【Megatron-LM源码分析(五)】-Tensor并行
理论基础
基础的理论分析可以见之前写的内容:https://slipegg.github.io/2025/06/07/Picotron-Tutorial%20Tensor%20Parallel/,https://slipegg.github.io/2025/12/07/Megatron-LM-paper-note/
简单来说就是存在行并行与列并行两种Tensor并行方式。
上述的前向传播好理解,但是反向传播会稍微复杂一些,这里可以直接访问ChatGPT查看其介绍,介绍的还是很详细的:https://chatgpt.com/share/6953c681-7cd0-8011-8dfe-1d2281834b08
结论就是在列并行中求 $\frac{\partial L}{\partial X}$时需要All Reduce(Sum)操作,而求$\frac{\partial L}{\partial W}$不需要,在行并行中求偏导的时候都不需要额外通信操作。
由于在MLP层我们采取的是先列并行再行并行的形式,从而减少前向传播过程中的通信量,故在反向传播过程中在反向传播到列并行时也需要进行一次All Reduce(Sum)操作。
训练数据获取
在pretrain_gpt.py文件中的get_batch函数可以看到有专门的tp数据处理,如下:
1 | |
进一步的,查看get_batch_on_this_tp_rank函数如下所示,tp rank为0的worker会从data loader中获取一份micro_batch的数据,然后组成batch格式,将其broadcast到tp组的其他worker中。
1 | |
上述可以看到其主要broadcast了tokens、labels、loss_mask、attention_mask、position_ids这五分数据,如下图的torch profiler所示,也确实发生了5次的broadcast。

Tensor并行相关代码
模型构建
model构建的入口函数在pretrain_gpt.py的model_provider函数中,其默认执行路线如下所示(去除了一些不必要的分支)
1 | |
对于_get_transformer_layer_spec函数,其实现如下:
1 | |
默认参数中use_te为True,即使用了具有算子融合等优化的transformer_engine,故走到了get_gpt_layer_with_transformer_engine_spec分支,而不是Megatron-LM本地的get_gpt_layer_local_spec分支,get_gpt_layer_with_transformer_engine_spec如下:
1 | |
注意上述的use_kitchen很重要,而默认情况下其为False,故backend = TESpecProvider(),即使用的是transformer_engine来生成TransformerLayer,而不是用 NVIDIA Kitchen作为后端来提供(部分)Transformer 子模块的实现/spec。而Megatron-LM还进一步对transformer_engine的相关模块进行了简单封装以使其可以支持Tensor并行等功能。
Megatron-LM本地实现gpt_layer
由于transformer_engine是专有封装过于复杂,所以我们转而去查看Megatron-LM的本地实现,get_gpt_layer_with_transformer_engine_spec如下所示,我们查看的backend为LocalSpecProvider:
1 | |
其使用的是
TransformerLayer来组装,初始化代码如下所示,初始化的模块依次为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174def __init__(
self,
config: TransformerConfig,
submodules: TransformerLayerSubmodules,
layer_number: int = 1,
hidden_dropout: Optional[float] = None,
model_comm_pgs: Optional[ModelCommProcessGroups] = None,
vp_stage: Optional[int] = None,
):
super().__init__(config=config)
# Enable cuda graphs.
if (
config.enable_cuda_graph and config.cuda_graph_scope != "full_iteration"
) or config.external_cuda_graph:
assert not (
config.enable_cuda_graph and config.external_cuda_graph
), "Cudagraphs and external cudagraphs cannot be enabled at the same time"
if config.enable_cuda_graph and config.cuda_graph_scope != "full_iteration":
if not self.training:
# Cudagraphs for inference are only enabled with the flash decoding kernel
assert (
self.config.flash_decode
), "--flash-decode is required to use CUDA graphs during inference"
self.cudagraph_manager = CudaGraphManager(config, vp_stage=vp_stage)
else:
# List to store CUDA graphs. A list of `N` CUDA graphs for this layer where N is
# the number of microbatches. Multiple CUDA graphs per layer is required to support
# pipelining which requires running FWD graph of multiple microbatches before BWD
# graph. To enable CUDA graph, this list should be populated in the model training
# script with the graphs returned by make_graphed_callables API before the first
# training step.
self.cuda_graphs = []
