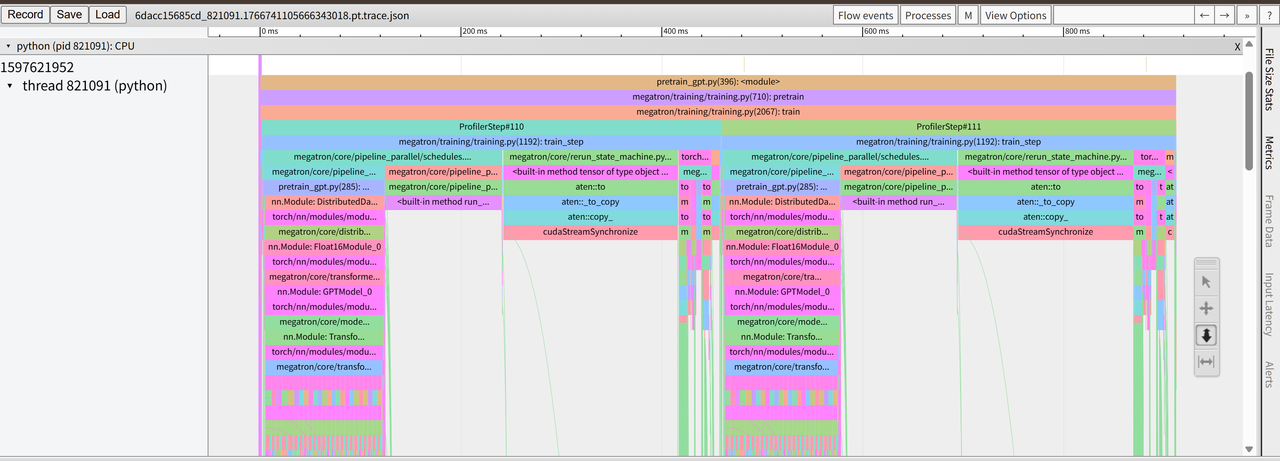
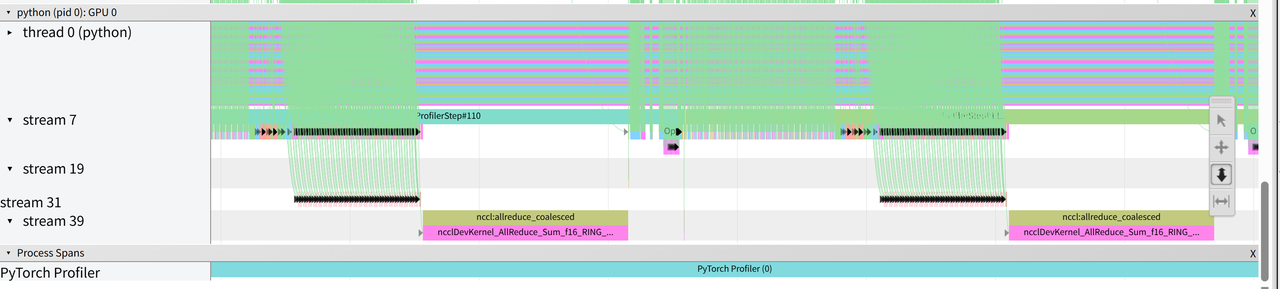
with torch.profiler.profile( activities=[ torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA, ], schedule=torch.profiler.schedule( wait=1, warmup=1, active=2, repeat=1, ), on_trace_ready=torch.profiler.tensorboard_trace_handler( logdir ), record_shapes=True, with_stack=True, ) as prof: for step inrange(6): x = torch.randn(4096, 4096, device="cuda") y = x @ x torch.cuda.synchronize() prof.step()
group.add_argument('--profile', action='store_true', help='Enable nsys profiling. When using this option, nsys ' 'options should be specified in commandline. An example ' 'nsys commandline is `nsys profile -s none -t nvtx,cuda ' '-o <path/to/output_file> --force-overwrite true ' '--capture-range=cudaProfilerApi ' '--capture-range-end=stop`.') group.add_argument('--profile-step-start', type=int, default=10, help='Global step to start profiling.') group.add_argument('--profile-step-end', type=int, default=12, help='Global step to stop profiling.') group.add_argument('--use-pytorch-profiler', action='store_true', help='Use the built-in pytorch profiler. ' 'Useful if you wish to view profiles in tensorboard.', dest='use_pytorch_profiler')
if ( args.profile and torch.distributed.get_rank() in args.profile_ranks and args.use_pytorch_profiler ): prof = torch.profiler.profile( schedule=torch.profiler.schedule( wait=max(args.profile_step_start - 1, 0), warmup=1 if args.profile_step_start > 0 else 0, active=args.profile_step_end - args.profile_step_start, repeat=1, ), on_trace_ready=torch.profiler.tensorboard_trace_handler(args.tensorboard_dir), record_shapes=True, with_stack=True, ) prof.start()
