【论文阅读】ByteScale:Efficient Scaling of LLM Training with a 2048K Context Length on More Than 12,000
团队:ByteDance
背景
为了提升大语言模型的长上下文能力,长文本的训练是有必要的,经过通过Flash Attention技术可以将Attention相关计算的显存占用降低为O(S),但是计算量依旧为O(S^2),这会极大的消耗显存和算力。
为了降低显存开销,传统的方法是使用静态的数据并行叠加上下文并行,即固定数据并行和上下文并行的维度,在一个数据并行内将文本均匀地切割给各个上下文并行组的worker,在Attention计算时通过P2P通信来将各个worker的K、V进行传递。
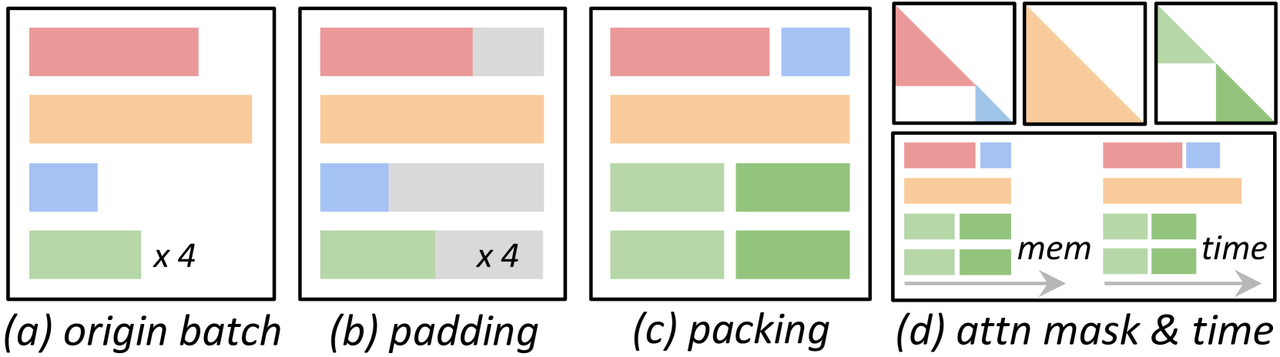
此外由于训练数据集中的序列长度往往不同,除了padding填充外,一个常见的做法是对序列进行打包,即将较短的多个序列合并为一个不超过长度限制的长序列,如下图所示。
- 训练数据集分析如下图所示,大部分序列都是短序列,但是长序列虽然数量不多但是占据了总Token的很大一比例。