# List to store forward pre-hooks. Forward pre-hooks are not captured into CUDA
# graphs. Those hooks and args are collected in this list and should be manually
# triggered before CUDA Graph running. This is required to ensure the correct param
# all-gather overlap with forward compute.
self.cuda_graph_manual_hooks = []
self.current_microbatch = -1
if model_comm_pgs is None:
model_comm_pgs = ModelCommProcessGroups.use_mpu_process_groups()
self.submodules_config = submodules
self.layer_number = layer_number + get_transformer_layer_offset(self.config, vp_stage)
self.hidden_dropout = config.hidden_dropout if hidden_dropout is None else hidden_dropout
# [Module 1: Input Layernorm] Optional Layernorm on the input data
# TODO: add pytorch only layernorm
self.input_layernorm = build_module(
submodules.input_layernorm,
config=self.config,
hidden_size=self.config.hidden_size,
eps=self.config.layernorm_epsilon,
)
attention_optional_kwargs = {}
if config.context_parallel_size > 1 and config.cp_comm_type is not None:
if isinstance(config.cp_comm_type, list):
attention_optional_kwargs["cp_comm_type"] = config.cp_comm_type[self.layer_number]
else:
attention_optional_kwargs["cp_comm_type"] = config.cp_comm_type
attention_optional_kwargs["model_comm_pgs"] = model_comm_pgs
# [Module 2: SelfAttention]
self.self_attention = build_module(
submodules.self_attention,
config=self.config,
layer_number=self.layer_number,
**attention_optional_kwargs,
)
# [Module 3: BiasDropoutFusion]
self.self_attn_bda = build_module(submodules.self_attn_bda)
# [Module 4: Post SelfAttention] Optional Layernorm after self-attn
self.pre_cross_attn_layernorm = build_module(
submodules.pre_cross_attn_layernorm,
config=self.config,
hidden_size=self.config.hidden_size,
eps=self.config.layernorm_epsilon,
)
# [Module 5: CrossAttention]
self.cross_attention = build_module(
submodules.cross_attention,
config=self.config,
layer_number=self.layer_number,
**attention_optional_kwargs,
)
# [Module 6: BiasDropoutFusion]
self.cross_attn_bda = build_module(submodules.cross_attn_bda, config=self.config)
# [Module 7: Pre MLP] Optional Layernorm before MLP
self.pre_mlp_layernorm = build_module(
submodules.pre_mlp_layernorm,
config=self.config,
hidden_size=self.config.hidden_size,
eps=self.config.layernorm_epsilon,
)
# [Module 8: MLP block]
additional_mlp_kwargs = {}
# import here to avoid circular import
from megatron.core.extensions.transformer_engine import TEFusedMLP
from megatron.core.transformer.moe.experts import GroupedMLP, SequentialMLP, TEGroupedMLP
from megatron.core.transformer.moe.moe_layer import MoELayer
# MLP expects tp_group but MoELayer expects model_comm_pgs to be passed in.
# We can change MLP to accept model_comm_pgs but it makes the logic implicit
# The conditional below is to make the logic explicit
# if submodules.mlp is not a ModuleSpec,we dont have to handle passing additional kwargs
if isinstance(submodules.mlp, ModuleSpec):
if submodules.mlp.module in (MoELayer, GroupedMLP, TEGroupedMLP, SequentialMLP):
additional_mlp_kwargs["model_comm_pgs"] = model_comm_pgs
elif submodules.mlp.module == MLP:
assert hasattr(
model_comm_pgs, 'tp'
), 'TP process group is required for MLP in TransformerLayer'
additional_mlp_kwargs["tp_group"] = model_comm_pgs.tp
elif TEFusedMLP is not None and submodules.mlp.module == TEFusedMLP:
assert hasattr(
model_comm_pgs, 'tp'
), 'TP process group is required for TEFusedMLP in TransformerLayer'
additional_mlp_kwargs["tp_group"] = model_comm_pgs.tp
else:
log_single_rank(
logger,
logging.WARNING,
f"Unknown MLP type: {type(submodules.mlp)}. Using default kwargs.",
)
self.mlp = build_module(submodules.mlp, config=self.config, **additional_mlp_kwargs)
if hasattr(self.mlp, 'set_layer_number'):
self.mlp.set_layer_number(self.layer_number)
# [Module 9: BiasDropoutFusion]
self.mlp_bda = build_module(submodules.mlp_bda)
self.recompute_input_layernorm = False
self.recompute_pre_mlp_layernorm = False
self.recompute_mlp = False
if self.config.recompute_granularity == 'selective':
if "layernorm" in self.config.recompute_modules:
if (
not isinstance(self.input_layernorm, IdentityOp)
and not self.config.external_cuda_graph
):
self.recompute_input_layernorm = True
if self.config.fp8:
self.self_attention.set_for_recompute_input_layernorm()
if not isinstance(self.pre_mlp_layernorm, IdentityOp):
self.recompute_pre_mlp_layernorm = True
if self.config.fp8:
if isinstance(self.mlp, MoELayer):
self.mlp.set_for_recompute_pre_mlp_layernorm()
else:
from megatron.core.extensions.transformer_engine import (
set_save_original_input,
)
set_save_original_input(self.mlp.linear_fc1)
if "mlp" in self.config.recompute_modules:
if not isinstance(self.mlp, MoELayer):
