp_size)
If we want to get the `dp_group` (tp_size * pp_size groups of dp_size ranks each.
For example, if the gpu size is 8 and order is 'tp-pp-dp', size is '2-2-2', and the
dp_group here is [[0, 4], [1, 5], [2, 6], [3, 7]].)
The tp_rank and pp_rank will be combined to form the `dp_group_index`.
dp_group_index = tp_rank + pp_rank * tp_size (2)
So, Given that tp_rank and pp_rank satisfy equation (2), and dp_rank in
range(0, dp_size), the ranks in dp_group[dp_group_index] satisfies the
equation (1).
This function solve this math problem.
For example, if the parallel_size = [tp_size, dp_size, pp_size] = [2, 3, 4],
and the mask = [False, True, False]. Then,
dp_group_index(0) = tp_rank(0) + pp_rank(0) * 2
dp_group_index(1) = tp_rank(1) + pp_rank(0) * 2
...
dp_group_index(7) = tp_rank(1) + pp_rank(3) * 2
dp_group[0] = 0 + range(0, 3) * 2 + 0 = [0, 2, 4]
dp_group[1] = 1 + range(0, 3) * 2 + 0 = [1, 3, 5]
...
dp_group[7] = 1 + range(0, 3) * 2 + 3 * 2 * 3 = [19, 21, 23]
"""
def prefix_product(a: List[int], init=1) -> List[int]:
r = [init]
for v in a:
init = init * v
r.append(init)
return r
def inner_product(a: List[int], b: List[int]) -> int:
return sum([x * y for x, y in zip(a, b)])
def decompose(index, shape, stride=None):
"""
This function solve the math problem below:
There is an equation:
index = sum(idx[i] * stride[i])
And given the value of index, stride.
Return the idx.
This function will be used to get the pp/dp/pp_rank
from group_index and rank_in_group.
"""
if stride is None:
stride = prefix_product(shape)
idx = [(index // d) % s for s, d in zip(shape, stride)]
# stride is a prefix_product result. And the value of stride[-1]
# is not used.
assert (
sum([x * y for x, y in zip(idx, stride[:-1])]) == index
), "idx {} with shape {} mismatch the return idx {}".format(index, shape, idx)
return idx
masked_shape = [s for s, m in zip(parallel_size, mask) if m]
unmasked_shape = [s for s, m in zip(parallel_size, mask) if not m]
global_stride = prefix_product(parallel_size)
