【Megatron-LM源码分析(六)】-流水线并行-1F1B
理论基础
理论基础建议看之前的博客:
简单而言,流水线并行会对Transformer layers进行切分,主要是有AFAB、1F1B等流水线调度策略
流水线并行相关代码
训练数据获取
在pretrain_gpt中的get_batch函数中,可以看到,只有当前worker变为pp的最后一个stage或者是变为pp的第一个stage,才会去尝试获取数据,否则其数据都是来自pp前后的worker。
1 | |
模型构造
获取模型是在train训练中的get_model中获取,主要代码如下所示:
1 | |
- 可以看到这里主要是对vp进行了专门的处理,借助用户提供的
model_provider函数获取各个vp划分下的模型,从而做到在一个pp rank内存储多个vp进一步切分的模型
用户提供的model_provider函数如下所示,其主要是构建出被pp切分后的GPTModel模型
1 | |
model_provider中进行模型构建时会先尝试构建模型GPTModel,在其中其会构建TransformerBlock,TransformerBlock的初始化代码如下所示:
1 | |
可以看到其首先通过
_get_block_submodules(config, spec, vp_stage)得到了self.submodules_get_block_submodules的代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39def _get_block_submodules(
config: TransformerConfig,
spec: Union[TransformerBlockSubmodules, ModuleSpec],
vp_stage: Optional[int] = None,
) -> TransformerBlockSubmodules:
"""
Retrieve or construct TransformerBlockSubmodules based on the provided specification.
Args:
config (TransformerConfig): Configuration object for the transformer model.
spec (Union[TransformerBlockSubmodules, ModuleSpec]): Specification for the
transformer block submodules. Can be either a TransformerBlockSubmodules
instance or a ModuleSpec.
vp_stage (Optional[int]): Virtual pipeline stage number.
Returns:
TransformerBlockSubmodules: The submodules for the transformer block.
"""
# Transformer block submodules.
if isinstance(spec, TransformerBlockSubmodules):
return spec
# ModuleSpec here is generally assumed to be for a transformer layer that
# is implemented in `transformer_layer.py` or if it subclasses
# `BaseTransformerLayer` from the `transformer_layer.py` file.
elif isinstance(spec, ModuleSpec):
if issubclass(spec.module, TransformerBlock):
return spec.submodules
elif issubclass(spec.module, BaseTransformerLayer):
num_layers = get_num_layers_to_build(config, vp_stage)
return TransformerBlockSubmodules(
layer_specs=[spec] * num_layers, layer_norm=LayerNormImpl
)
else:
raise Exception(f"specialize for {spec.module.__name__}.")
else:
raise Exception(f"specialize for {type(spec).__name__}.")正常情况下会先通过
num_layers = get_num_layers_to_build(config, vp_stage)得到在本pp rank下需要构建的layer数量。get_num_layers_to_build的代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129def get_num_layers_to_build(config: TransformerConfig, vp_stage: Optional[int] = None) -> int:
"""
Determine the number of transformer layers to build for the current pipeline stage.
Args:
config (TransformerConfig): Configuration object containing transformer model parameters.
vp_stage (Optional[int]): Virtual pipeline stage number.
Returns:
int: The number of layers to be built for the current pipeline stage.
"""
# If we have a custom PP layout, straightforwardly
# return the number of decoders in the layout array.
if config.pipeline_model_parallel_layout is not None:
return config.pipeline_model_parallel_layout.get_num_layers_to_build(
layer_type=LayerType.decoder, vp_stage=vp_stage
)
if (
config.num_layers_in_first_pipeline_stage is not None
or config.num_layers_in_last_pipeline_stage is not None
):
assert not (
config.account_for_embedding_in_pipeline_split
or config.account_for_loss_in_pipeline_split
), " \
Does not support standalone embedding stage and standalone loss stage with uneven pp"
# Number of layers to distribute over rest of pipeline stages
layers_to_distribute = config.num_layers
# Number of pipeline stages left for distributing transformer layers
pipeline_stages_left = parallel_state.get_pipeline_model_parallel_world_size()