self.recompute_mlp = True
# @jcasper how should we handle nvfuser?
# Set bias+dropout+add fusion grad_enable execution handler.
# TORCH_MAJOR = int(torch.__version__.split('.')[0])
# TORCH_MINOR = int(torch.__version__.split('.')[1])
# use_nvfuser = TORCH_MAJOR > 1 or (TORCH_MAJOR == 1 and TORCH_MINOR >= 10)
# self.bias_dropout_add_exec_handler = nullcontext if use_nvfuser else torch.enable_grad
self.bias_dropout_add_exec_handler = torch.enable_gradInput Layernorm
SelfAttention
BiasDropoutFusion
Post SelfAttention
CrossAttention
BiasDropoutFusion
Pre MLP
MLP block
BiasDropoutFusion
其前向传播也是一些比较标准的实现,代码如下所示
1 | |
MLP模块
MLP模块中往往是先进行一次全连接计算,在使用类似gelu的激活函数,再使用一次全连接计算,在TP并行中往往采用的是对前一次采用列并行对后一次采用行并行的方式。
本地模块获取MLP的相关代码如下:
1 | |
一般情况下两个linear层分别为column_parallel_linear与row_parallel_linear,然后以此为基础构建了MLP模块,MLP模块的相关代码如下所示:
1 | |
在初始化时:
其读取配置得到了
ffn_hidden_size以及tp_group等参数然后构建了
column_parallel_linear类型的fc1以及row_parallel_linear类型的fc2,还要按配置所需的activation_func
在Forward时:
其整个流程为了方便Nsys分析使用
nvtx_range_push进行了准确的划分先调用
linear_fc1,再调用activation计算,再调用linear_fc2计算
column_parallel_linear
Megatron-LM本地写的ColumnParallelLinear如下所示:
1 | |
在初始化时:
其首先计算出在TP列并行下
self.output_size_per_partition = divide(output_size, world_size),并以此为基础初始化权重self.weight = Parameter(torch.empty(self.output_size_per_partition, self.input_size, ...))此外还标记了计算梯度时是否需要
allreduce_dgrad,需要的条件是world_size > 1 and not self.sequence_parallel and not self.disable_grad_reduce,因为sequence_parallel与梯度并行有冲突。
在Forward时,流程如下:
首先如果没有
weight参数就使用自身初始化的weight,然后检查形状。对于列并行而言,典型的实现是输入在所有 TP ranks 上一致(复制一份),每个 rank 用自己的
W_i计算Y_i = X @ W_i^T。copy_to_tensor_model_parallel_region在 TP>1 时会涉及通信/广播式的“让 input 在 TP ranks 上一致”,但如果启用了某些模式(sequence_parallel / allreduce_dgrad / expert 显式通信 / disable_grad_reduce),这里会选择不走 copy 路径(因为这些模式下输入已经按其它语义准备好了,或者通信由别处负责),直接使用传入的input_然后其调用了
_forward_impl计算结果,这里进行了多层包装,主要是为了应对sequence_parallel的情况,因为如果sequence_parallel为True,那么其会使用All gather获取input完整序列再做Gemm。注意其这里也定义了在 backward 中:
如果 ctx.allreduce_dgrad=True:会 torch.distributed.all_reduce(grad_input, async_op=True)
这是 TP 下典型的 dgrad 通信重叠。如果 ctx.sequence_parallel=True:会
reduce_scatter把 grad_input 分发回 sequence-parallel 格式。
然后其还需要根据
runtime_gather_output参数来判断是否需要执行All Gather来复原所有结果。注意在上述的MLP Forward计算时并没有配置runtime_gather_output,所以没有执行All Gather,这也符合TP并行的需要最后返回
output,output_bias
注意这里并没有直接定义backward的行为,但是正如我们前面所分析的,列并行在反向传播时求 $$\frac{\partial L}{\partial X}$$时需要All Reduce(Sum)操作,这部分backward的行为是Pytorch自动生成的
row_parallel_linear
row_parallel_linear代码如下所示:
1 | |
在初始化时:
参数设置整体与
row_parallel_linear类似,不同点在于其包含参数input_is_parallel记录输出是否已经被并行切分,并且存在约束如果设置了self.sequence_parallel,那么self.input_is_parallel必须为True。其切分权重时也是对输入维度进行切分(input_size_per_partition = input_size / tp_world_size)
在Forward时,流程如下:
其计查看参数
input_is_parallel,如果没有切分就调用scatter在TP组内进行划分然后其调用
_forward_impl来实现具体计算,与ColumnParallelLinear计算类似,如果使用了sequence_parallel会先All Gather获取对应输入数据然后对局部输出做对应通信得到
output:普通情况(非 expert、非 sequence_parallel):
调用reduce_from_tensor_model_parallel_region
=> 本质是 **TP all-reduce(sum)**,把各 rank 的Y_i求和得到完整Y(每个 rank 都得到同样的Y)。sequence_parallel=True:
调用reduce_scatter_to_sequence_parallel_region
=> 把 sum 的结果直接按 sequence parallel 需要的布局做 reduce-scatter,避免先 all-reduce 再切分的额外开销。expert 显式通信(MoE): 不在这里做 reduce,直接返回本地 output_parallel,因为 MoE 的 token dispatcher 负责跨 rank 的聚合/路由。
最后返回
output,output_bias
Transformer模块
在具体实现Transformer模块时,其会依赖multi_latent_attention参数来判断GPT 的每一层 self-attention 子模块用标准SelfAttention还是用MLA(Multi‑Latent Attention)变体。
我们这里直接看最标准的实现,代码如下:
1 | |
其初始化的时候初始化了下面几个模块:
Input Layernorm:对输入数据进行可选的层归一化
SelfAttention
BiasDropoutFusion
Post SelfAttention:自注意力后的可选层归一化
CrossAttention
BiasDropoutFusion
Pre MLP:MLP 前的可选层归一化
MLP block
BiasDropoutFusion
我们下面再看一下SelfAttention模块是如何设计的,尤其关注其与TP并行相关的内容
SelfAttention
SelfAttention的相关代码如下所示
1 | |
在初始化时:
尤其它是拓展了
Attention类,所以其首先对Attention进行了初始化,Attention的初始化代码如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98class Attention(MegatronModule, ABC):
"""Attention layer abstract class.
This layer only contains common modules required for the "self attn" and
"cross attn" specializations.