masked_stride = [d for d, m in zip(global_stride, mask) if m]
unmasked_stride = [d for d, m in zip(global_stride, mask) if not m]
group_size = prefix_product(masked_shape)[-1]
num_of_group = world_size // group_size
ranks = []
for group_index in range(num_of_group):
# get indices from unmaksed for group_index.
decomposed_group_idx = decompose(group_index, unmasked_shape)
rank = []
for rank_in_group in range(group_size):
# get indices from masked for rank_in_group.
decomposed_rank_idx = decompose(rank_in_group, masked_shape)
rank.append(
inner_product(decomposed_rank_idx, masked_stride)
+ inner_product(decomposed_group_idx, unmasked_stride)
)
ranks.append(rank)
return ranksRankGenerator需要先获取到各个并行方法的并行度,此外还需要获得一个rank计数的顺序,这是一个字符串,如"tp-dp-pp",说明先计数tp再是dp再是pp,RankGenerator在初始化时还会进行一定程度的补全与解析。RankGenerator有两个函数一个是
get_mask,负责根据order和token返回mask。例如order是’tp-dp-pp’,token是’tp-dp’,那么就会返回[true, false, true]一个是
get_ranks,负责依据token返回对应的rank group。例如现在的order是’tp-pp-dp’,tp_size=2,pp_size=2,dp_size=2,现在global rank的计算公式为tp_rank+pp_rank*tp_size+dp_rank*tp_size*pp_size,现在token是’dp’,说明想要知道tp所属rank、pp所属rank相同,但是所属dp不同的rank的集合,即tp_rank+pp_rank*tp_size+rang(dp_rank)*tp_size*pp_size,rang(dp_rank)={0,1},也就是需要知道哪些rank需要进行dp间通信以共享对应相同模型参数的梯度计算结果等,在这个例子中我们得到的就是[[0,4],[1,5],[2,6],[3,7]],如下图所示,同颜色的就是同一个dp_group内的rank。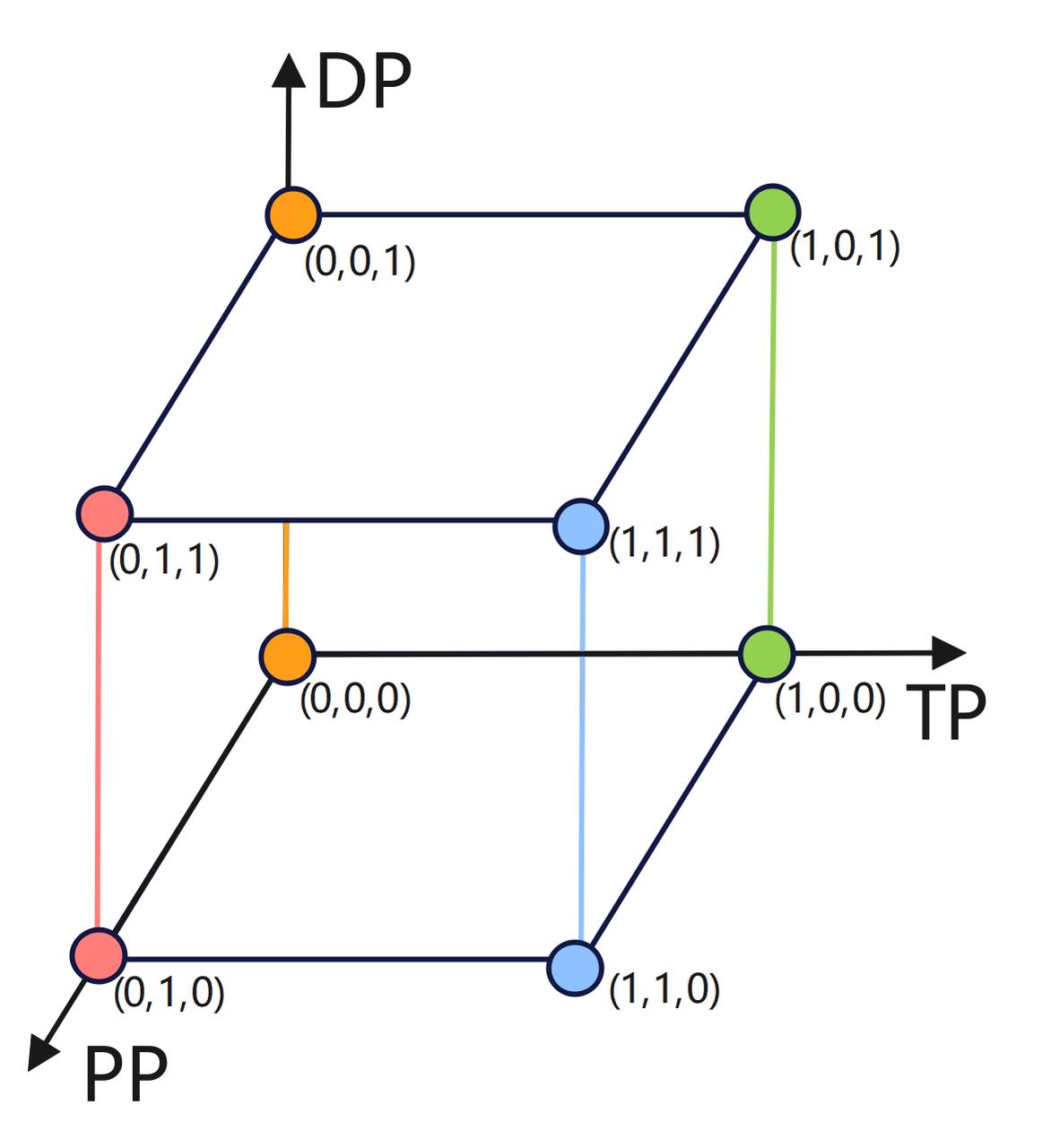
同理对于
get_ranks,如果现在的order是’tp-dp-pp’,tp_size=2,dp_size=3,pp_size=4,现在global rank的计算公式为tp_rank+dp_rank*tp_size+pp_rank*tp_size*dp_size,如果token依旧是’dp’,那么dp group的计算公式为tp_rank+rang(dp_rank)*tp_size+pp_rank*tp_size*dp_size,即[[0,2,4],[1,3,5]…[19,21,23]]
然后借助
RankGenerator,我们就可以创建各个通信组,其创建流程基本与如下代码类似,即得到不同并行策略的groups,然后遍历这些group,对每个group创建torch.distributed.new_group,然后查看如果本进程的rank在这个group里,那么就设置其相关全局变量为这个group。注意这里每次都创建了new_group,但是本进程接下来可能并不会保存它,这么做是为了在分布式执行中让所有worker都执行同样的new_group,以保证分布式通信的正确,防止死锁等问题。1
2
3
4
5for ranks in rank_generator.get_ranks('xxx'):
group = create_group(ranks, backend=..., pg_options=...)