# If the uneven first (last) pipeline stage is enabled, remove the specified number
# of layers to calculate the number of layers on each middle pipeline stage.
if config.num_layers_in_first_pipeline_stage is not None:
layers_to_distribute -= config.num_layers_in_first_pipeline_stage
pipeline_stages_left -= 1
if config.num_layers_in_last_pipeline_stage is not None:
layers_to_distribute -= config.num_layers_in_last_pipeline_stage
pipeline_stages_left -= 1
# If pp_size <= 2, we do not have any intermediate pipeline stages, and we do not
# need to check if the left over layers are divisible by the left over stages.
if pipeline_stages_left > 0:
assert (
layers_to_distribute % pipeline_stages_left == 0
), "With uneven pipelineing the left over layers must be divisible by left over stages"
num_layers_per_pipeline_rank = layers_to_distribute // pipeline_stages_left
else:
num_layers_per_pipeline_rank = 0
# If the uneven first (last) pipeline stage is enabled, return the specified number
# of layers for all virtual pipeline parallel stages within the first (last) pipeline
# parallel stage.
if (
parallel_state.is_pipeline_first_stage(ignore_virtual=True)
and config.num_layers_in_first_pipeline_stage is not None
):
num_layers_per_pipeline_rank = config.num_layers_in_first_pipeline_stage
if (
parallel_state.is_pipeline_last_stage(ignore_virtual=True)
and config.num_layers_in_last_pipeline_stage is not None
):
num_layers_per_pipeline_rank = config.num_layers_in_last_pipeline_stage
else:
# Include the embedding layer and loss layer into pipeline parallelism partition
num_layers = config.num_layers
if config.account_for_embedding_in_pipeline_split:
num_layers += 1
if config.account_for_loss_in_pipeline_split:
num_layers += 1
assert (
num_layers % config.pipeline_model_parallel_size == 0
), "num_layers should be divisible by pipeline_model_parallel_size"
num_layers_per_pipeline_rank = num_layers // config.pipeline_model_parallel_size
if (
parallel_state.get_virtual_pipeline_model_parallel_world_size() is not None
and config.pipeline_model_parallel_size > 1
):
# Interleaved pipeline parallelism:
# Number of layers in each model chunk is the number of layers in the stage,
# divided by the number of model chunks in a stage.
# With 8 layers, 2 stages, and 4 model chunks, we want an assignment of
# layers to stages like (each list is a model chunk):
# Stage 0: [0] [2] [4] [6]
# Stage 1: [1] [3] [5] [7]
# With 8 layers, 2 stages, and 2 virtual stages, we want an assignment of
# layers to stages like (each list is a model chunk):
# Stage 0: [0, 1] [4, 5]
# Stage 1: [2, 3] [6, 7]
vp_size = parallel_state.get_virtual_pipeline_model_parallel_world_size()
assert (
num_layers_per_pipeline_rank % vp_size == 0
), f"num_layers_per_pipeline_rank {num_layers_per_pipeline_rank} \
should be divisible by vp_size {vp_size}"
num_layers_per_virtual_stage = num_layers_per_pipeline_rank // vp_size
num_layers_to_build = num_layers_per_virtual_stage
else:
# Non-interleaved pipeline parallelism:
# Each stage gets a contiguous set of layers.
num_layers_to_build = num_layers_per_pipeline_rank
# The embedding (or loss) layer cannot function as a standalone transformer layer
# Reduce the number of layers to construct by 1 on the first (or last) stage if the
# embedding (or loss) layer is included in the pipeline parallelism partition and placement.
if (
parallel_state.is_pipeline_first_stage(ignore_virtual=False, vp_stage=vp_stage)
and config.account_for_embedding_in_pipeline_split
):
num_layers_to_build -= 1
assert num_layers_to_build >= 0, "Not enough layers in the first virtual pipeline stage"
if (
parallel_state.is_pipeline_last_stage(ignore_virtual=False, vp_stage=vp_stage)
and config.account_for_loss_in_pipeline_split
):
num_layers_to_build -= 1
assert num_layers_to_build >= 0, "Not enough layers in the last virtual pipeline stage"
return num_layers_to_build其支持自定义的各pp的layer数量,也支持自动计算,即将layer数量按照pp维度进行均分,在自动计算的时候有
account_for_embedding_in_pipeline_split与account_for_loss_in_pipeline_split值得注意,其表示在平分layers的是否将embedding或loss层记为一个layer,并且还支持自定义第一层和最后一层的layer数量如果是带vp的情况,其返回的结果就是进一步被vp维度整除过的数量:
num_layers_per_pipeline_rank // vp_size
在得到
num_layers后会构建出TransformerBlockSubmodules(layer_specs=[spec] * num_layers, layer_norm=LayerNormImpl)并返回
然后其会调用
_build_layers_build_layers代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48def _build_layers(self):