"""
def __init__(
self,
config: TransformerConfig,
submodules: Union[SelfAttentionSubmodules, CrossAttentionSubmodules],
layer_number: int,
attn_mask_type: AttnMaskType,
attention_type: str,
cp_comm_type: str = None,
model_comm_pgs: ModelCommProcessGroups = None,
):
super().__init__(config=config)
self.config = config
self.layer_number = layer_number
self.attn_mask_type = attn_mask_type
self.attention_type = attention_type
# For normal attention without groups, num_query_groups == num_attention_heads,
# so these two will be the same
self.query_projection_size = self.config.kv_channels * self.config.num_attention_heads
self.kv_projection_size = self.config.kv_channels * self.config.num_query_groups
if model_comm_pgs is None:
model_comm_pgs = ModelCommProcessGroups.use_mpu_process_groups(
required_pgs=['tp', 'cp']
)
else:
assert hasattr(
model_comm_pgs, 'tp'
), "Attention model_comm_pgs must have tp process group"
assert hasattr(
model_comm_pgs, 'cp'
), "Attention model_comm_pgs must have cp process group"
self.model_comm_pgs = model_comm_pgs
# Per attention head and per partition values
world_size = get_pg_size(self.model_comm_pgs.tp)
self.hidden_size_per_attention_head = divide(
self.query_projection_size, self.config.num_attention_heads
)
self.num_attention_heads_per_partition = divide(self.config.num_attention_heads, world_size)
self.num_query_groups_per_partition = divide(self.config.num_query_groups, world_size)
# To support both CUDA Graphs and key value with different hidden size
self.key_hidden_size = self.hidden_size_per_attention_head
self.val_hidden_size = self.hidden_size_per_attention_head
self.core_attention = build_module(
submodules.core_attention,
config=self.config,
layer_number=self.layer_number,
attn_mask_type=self.attn_mask_type,
attention_type=self.attention_type,
cp_comm_type=cp_comm_type,
softmax_scale=self.config.softmax_scale,
model_comm_pgs=self.model_comm_pgs,
)
self.checkpoint_core_attention = (
self.config.recompute_granularity == 'selective'
and "core_attn" in self.config.recompute_modules
)
# Output.
self.linear_proj = build_module(
submodules.linear_proj,
self.query_projection_size,
self.config.hidden_size,
config=self.config,
init_method=self.config.output_layer_init_method,
bias=self.config.add_bias_linear,
input_is_parallel=True,
skip_bias_add=True,
is_expert=False,
tp_comm_buffer_name='proj',
tp_group=self.model_comm_pgs.tp,
)
if (
HAVE_TE
and self.config.fp8
and self.config.fp8_recipe != 'delayed'
and is_te_min_version("2.6.0dev0")
and isinstance(self.linear_proj, TELinear)
):
# For fp8 training, the output of the fused core_attn is saved by itself, and
# linear_proj also saves the quantized tensor of this output. Here we set the
# linear_proj to save the original input tensors to avoid the extra memory usage of
# the quantized tensor.
set_save_original_input(self.linear_proj)在计算q、k、v的输出维度时,其单独计算了q的维度(
self.query_projection_size = self.config.kv_channels * self.config.num_attention_heads),再计算了k与v的维度(self.kv_projection_size = self.config.kv_channels * self.config.num_query_groups),因为在类似在GQA/MQA中self.config.num_attention_heads与self.config.num_query_groups可能不同然后基于TP并行度切分了q所对应的
self.config.num_attention_heads个数,还切分了kv所对应的self.config.num_query_groups,注意这里如果不能整除的话会直接报错,所以运行起来的必然是每个TP rank都有均匀切分的q、k、v然后其构建了core attention,在本地模式中使用的是
DotProductAttention,代码如下所示,其主要是在Forward时负责依据传入的q、k、v、attention_mask等计算attention结果,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198class DotProductAttention(MegatronModule):
"""
Region where selective activation recomputation is applied.
This region is memory intensive but less compute intensive which
makes activation checkpointing more efficient for LLMs (20B+).
See Reducing Activation Recomputation in Large Transformer Models:
https://arxiv.org/abs/2205.05198 for more details.
We use the following notation:
h: hidden size
n: number of attention heads
p: number of tensor model parallel partitions
b: batch size
s: sequence length
"""
def __init__(
self,
config: TransformerConfig,
layer_number: int,
attn_mask_type: AttnMaskType,
attention_type: str,
attention_dropout: float = None,
softmax_scale: float = None,
cp_comm_type: str = None,
model_comm_pgs: ModelCommProcessGroups = None,
):
super().__init__(config=config)
self.config: TransformerConfig = config
assert (
self.config.context_parallel_size == 1
), "Context parallelism is only supported by TEDotProductAttention!"
assert (
self.config.window_size is None
), "Sliding Window Attention is only supported by TEDotProductAttention!"
self.layer_number = max(1, layer_number)
self.attn_mask_type = attn_mask_type
self.attention_type = attention_type # unused for now
projection_size = self.config.kv_channels * self.config.num_attention_heads
# Per attention head and per partition values.
if model_comm_pgs is None:
# For backward compatibility, remove in v0.14 and raise error
# raise ValueError("DotProductAttention was called without ModelCommProcessGroups")
model_comm_pgs = ModelCommProcessGroups.use_mpu_process_groups(required_pgs=['tp'])
else:
assert hasattr(
model_comm_pgs, 'tp'
), "DotProductAttention model_comm_pgs must have tp process group"
world_size = model_comm_pgs.tp.size()
self.hidden_size_per_partition = divide(projection_size, world_size)
self.hidden_size_per_attention_head = divide(projection_size, config.num_attention_heads)
self.num_attention_heads_per_partition = divide(self.config.num_attention_heads, world_size)
self.num_query_groups_per_partition = divide(self.config.num_query_groups, world_size)
coeff = None
if softmax_scale is None:
self.softmax_scale = 1.0 / math.sqrt(self.hidden_size_per_attention_head)
else:
self.softmax_scale = softmax_scale
if self.config.apply_query_key_layer_scaling:
coeff = self.layer_number
self.softmax_scale /= coeff
self.scale_mask_softmax = FusedScaleMaskSoftmax(
input_in_fp16=self.config.fp16,
input_in_bf16=self.config.bf16,
attn_mask_type=self.attn_mask_type,
scaled_masked_softmax_fusion=self.config.masked_softmax_fusion,
mask_func=attention_mask_func,
softmax_in_fp32=self.config.attention_softmax_in_fp32,
scale=coeff,
)
# Dropout. Note that for a single iteration, this layer will generate
# different outputs on different number of parallel partitions but
# on average it should not be partition dependent.
self.attention_dropout = torch.nn.Dropout(
self.config.attention_dropout if attention_dropout is None else attention_dropout
)
def forward(
self,
query: Tensor,
key: Tensor,
value: Tensor,
attention_mask: Tensor,
attn_mask_type: AttnMaskType = None,
attention_bias: Tensor = None,
packed_seq_params: Optional[PackedSeqParams] = None,
):
"""Forward."""
assert packed_seq_params is None, (
"Packed sequence is not supported by DotProductAttention."