if rank in ranks:
GLOBAL_GROUP = group
GLOBAL_RANKS = ranks非 Expert(Decoder / Attention)并行组对应关系
Expert(MoE)相关并行组对应关系:
Distributed Optimizer 相关组对应关系
setup_model_and_optimizer
setup_model_and_optimizer的代码如下:
1 | |
其整体流程如下:
通过get_model获取本worker上的模型
通过
unwrap_model来获取DDP包装下的原始模型通过
get_megatron_optimizer获取optimizer通过
get_optimizer_param_scheduler获取optimizer学习率参数调度器如有配置args.moe_use_upcycling,执行MoE upcycling,把 Dense FFN 模型转成 MoE 模型,然后从检查点中获取模型并保存,还会调整优化器
如果没有配置args.moe_use_upcycling并且配置了检查点,那么就从检查点中加载模型、优化器等
如果iteration = 0 时的特殊初始化(BERT),执行optimizer.reload_model_params()
如果配置了args.ckpt_convert_format,就加载旧格式的模型检查点,然后保存为新格式的模型检查点
最终return model, optimizer, opt_param_scheduler
get_model
get_model代码如下:
1 | |
其整体流程如下
构建了一个
build_model()函数,并使用其获得各个worker上应有的模型。其主要是负责根据当前是否是第一阶段、是否是最后一阶段以及当前的pp维度、vp维度构建在当前worker上的模型。例如当前layer数量是8,pp_size是4,vp_size是2,则4个worker获得的模型分别是[embedding+layer_0, layer_4], [layer_1, layer_5], [layer_2,layer_6], [layer_3,layer_7+lm head+loss]。给各个model的parameters设置tp的默认参数:
1 | |
如果没有使用fsdp2并且不使用cpu初始化并且没有
init_model_with_meta_device,那么就将模型搬运到GPU显存上如果配置了fp16、bf16,那么就对model进行低精度转换
然后如果启用了DDP就进行DDP包装:
首先定义DP,这里支持3类DDP包装,分别是torch_FSDP、megatron_FSDP和DDP
然后构造ddp_config:
如果使用的是fsdp2,就直接TorchFullyShardedDataParallelConfig作为ddp_config
不然就自行填写参数构造DistributedDataParallelConfig作为ddp_config
然后对于当前rank的各个model,使用DP对其进行包装
如果使用了data_parallel_random_init,还需要在ddp内进行broadcast_params以统一参数。
get_megatron_optimizer
get_megatron_optimizer代码如下:
1 | |
get_optimizer_param_scheduler
get_optimizer_param_scheduler负责给optimizer计算每一步使用什么学习率,代码如下:
1 | |
其有两类训练描述方式:
Iteration-based training,即设置了类似
--train-iters 500000因为Megatron 的
OptimizerParamScheduler内部是以已处理的 sample 数作为横轴,所以1 iteration = global_batch_size 个 samples然后其支持设置warm up步数、Warm Start Decay步数
Sample-based training,即设置了类似
--train-samples 300B首先其通过
update_train_iters(args)来反推train_iters,因为可能其他地方还需要使用iters然后可以直接得到lr_decay_steps = args.lr_decay_samples,wd_incr_steps = args.train_samples
最后借助这些参数构造
OptimizerParamScheduler
train
train的代码如下所示:
1 | |
其主要流程为:
获取全局配置
切换到 train() 模式
将迭代次数与rerun_state_machine对齐
给
config注入“分布式重叠通信/同步”钩子,config会被forward_backward_func/train_step使用,用于控制 no_sync(梯度累积)、梯度同步重叠、参数 all-gather 重叠 等。还有一些可选的配置,如控制gc、开启profiler等
进入主循环:
while iteration < args.train_iters:更新
microbatch,因为存在动态batch size的场景使用
train_step进行一轮训练按需保存checkpoint
第一轮成功后再启用 forward pre-hook