# Transformer layers.
# @jcasper can we improve how we deal with layer_number?
# currently it's only used in CoreAttention?
# if self.apply_query_key_layer_scaling:
# coeff = self.layer_number
# self.norm_factor *= coeff
def build_layer(layer_spec, layer_number):
global_layer_number = layer_number + get_transformer_layer_offset(
self.config, self.vp_stage
) # 1-based index
if self.config.heterogeneous_block_specs:
layer_config = self.config.get_config_for_layer(global_layer_number)
else:
layer_config = self.config
fp8_init_context = get_fp8_context(layer_config, global_layer_number - 1, is_init=True)
with fp8_init_context:
module = build_module(
layer_spec,
config=layer_config,
layer_number=layer_number,
model_comm_pgs=self.model_comm_pgs,
vp_stage=self.vp_stage,
)
return module
# offset is implicit in TransformerLayer
self.layers = torch.nn.ModuleList(
[
build_layer(layer_spec, i + 1)
for i, layer_spec in enumerate(self.submodules.layer_specs)
]
)
# @TODO: add back account_for_embedding_in_pipeline_split (see issue #293)
# In pipeline parallelism, we want to add this LN only to the last stage of the pipeline
# self.post_process and self.post_layer_norm guide this behavior
if self.submodules.layer_norm and self.post_process and self.post_layer_norm:
self.final_layernorm = build_module(
self.submodules.layer_norm,
config=self.config,
hidden_size=self.config.hidden_size,
eps=self.config.layernorm_epsilon,
)
else:
self.final_layernorm = None # Either this or nn.Identity- 其主要内容是实际构建各layer,此外将各layer赋值上
global_layer_number
P2P通信P2PCommunicator整理
代码流程整理
P2PCommunicator主要负责流水线并行中的P2P通信,其代码如下所示:
1 | |
PP并行中每个worker在初始化时
P2PCommunicator,P2PCommunicator就会依据当前worker的rank来自动计算前后的worker:next_rank_pg = (curr_rank_in_pg + 1) % world_size,self.next_rank: int | None = dist.get_global_rank(self.pp_group, next_rank_pg)prev_rank_pg = (curr_rank_in_pg - 1) % world_size,self.prev_rank: int | None = dist.get_global_rank(self.pp_group, prev_rank_pg)
P2PCommunicator的基础函数是_communicate,其他函数都是以此为基础构建出来的首先计算
recv_prev_shape与recv_next_shape:如果sequence长度不是变长的,那么其形状直接等于传入的
tensor_shape如果sequence长度是变长的,就调用
_communicate_shapes通过交流获得接受的形状因为这里的Tensor形状都是假设为
[S, B, H],其中S是可变的,所以只需要传递一个具有3个int的Tensor代表shape。因为除了首尾两个worker外,其他的在前向传播时是从pre接收,向next发送,而在反向传播时是从next接收,向pre发送,所以有4个shape需要获取。发/收 shape 的两种底层实现
如果
config.use_ring_exchange_p2p:- 用
torch.distributed.ring_exchange一次性完成 prev/next 双向交换。
- 用
否则:
构造 P2POp(isend/irecv, …) 列表
调 batch_isend_irecv(ops) 发起
对每个 req wait()
最后 torch.cuda.synchronize() 做额外保护(应对历史 race bug)
依据是否要接收pre或next,创建对应的空Tensor
选择p2p方式获取
p2p_func,总共有3种:use_ring_exchange_p2p:用 ring_exchange 一次做 prev/next 的 send/recv