"Please use TEDotProductAttention instead."
)
assert attention_bias is None, "Attention bias is not supported for DotProductAttention."
# ===================================
# Raw attention scores. [b, n/p, s, s]
# ===================================
# expand the key and value [sk, b, ng, hn] -> [sk, b, np, hn]
# This is a noop for normal attention where ng == np. When using group query attention this
# creates a view that has the keys and values virtually repeated along their dimension to
# match the number of queries.
# attn_mask_type is not used.
if self.num_attention_heads_per_partition // self.num_query_groups_per_partition > 1:
key = key.repeat_interleave(
self.num_attention_heads_per_partition // self.num_query_groups_per_partition, dim=2
)
value = value.repeat_interleave(
self.num_attention_heads_per_partition // self.num_query_groups_per_partition, dim=2
)
# [b, np, sq, sk]
output_size = (query.size(1), query.size(2), query.size(0), key.size(0))
# [sq, b, np, hn] -> [sq, b * np, hn]
# This will be a simple view when doing normal attention, but in group query attention
# the key and value tensors are repeated to match the queries so you can't use
# simple strides to extract the queries.
query = query.reshape(output_size[2], output_size[0] * output_size[1], -1)
# [sk, b, np, hn] -> [sk, b * np, hn]
key = key.view(output_size[3], output_size[0] * output_size[1], -1)
# preallocting input tensor: [b * np, sq, sk]
matmul_input_buffer = parallel_state.get_global_memory_buffer().get_tensor(
(output_size[0] * output_size[1], output_size[2], output_size[3]), query.dtype, "mpu"
)
# Raw attention scores. [b * np, sq, sk]
matmul_result = torch.baddbmm(
matmul_input_buffer,
query.transpose(0, 1), # [b * np, sq, hn]
key.transpose(0, 1).transpose(1, 2), # [b * np, hn, sk]
beta=0.0,
alpha=self.softmax_scale,
)
# change view to [b, np, sq, sk]
attention_scores = matmul_result.view(*output_size)
# ===========================
# Attention probs and dropout
# ===========================
# attention scores and attention mask [b, np, sq, sk]
attention_probs: Tensor = self.scale_mask_softmax(attention_scores, attention_mask)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
if not self.config.sequence_parallel:
with tensor_parallel.get_cuda_rng_tracker().fork():
attention_probs = self.attention_dropout(attention_probs)
else:
attention_probs = self.attention_dropout(attention_probs)
# =========================
# Context layer. [sq, b, hp]
# =========================
# value -> context layer.
# [sk, b, np, hn] --> [b, np, sq, hn]
# context layer shape: [b, np, sq, hn]
output_size = (value.size(1), value.size(2), query.size(0), value.size(3))
# change view [sk, b * np, hn]
value = value.view(value.size(0), output_size[0] * output_size[1], -1)
# change view [b * np, sq, sk]
attention_probs = attention_probs.view(output_size[0] * output_size[1], output_size[2], -1)
# matmul: [b * np, sq, hn]
context = torch.bmm(attention_probs, value.transpose(0, 1))
# change view [b, np, sq, hn]
context = context.view(*output_size)
# [b, np, sq, hn] --> [sq, b, np, hn]
context = context.permute(2, 0, 1, 3).contiguous()
# [sq, b, np, hn] --> [sq, b, hp]
new_context_shape = context.size()[:-2] + (self.hidden_size_per_partition,)
context = context.view(*new_context_shape)
return context- 然后其构建了
linear_proj,注意其使用的是row_parallel_linear,并且它也明确在参数中指出了其输入是并行的,符合一贯的先列并行再行并行计算的结果
其创建了linear_qkv:
linear_qkv是column_parallel_linear类linear_qkv输入维度是标准的self.config.hidden_size,其输出维度是self.query_projection_size + 2 * self.kv_projection_size,因为linear_qkv需要投影生成q、k、v这3个基础张量此外值得注意的是它还专门设计了
gather_output为False,因为其本身就希望使用列并行来多注意力头计算
然后还构建了
submodules.q_layernorm与submodules.k_layernorm
在Forward中完全走的是Attention的代码如下所示,依据
nvtx_range_push其相关流程可以划分为:计算出当前Sequence的q、k、v:
- 其代码如下所示,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52def get_query_key_value_tensors(self, hidden_states, key_value_states=None):
"""
Derives `query`, `key` and `value` tensors from `hidden_states`.