在这种静态上下文并行的处理下,打包带来了一系列问题:
通信冗余:这些短序列需要经历和长序列一样的上下文切分和通信,但实际上它们因为足够短所以其实不需要如此;并且这还要求短序列对于O(S^2)的计算与O(S)的通信重叠。
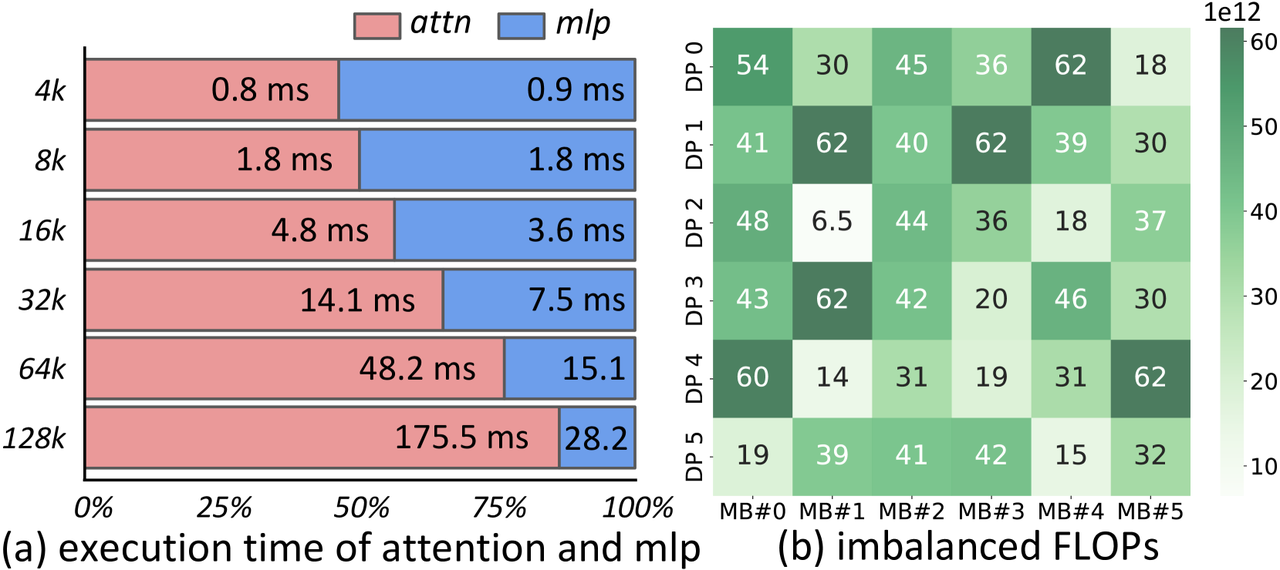
计算不平衡:尽管Token被均匀地分发给了各个worker,内存保持了平衡,但是就计算而言,其计算复杂度与原始序列的长度有关,对于都是短的原始序列,在O(S^2)的计算复杂度下,其计算时间也更短。下图显示了不同长度下的计算时间和FLOPs分布。
- 如下图所示,DP1内的序列本可以直接在一个GPU内直接完成,但是因为打包的原因的现在需要跨GPU直接做序列并行的冗余通信了。并且由于DP1的序列都更短,所以其计算也更快,但是在DP训练中,需要等待各个DP都计算完再进行梯度同步,这就导致了如下图(c)所示就出现了DP并行训练中的bubble。
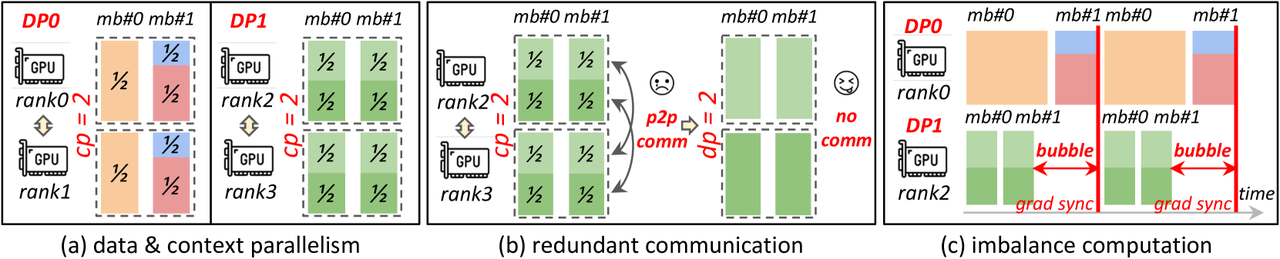
- 此外如下图所示在PP与DP并行混合中也会因为计算不平衡出现bubble。
为了解决上述的问题,其提出了ByteScale,专为大规模长短序列混合训练而设计。主要贡献有:
提出了一种混合数据并行方案(HDP)来统一DP和CP,利用[1,DP*CP]范围内的worker灵活处理可变长序列
提出了一种通信优化方法,为了减少短序列的冗余通信提供了一种数据感知的分片能力,让每个序列由最少的设备进行处理。并且还提供了选择性卸载功能以进一步压缩长序列的通信成本。
提出了一种平衡策略,为了缓解计算不平衡,其设计了一种启发式算法,根据数据和流水线并行性的特点重新组织数据分配。此外,对于那些执行时间较短的设备,分配更多的微批次,而不是在静态系统设计下分配相同的数量。
在具有超过12,000个GPU的生产集群上进行实验,将模型大小从7B扩展到141B,上下文长度从256K扩展到2048K。结果显示其训练速度是现有的训练方法的7.89倍。

方法思路
系统概览
ByteScale整体概览如下图所示:

Profiler目的是分析环境、模型配置、数据分布,并为其他组件构建成本模型。
Communication Optimizer旨在通过数据感知分片、动态通信和选择性卸载来提高短序列和长序列的通信效率。
Balance Scheduler旨在通过并行感知的数据分配来解决计算不平衡问题。
Communication Optimizer
数据感知分片与通信
HDP取代了DP和CP,d_HDP=d_DP*d_CP,HDP不同于DP与CP,它允许HDP节点之间存在异构行为:
- 更灵活的通信:HDP仅要求不同的HDP rank处理相同数量的token,HDP内的worker可以直接处理一个完整的短序列,如下图(d)所示