函数写成 wrapper 并返回空 req 列表(因为 ring_exchange 是同步式接口)
适用:你希望代码极简或某些后端下 ring_exchange 更稳定。
batch_p2p_comm:用 _batched_p2p_ops:
构造 P2POp(isend/irecv, …)
batch_isend_irecv(ops) 一次发起
返回 reqs: List[Work]
并且这里 assert wait_on_reqs,也就是说 batched 模式下默认要求同步等待(除非外面再封一层 overlap 逻辑,但这里看到它强制 wait,这样实现最稳)。
默认
_p2p_ops(非 batched):- 用 torch.distributed.isend/irecv 逐个发起,返回字典 reqs = {“send_next”: Work, …}
调用
p2p_func进行实际数据传输,获得结果p2p_reqs如果有
wait_on_reqs,那么就进行req.wait()来等待,默认是True,即进行等待,只有在send_forward_recv_forward、send_backward_recv_backward时会依据overlap_p2p_comm来判断,如果overlap_p2p_comm为false,即不overlap,那么就直接还是等待,否则就不等待了如果配置了
config.batch_p2p_comm and config.batch_p2p_sync,就进行torch.cuda.synchronize()最终返回
tensor_recv_prev, tensor_recv_next, reqs
以
_communicate为基准,其构造了多个功能函数:单次发送、接收函数:
recv_forward:如果不是first_stage,那么就通过
input_tensor, _, _ = self._communicate( tensor_send_next=None, tensor_send_prev=None, recv_prev=True, recv_next=False, tensor_shape=tensor_shape)获取input_tensor并返回recv_backward:类似,不过参数变为了recv_next=Truesend_forward:如果不是last_stage,那么就通过
self._communicate(tensor_send_next=output_tensor, tensor_send_prev=None, recv_prev=False, recv_next=False, tensor_shape=None)发送output_tensorsend_backward:类似,不过参数变为了tensor_send_prev=input_tensor_grad
发送与接收重叠函数:
send_forward_recv_backward:如果不是last_stage,就通过
_, output_tensor_grad, _ = self._communicate(tensor_send_next=output_tensor, tensor_send_prev=None, recv_prev=False, recv_next=True, tensor_shape=tensor_shape)发送output_tensor,然后接受output_tensor_grad并返回send_backward_recv_forward:类似send_forward_recv_forward:类似,但是注意参数wait_on_reqs=(not overlap_p2p_comm)send_backward_recv_backward:类似,但是注意参数wait_on_reqs=(not overlap_p2p_comm)
全量通信函数:
send_forward_backward_recv_forward_backward:其通过如下代码来发送、接收Forward、Backward结果
1
2
3
4
5
6
7input_tensor, output_tensor_grad, _ = self. _communicate (
tensor_send_next=output_tensor,
tensor_send_prev=input_tensor_grad,
recv_prev=recv_prev,
recv_next=recv_next,
tensor_shape=tensor_shape,
)
3种P2P通信方式介绍
ring_exchange通信
- 直接通过
torch.distributed.ring_exchange(**kwargs)进行通信,代码如下所示:
1 | |
ring_exchange语义上就是“环形邻居交换”,可以同时指定:tensor_send_prev / tensor_recv_prev
tensor_send_next / tensor_recv_next
group=pp_group
其在一次调用里把四个方向的动作都描述完;底层通常会更高效地安排通信(比手工发四个 isend/irecv 更像一个“原子操作”)。
其更不容易因为发送/接收顺序写错而导致潜在死锁/乱序问题(尤其某些后端实现对顺序敏感)。
对“同时收发”的 pipeline 场景很贴合(典型:send_forward_recv_backward、send_backward_recv_forward)
不过其依赖 PyTorch/后端对 ring_exchange 的实现质量;在某些组合上性能不如 batched isend/irecv,并且也更不容易做overlap
_p2p_ops通信
- 其手动按需构造了多个isend、irecv来完成P2P通信,其代码如下所示:
1 | |
其对PP维度为2时进行了一些专门处理,使得其
even_recv_odd_send_group为专门的torch.distributed.group.WORLD为了避免全都向一个方向等待或全向同一个方向发生导致的死锁,以及避免因为大家“同时 send 同一方向”而出现拥塞或某些后端下的等待链,其通过识别当前rank的奇偶来控制是先处理send还是先处理recv,如下所示:
1 | |
- 各个操作的句柄最后都返回了回来,从而更适合做overlap,但是因为可能需要多个通信操作,从而容易使得python开销更大
_batched_p2p_ops通信
_batched_p2p_ops相关代码如下:
1 | |
其先构造多个 P2POp,再一次性发起,最后也直接反正其中每个操作的句柄列表
注意在调用_batched_p2p_ops的时候还有一个限制就是必须配置
wait_on_reqs此外还一般会启用
torch.cuda.synchronize(),这是因为某些 PyTorch 版本的 batch_isend_irecv 曾出现竞态问题,所以这里提供 batch_p2p_sync 强制同步;这会影响性能。
1 | |
PP调度
在实际的train函数中,会通过get_forward_backward_func获得执行一个batch的前向反向传播的forward_backward_func调度函数,获取时主要考虑是否有pp并行,pp并行中是否还包含了vp切分。
1 | |
获取到的forward_backward_func函数会在进一步的train_step中被调用,代码如下所示,forward_backward_func会负责在一个batch内的如何调度多个micro batch进行前向、反向传播。
1 | |
其中的参数forward_step_func往往就是用户提供的一次micro_batch前向传播的方法
1 | |
forward_backward_pipelining_without_interleaving
我们这里先看不含vp切分即不进行交错1F1B调度的forward_backward_pipelining_without_interleaving
1F1B理论分析
前面理论基础提到的博客也有对1F1B的介绍,这里简单回顾一下。
- 1F1B的流程如下图所示,下图pp并行度是4,一个batch中的micro_batch的含量为8。
注意其与Megatron-LM中的图有所不同,看代码应该是下面这份图才是准确的
.jpg)
在1F1B流程中包含几个阶段,分别为:流水线预热(warmup)→ 稳态交替 forward/backward → 冷却(cooldown)把剩余 backward 做完
然后1F1B还需要负责一个batch结束后进行数据并行下的梯度同步
代码分析
forward_backward_pipelining_without_interleaving其代码如下所示:
1 | |
其整体流程如下:
参数检查,因为不采用vp交错,所以model数量与data_iterator数量都应该为1
如果没有传入
p2p_communicator就构建对应的P2PCommunicator;如果没有传入grad_finalize_pgs就也构建对应的GradFinalizeProcessGroups。如果传入了就检查其是否完整如果启用了
no_sync,即一次反向传播后不立刻进行梯度同步,就构建对应的no_sync_context。因为在 pipeline 里,大部分 backward 进行时如果立刻触发 DP all-reduce,会产生额外同步/降低 overlap;在前面的pre_train流程分析中我们也看到Megatron-LM只在最后一次micro_batch同步中再进行梯度同步。计算 warmup / steady 的 microbatch 数:
num_warmup_microbatches = min(pp_size - pp_rank - 1, num_microbatches),以上图为例,pp_rank=0的首个worker的num_warmup_microbatches=3,pp_rank=3的最后一个worker的num_warmup_microbatches=0num_microbatches_remaining = num_microbatches - num_warmup_microbatches,以上图为例,pp_rank=0的首个worker的num_microbatches_remaining=5,pp_rank=3的最后一个worker的num_warmup_microbatches=8
与前述博客(https://slipegg.github.io/2025/12/08/Reducing-Activation-Paper-Note/)中提到的选择性激活方法有关,如果配置了选择性激活以减少峰值激活显存占用量,则只对一部分layers激活做保存。如果有相关配置就设定`max_outstanding_backprops = num_warmup_microbatches + 1`
推导PP传输的张量的大小
相关代码如下:
基本的,如果采用了上下文并行,那么就
effective_seq_length // cp_group.size(),如果还采用了序列并行,那么进一步的effective_seq_length = effective_seq_length // tp_group.size()。最终推导出的形状是[
effective_seq_length,batch_size,hidden_size]
在这里也可以看到上下文并行是对序列上下文彻底的切分,而序列并行是在上下文并行的基础上的进一步切分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24def get_tensor_shapes(
*,
seq_length: int,
micro_batch_size: int,
decoder_seq_length: int,
config,
tp_group: torch.distributed.ProcessGroup,
cp_group: torch.distributed.ProcessGroup,
):
"""
Determine right tensor sizes (based on position of rank with respect to split rank) and
model size.