"""
# Attention heads [sq, b, h] --> [sq, b, ng * (np/ng + 2) * hn)]
mixed_qkv, _ = self.linear_qkv(hidden_states)
# [sq, b, hp] --> [sq, b, ng, (np/ng + 2) * hn]
new_tensor_shape = mixed_qkv.size()[:-1] + (
self.num_query_groups_per_partition,
(
(self.num_attention_heads_per_partition // self.num_query_groups_per_partition + 2)
* self.hidden_size_per_attention_head
),
)
mixed_qkv = mixed_qkv.view(*new_tensor_shape)
split_arg_list = [
(
self.num_attention_heads_per_partition
// self.num_query_groups_per_partition
* self.hidden_size_per_attention_head
),
self.hidden_size_per_attention_head,
self.hidden_size_per_attention_head,
]
if SplitAlongDim is not None:
# [sq, b, ng, (np/ng + 2) * hn]
# --> [sq, b, ng, np/ng * hn], [sq, b, ng, hn], [sq, b, ng, hn]
(query, key, value) = SplitAlongDim(mixed_qkv, 3, split_arg_list)
else:
# [sq, b, ng, (np/ng + 2) * hn]
# --> [sq, b, ng, np/ng * hn], [sq, b, ng, hn], [sq, b, ng, hn]
(query, key, value) = torch.split(mixed_qkv, split_arg_list, dim=3)
# [sq, b, ng, np/ng * hn] -> [sq, b, np, hn]
query = query.reshape(query.size(0), query.size(1), -1, self.hidden_size_per_attention_head)
if self.q_layernorm is not None:
query = self.q_layernorm(query)
if self.k_layernorm is not None:
key = self.k_layernorm(key)
if self.config.test_mode:
self.run_realtime_tests()
return query, key, value首先通过
mixed_qkv, _ = self.linear_qkv(hidden_states)得到mixed_qkv,因为self.linear_qkv是列并行并且初始化时设置了gather_output=False,所以得到的mixed_qkv是被TP并行划分后的部分结果,由于前面的检查,所以它必然是q、k、v维度的整数倍。故是从[sq,b,h]转化为了[sq,b,per_tp_num_query_groups *(per_tp_num_heads / per_tp_num_query_groups + 2) * head_dim],结果的最后一维是q、k、v的维度和然后会把形状进行调整,最后得到q的维度为[sq,b,per_tp_num_heads,head_dim],最后得到k与v的维度都是[sq,b,per_tp_num_query_groups, head_dim]
为什么要引入
num_query_groups这一维?因为它在支持 GQA/MQA 时很关键:普通 attention:
num_query_groups== num_heads,每个 group 只有 1 个 query head,对应关系很直接。GQA:
num_query_groups < num_heads,多个 query heads 共享同一组 K/V(在同一个 group 下)。
调整key值
调用
rotary_pos_emb调用
core_attention进行计算调用
linear_proj得到最终结果,因为其是一个row_parallel_linear,所以最后会通过all reduce得到完整的结果
1 | |
Embedding
在构建GPTModel时,在初始化时对embedding层使用的是LanguageModelEmbedding进行初始化,如下所示:
1 | |
LanguageModelEmbedding也会涉及到TP并行切分,因为词表可能会难以放入一个GPU内,所以就可以进行TP切分,每个GPU只保留一部分词表 embedding,然后在Forward时每个GPU只去获取在自己范围内的token的内容,最后all reduce得到完整的embedding。
LanguageModelEmbedding
LanguageModelEmbedding的代码如下所示
1 | |
在初始化时,其使用
tensor_parallel.VocabParallelEmbedding进行初始化,VocabParallelEmbedding的代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127class VocabParallelEmbedding(torch.nn.Module):
"""Embedding parallelized in the vocabulary dimension.
This is mainly adapted from torch.nn.Embedding and all the default
values are kept.
Args:
num_embeddings: vocabulary size.
embedding_dim: size of hidden state.
reduce_scatter_embeddings: Decides whether to perform ReduceScatter after embedding lookup
Keyword Args:
config: A megatron.core.ModelParallelConfig object
"""
def __init__(
self,
num_embeddings: int,
embedding_dim: int,
*,
init_method: Callable,
reduce_scatter_embeddings: bool = False,
config: ModelParallelConfig,
tp_group: Optional[torch.distributed.ProcessGroup] = None,
):
super(VocabParallelEmbedding, self).__init__()
# Keep the input dimensions.
self.num_embeddings = num_embeddings
self.embedding_dim = embedding_dim
self.reduce_scatter_embeddings = reduce_scatter_embeddings
self.tp_group = tp_group
self.tp_group = get_tensor_model_parallel_group_if_none(self.tp_group)
(self.vocab_start_index, self.vocab_end_index) = (
VocabUtility.vocab_range_from_global_vocab_size(
self.num_embeddings, get_pg_rank(self.tp_group), get_pg_size(self.tp_group)
)
)
self.num_embeddings_per_partition = self.vocab_end_index - self.vocab_start_index
self.deterministic_mode = config.deterministic_mode
# Allocate weights and initialize.
if config.use_cpu_initialization:
self.weight = Parameter(
torch.empty(
self.num_embeddings_per_partition, self.embedding_dim, dtype=config.params_dtype
)
)
if config.perform_initialization:
_initialize_affine_weight_cpu(
self.weight,
self.num_embeddings,
self.embedding_dim,
self.num_embeddings_per_partition,
0,
init_method,
params_dtype=config.params_dtype,
rank=get_pg_rank(self.tp_group),
world_size=get_pg_size(self.tp_group),
)
else:
self.weight = Parameter(
torch.empty(
self.num_embeddings_per_partition,
self.embedding_dim,
device=torch.cuda.current_device(),
dtype=config.params_dtype,
)
)
if config.perform_initialization:
_initialize_affine_weight_gpu(self.weight, init_method, partition_dim=0, stride=1)
def forward(self, input_):
"""Forward.
Args:
input_ (torch.Tensor): Input tensor.