更新 iteration/样本数/FLOPs
按需进行评估
训练收尾,flush writer(TensorBoard/WandB/one-logger),若 pre-hook 还开着,关闭它(避免退出时还有挂钩或后台同步),最终 finalize 异步检查点等
train_step
参数forward_backward_func
train_step的关键参数还包含了forward_backward_func,其通过如下获得:
1 | |
get_forward_backward_func函数如下:
1 | |
其依据pipeline划分为了多个类别
forward_backward_pipelining_with_interleaving:开了pp和vpforward_backward_pipelining_without_interleaving:开了pp但是没有vpforward_backward_no_pipelining:没有开pp
先只看最简单的forward_backward_no_pipelining,代码如下所示:
1 | |
其流程如下:
如果没有设置
grad_finalize_pgs,就构造默认值,从而在做梯度规约/归并时,需要明确“在哪些通信域里做什么规约”,例如DP/DP×CP:参数梯度的 all-reduce 或 reduce-scatter做一些参数检查
然后分为MoE overlap 与普通路径:
MoE会调用
combined_1f1b_schedule_for_no_pipelining普通路径就是执行
num_microbatches次forward_step,如果不是forward_only就执行backward_step,注意后一个 micro-batch 在 no_sync 外,从而让“梯度同步/规约”在这一轮的尾部发生(典型的梯度累积实现方式)
最后执行
finalize_model_grads_func,这一步通常包含:DP 的全梯度 all-reduce / reduce-scatter(取决于 optimizer/ZeRO 类策略)
sequence parallel 的 LayerNorm 等规约
embedding/pos embedding 的特定规约
其中一个micro batch的forward_step代码如下所示,注意到这里就会调用到用户传入的forward_step_func函数了
1 | |
train_step代码&流程
train_step的代码如下,它是训练循环里真正执行一次参数更新(或跳过更新) 的函数。它把 “梯度清零 → 前后向(可能重跑)→ optimizer.step → LR scheduler.step → 统计/归约 loss” 串起来,并与 容错重跑机制、分布式优化器/通信重叠、视觉预训练特殊逻辑交织在一起。
1 | |
其流程如下:
其计算Forward的代码外包了一层
while rerun_state_machine.should_run_forward_backward(data_iterator),这是为了当检测到某些 transient 错误或需要重新取 batch 时可以进行容错与重跑。具体Forward如下清空model和optimizer的grad
一些特殊逻辑,包含形状调整函数(仅 ModelOpt 蒸馏 + PP)和mxfp8 参数复用 grad buffer 时的参数 buffer 拷贝
调用
forward_backward_func执行一次forward并拿到loss
统一判断是否要 checkpoint或exit
清空cuda cache,判断是否要走视觉预训练的特殊逻辑
调用
optimizer.step()更新模型参数进一步调整opt_param_scheduler的学习率
如果当前是 pipeline last stage 则汇总 microbatches 的 loss,主要是用于日志数据记录等
evaluate_and_print_results
evaluate_and_print_results的代码如下:
1 | |
其流程如下:
进行TensorBoard 与 WandB的初始化
如果是多验证集,就获取对应的
eval_iters列表如果设置了
full_validation,就把验证集发给所有rank对每个验证集调用 evaluate(…)
打印对应的日志,写入到WandB
调用
process_non_loss_data_func进行自定义的非 loss 数据的处理
evaluate
evaluate的代码如下:
1 | |
其整体流程如下所示:
切换模型到 eval(),并临时禁用
rerun_state_machine计算evaluate用的 microbatch 大小
与train类似,得到
forward_backward_func在no_grad下依次执行各个eval_iter:
调用
forward_backward_func,注意调用时专门设置了forward_only=True在 pipeline last stage 收集与规约 loss
通过评估样本计数与 time limit 计算是否需要提前退出
执行
non_loss_data_func与forward_backward_func
将model恢复训练模式,并把累计的 numerator/denominator 转成标量
恢复
rerun_state_machine、返回结果