- 更细粒度的通信:HDP的并行度并不需要完全固定,其可以使用[1,d_HDP]范围内的任意并行度,例如当d_HDP=d_DP*d_CP时,可以使用96个进程处理768K序列,而剩余32个进程各自单独处理32个8K长度的序列。
NCCL缓冲区优化:创建过多的HDP通信组会占用GPU显存,而因为上下文并行中使用的是P2P通信,所以这里直接复用一个全局的HDP进程组来进行通信
优化器状态分片:与DP类似,一个HDP内是完整的一个模型,所以可以服用Zero优化技术,实践中使用了Zero-1技术来分片优化器状态,如上图(a)所示
数据感知选择性卸载
为了使用尽可能少的设备处理训练序列,显存是一大问题,因为激活的大小与序列长度成正比。
故为了更好地支持长序列训练,需要将部分激活卸载到CPU内存上。正好以下两个特性也支持了这一实现
激活值是FILO模型:激活值随着前先传播而从前向后累积,而后在反向传播中从后先前逐渐使用完毕。所以可以将前面的激活先卸载到CPU中。
O(S^2)计算可与O(S)显存卸载重叠:由于GPU与CPU间的PCIe带宽有限,所以卸载时间往往很慢,难以重叠,但是在足够长的序列中,因为O(S^2)计算复杂度导致了卸载时间可以被计算重叠,并且因为是其是主机内CPU与GPU间的卸载,所以也不会额外占用显存。
选择性卸载:只有长序列才能让卸载与计算重叠,所以需要选择性地选择长序列进行卸载。这里提出了一些选择的方法。
Balance Scheduler
微批次重定义
一般的梯度累积要求每个micro batch相同,但是因为每个序列的计算消耗不同,所以这会导致各个micro batch处理的时间不平衡。
故在HDP在保持global batch相同的前提先允许每个micro batch不同,如下图(a)所示

PP平衡
如上图(b)所示,如果各个HDP中的PP并行下的执行时间不同,会导致最后做梯度同步前出现一段bubble,完成快的等待完成慢的。
为了减少这段bubble提高计算效率,其为执行时间较短的流水线分配更多微批次以使得最终执行时间基本相同。如下图所示。

DP平衡
- 如果没有PP并行,那么为了DP并行中各个DP组的完成时间对齐,一个简单的方法就是直接使得在一轮batch中各个DP均使用相同长度的序列。
综合平衡策略
首选对global batch中的序列按长度降序排列,然后划分为若干桶,每个桶的浮点运算次数总和大致相同
然后依据是DP平衡策略还是PP平衡策略来给micro batch选择序列以使得符合前述的平衡策略,如下所示

实验效果
实验在超过12000个GPU的大型生产级GPU集群上进行
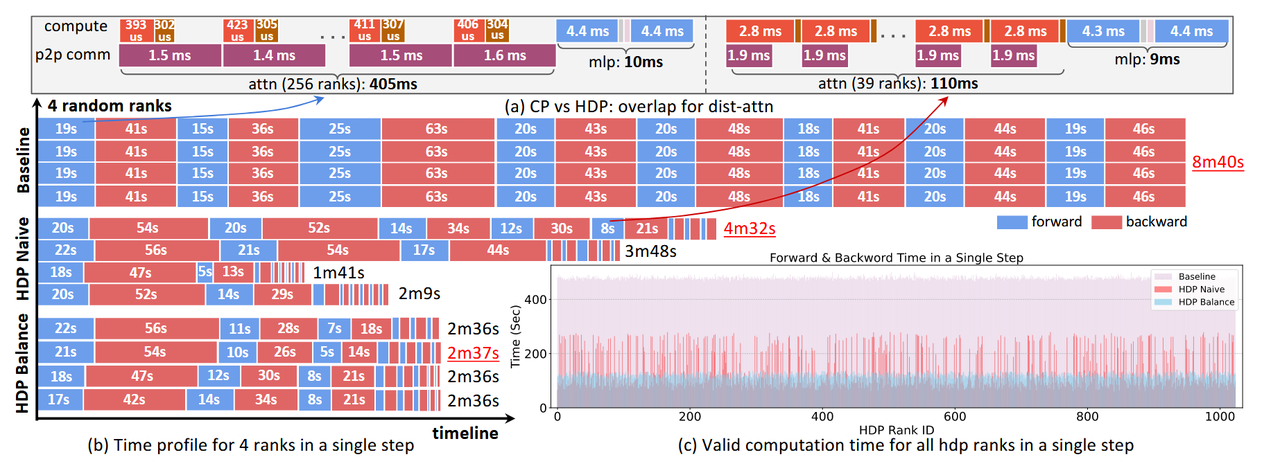
端到端测试结果如下:

- 也经过case studies进行了进一步分析
总结
前面分析的引言写的很好,层层入扣,也很方便阅读
混合上下文并行下的问题找的很经典,解决方案最终也围绕在解决通信冗余与计算不平衡方面的问题,解决方法很朴实但有效
个人觉得这之中的系统实现肯定也是一个大难点