"""
if self.tp_group.size() > 1:
# Build the mask.
input_mask = (input_ < self.vocab_start_index) | (input_ >= self.vocab_end_index)
# Mask the input.
masked_input = input_.clone() - self.vocab_start_index
masked_input[input_mask] = 0
else:
masked_input = input_
# Get the embeddings.
if self.deterministic_mode:
output_parallel = self.weight[masked_input]
else:
# F.embedding currently has a non-deterministic backward function
output_parallel = F.embedding(masked_input, self.weight)
# Mask the output embedding.
if self.tp_group.size() > 1:
output_parallel[input_mask, :] = 0.0
if self.reduce_scatter_embeddings:
# Data format change to avoid explicit tranposes : [b s h] --> [s b h].
output_parallel = output_parallel.transpose(0, 1).contiguous()
output = reduce_scatter_to_sequence_parallel_region(
output_parallel, group=self.tp_group
)
else:
# Reduce across all the model parallel GPUs.
output = reduce_from_tensor_model_parallel_region(output_parallel, group=self.tp_group)
return output
def sharded_state_dict(
self,
prefix: str = "",
sharded_offsets: Tuple[Tuple[int, int, int]] = (),
metadata: Optional[dict] = None,
) -> ShardedStateDict:
"""Non-default implementation for embeddings due to `allow_shape_mismatch` param"""
state_dict = self.state_dict(prefix="", keep_vars=True)
weight_prefix = f"{prefix}weight"
return {
weight_prefix: make_tp_sharded_tensor_for_checkpoint(
tensor=state_dict["weight"],
key=weight_prefix,
allow_shape_mismatch=True,
prepend_offsets=sharded_offsets,
)
}VocabParallelEmbedding在初始化时首先根据TP对embedding进行分组,得到起始位置self.vocab_start_index,与结束self.vocab_end_indexVocabParallelEmbedding在Forward时:首先得到