# ...
# Run training iterations till done. while iteration < args.train_iters: if args.profile and torch.distributed.get_rank() in args.profile_ranks: if args.use_pytorch_profiler: prof.step() elif iteration == args.profile_step_start: torch.cuda.cudart().cudaProfilerStart() torch.autograd.profiler.emit_nvtx(record_shapes=True).__enter__()
# Profiling. if ( args.profile and iteration == args.profile_step_end and torch.distributed.get_rank() in args.profile_ranks ): if args.use_pytorch_profiler: assert prof is not None prof.stop() else: torch.cuda.cudart().cudaProfilerStop()
CHECKPOINT_PATH=$1#<Specify path> TENSORBOARD_LOGS_PATH=$2#<Specify path> VOCAB_FILE=$3#<Specify path to file>/gpt2-vocab.json MERGE_FILE=$4#<Specify path to file>/gpt2-merges.txt DATA_PATH=$5#<Specify path and file prefix>_text_document USE_NSYS=0 if [[ ${6:-} == "--nsys" ]]; then USE_NSYS=1 fi
# Run training iterations till done. while iteration < args.train_iters: if args.profile and torch.distributed.get_rank() in args.profile_ranks: if args.use_pytorch_profiler: prof.step() elif iteration == args.profile_step_start: torch.cuda.cudart().cudaProfilerStart() torch.autograd.profiler.emit_nvtx(record_shapes=True).__enter__()
然后当步数达到args.profile_step_end步数时才关闭profile
1 2 3 4 5 6 7 8 9 10 11
# Profiling. if ( args.profile and iteration == args.profile_step_end and torch.distributed.get_rank() in args.profile_ranks ): if args.use_pytorch_profiler: assert prof is not None prof.stop() else: torch.cuda.cudart().cudaProfilerStop()
CHECKPOINT_PATH=$1#<Specify path> TENSORBOARD_LOGS_PATH=$2#<Specify path> VOCAB_FILE=$3#<Specify path to file>/gpt2-vocab.json MERGE_FILE=$4#<Specify path to file>/gpt2-merges.txt DATA_PATH=$5#<Specify path and file prefix>_text_document USE_NSYS=0 if [[ ${6:-} == "--nsys" ]]; then USE_NSYS=1 fi
group.add_argument('--record-memory-history', action="store_true", default=False, help='Record memory history in last rank.') group.add_argument('--memory-snapshot-path', type=str, default="snapshot.pickle", help='Specifies where to dump the memory history pickle.')
if args.record_memory_history: torch.cuda.memory._record_memory_history( True, # keep 100,000 alloc/free events from before the snapshot trace_alloc_max_entries=100000, # record stack information for the trace events trace_alloc_record_context=True, )
defoom_observer(device, alloc, device_alloc, device_free): # snapshot right after an OOM happened print('saving allocated state during OOM') snapshot = torch.cuda.memory._snapshot() from pickle import dump
if iteration % args.log_interval == 0: if args.record_memory_history and is_last_rank(): snapshot = torch.cuda.memory._snapshot() from pickle import dump
with open(args.memory_snapshot_path, 'wb') as f: dump(snapshot, f)
CHECKPOINT_PATH=$1#<Specify path> TENSORBOARD_LOGS_PATH=$2#<Specify path> VOCAB_FILE=$3#<Specify path to file>/gpt2-vocab.json MERGE_FILE=$4#<Specify path to file>/gpt2-merges.txt DATA_PATH=$5#<Specify path and file prefix>_text_document USE_NSYS=0 if [[ ${6:-} == "--nsys" ]]; then USE_NSYS=1 fi