input_mask = (input_ < self.vocab_start_index) | (input_ >= self.vocab_end_index),然后再得到masked_input = input_.clone() - self.vocab_start_index,再将不在这个范围内的置零masked_input[input_mask] = 0masked_input记录了token更新后的id,然后再在weight中依据masked_inputid去取对应的内容,得到output_parallel,并将不属于本rank的清零然后这里依据
reduce_scatter_embeddings有两种输出策略进行选择,注意reduce_scatter_embeddings = ((not self.add_position_embedding) and self.num_tokentypes <= 0 and self.config.sequence_parallel and self.scatter_to_sequence_parallel):reduce_scatter_embeddings=True(配合 sequence parallel)先把布局从
[b, s, h]转成[s, b, h],因为 Megatron 的 sequence-parallel 通常以[seq, batch, hidden]为主(这样更容易沿 seq 维切分/拼接)。然后调用
reduce_scatter_to_sequence_parallel_region:语义上等价于:先对 output_parallel 在 TP 组上做 sum-reduce,再按 sequence 维把结果 scatter 给各 rank。
好处:直接产出 sequence-parallel 需要的分片输出,避免 “all-reduce 得到全量,再手动切分” 的额外开销和内存峰值。
reduce_scatter_embeddings=False(默认更直观)用
reduce_from_tensor_model_parallel_region:语义就是对 output_parallel 在 TP 组上 all-reduce(sum);
每个 TP rank 都拿到完整的 embedding 输出(与未切分词表时一致)。
Tensor并行实验
实验依据采用的是GPT3 857m的模型,运行脚本如下所示,值得注意的是在GPT_MODEL_ARGS参数中设置为了local,即不使用transformer_engine而是使用Megatron-LM本地实现的gpt_layer,与上述介绍对应,此外也设置TP切分维度为4
1 | |
运行的命令为:
1 | |
运行日志如下所示:
1 | |
profiler文件
下图就是初始的LanguageModelEmbedding因为TP维度是4,并且没有Sequence并行,所以后续采用reduce_from_tensor_model_parallel_region来进行all reduce获得token转化结果

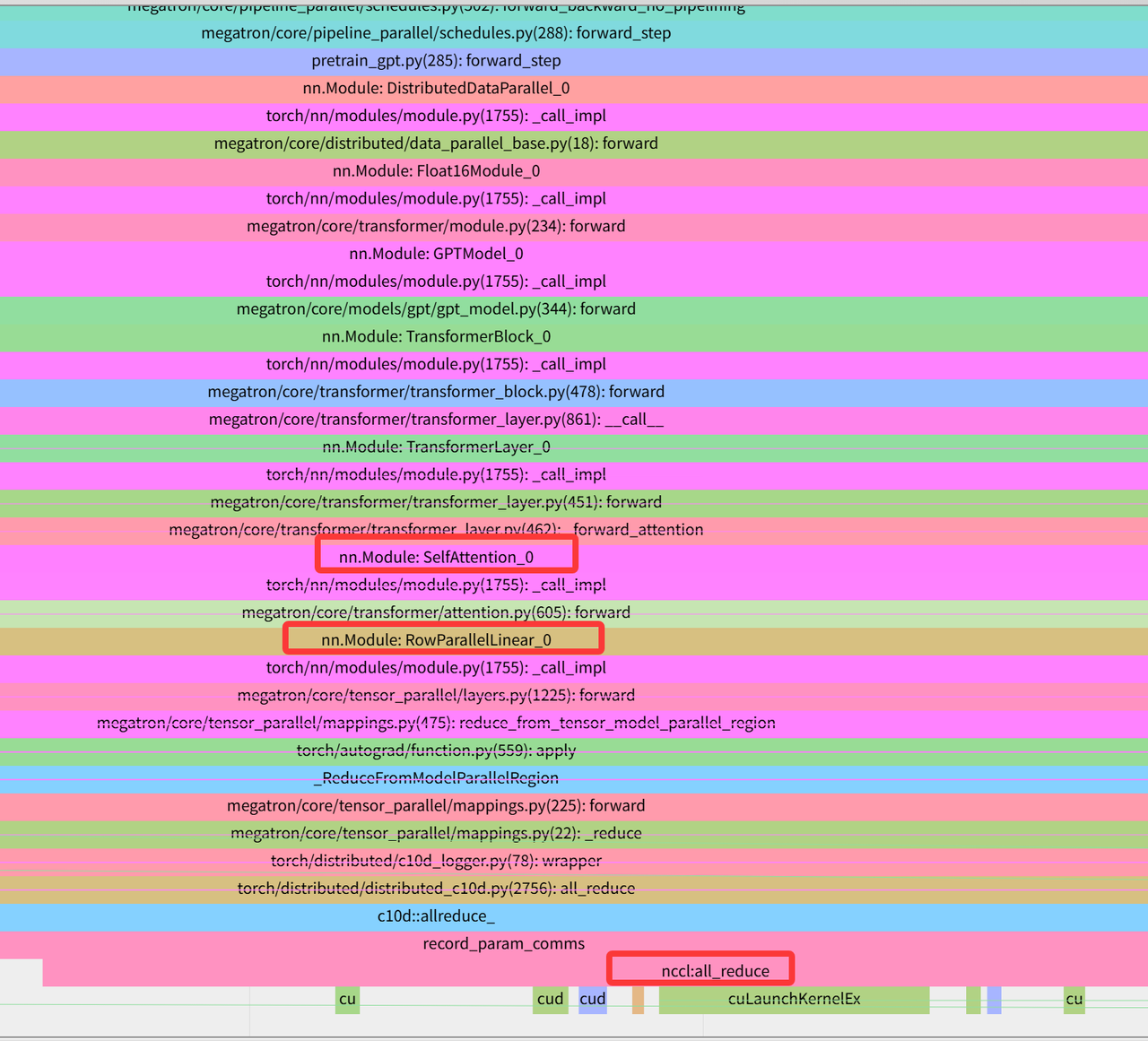
下图是MHA计算时最后一步通过与linear_proj的计算将维度转换回去的计算,这里linear_proj是行并行最后会调用all reduce得到结果
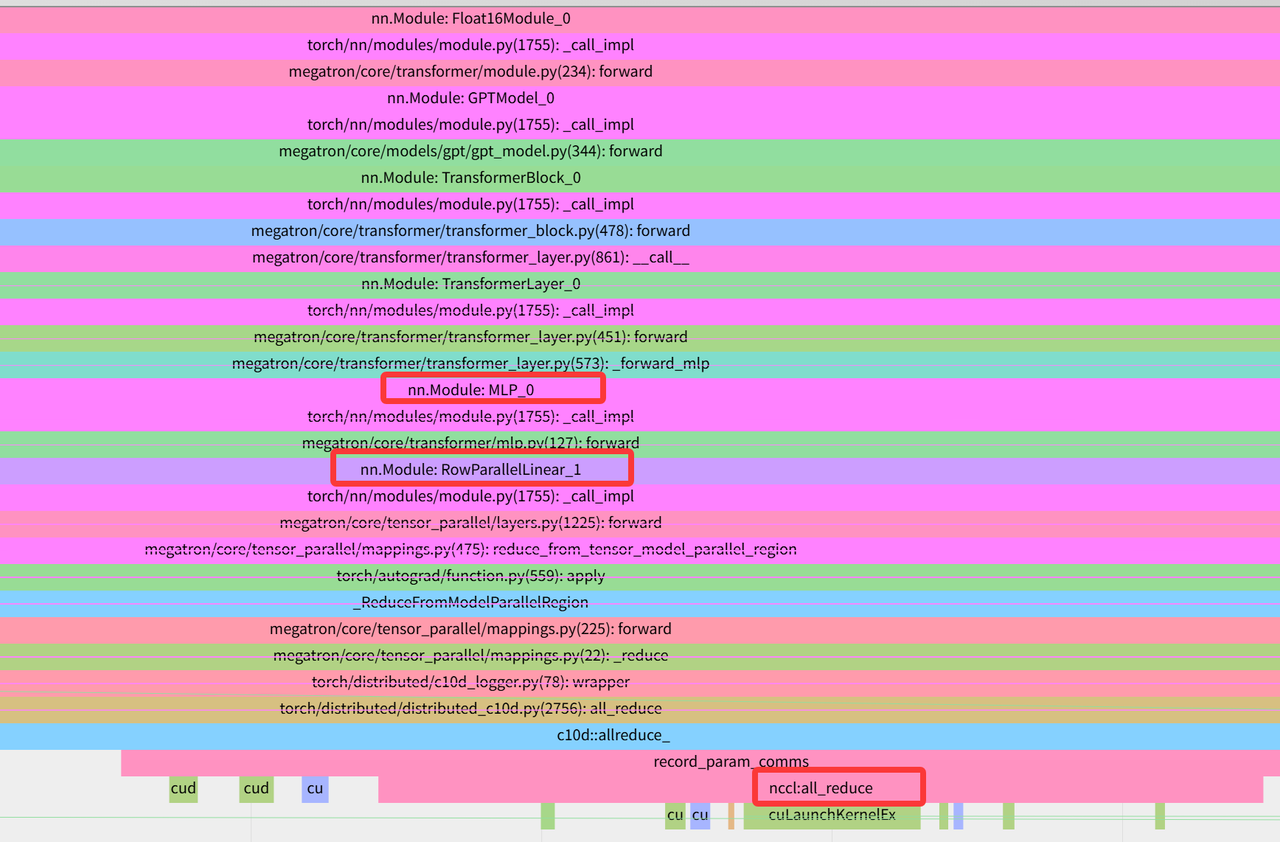
下图是MLP模块中最后行并行后调用all reduce的地方