"""
tensor_shapes = []
# Use decoder_seq_length if provided, otherwise use seq_length
effective_seq_length = decoder_seq_length if decoder_seq_length is not None else seq_length
effective_seq_length = effective_seq_length // cp_group.size()
if config.sequence_parallel:
effective_seq_length = effective_seq_length // tp_group.size()
tensor_shapes.append((effective_seq_length, micro_batch_size, config.hidden_size))
return tensor_shapes如果不是
forward_only模式,那么需要初始化input_tensor与output_tensor,它们 是“跨 stage 传输的 activation”(该 stage 的输入输出),在 backward 时需要重新拿出来求梯度,是属于 pipeline schedule 的核心缓存。进入warm up阶段,每个worker需要处理
num_warmup_microbatches次,每次的流程为:-1.jpg)
通过
p2p_communicator.recv_forward来获取上一层PP传递的input_tensor(第一层会自动跳过)依据接收到的输入或者从data_loader中获取数据进行自己本地模型的前向传播得到结果
output_tensor- 看
forward_step,其中关键的set_input_tensor = get_attr_wrapped_model(model, "set_input_tensor")与set_input_tensor(input_tensor)是将输入的input_tensor存入到了模型参数中的input_tensor中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134def forward_step(
forward_step_func,
data_iterator,
model,
num_microbatches,
input_tensor,
forward_data_store,
config,
cp_group_size,
collect_non_loss_data=False,
checkpoint_activations_microbatch=None,
is_first_microbatch=False,
current_microbatch=None,
vp_stage=None,
is_last_stage=True,
):
"""Forward step for passed-in model.
If it is the first stage, the input tensor is obtained from the data_iterator.
Otherwise, the passed-in input_tensor is used.
Args:
forward_step_func (callable):
The forward step function for the model that takes the
data iterator as the first argument, and model as the second.
This user's forward step is expected to output a tuple of two elements:
1. The output object from the forward step. This output object needs to be a
tensor or some kind of collection of tensors. The only hard requirement
for this object is that it needs to be acceptible as input into the second
function.
2. A function to reduce (optionally) the output from the forward step. This
could be a reduction over the loss from the model, it could be a function that
grabs the output from the model and reformats, it could be a function that just
passes through the model output. This function must have one of the following
patterns, and depending on the pattern different things happen internally:
a. A tuple of reduced loss and some other data. Note that in this case
the first argument is divided by the number of global microbatches,
assuming it is a loss, so that the loss is stable as a function of
the number of devices the step is split across.
b. A triple of reduced loss, number of tokens, and some other data. This
is similar to case (a), but the loss is further averaged across the
number of tokens in the batch. If the user is not already averaging
across the number of tokens, this pattern is useful to use.
c. Any arbitrary data the user wants (eg a dictionary of tensors, a list
of tensors, etc in the case of inference). To trigger case 3 you need
to specify `collect_non_loss_data=True` and you may also want to
specify `forward_only=True` in the call to the parent forward_backward
function.
data_iterator (iterator):
The data iterator.
model (nn.Module):
The model to perform the forward step on.
num_microbatches (int):
The number of microbatches.
input_tensor (Tensor or list[Tensor]):
The input tensor(s) for the forward step.
forward_data_store (list):
The list to store the forward data. If you go down path 2.a or
2.b for the return of your forward reduction function then this will store only the
final dimension of the output, for example the metadata output by the loss function.
If you go down the path of 2.c then this will store the entire output of the forward
reduction function applied to the model output.
config (object):
The configuration object.
collect_non_loss_data (bool, optional):
Whether to collect non-loss data. Defaults to False.
This is the path to use if you want to collect arbitrary output from the model forward,
such as with inference use cases. Defaults to False.
checkpoint_activations_microbatch (int, optional):
The microbatch to checkpoint activations.
Defaults to None.
is_first_microbatch (bool, optional):
Whether it is the first microbatch. Defaults to False.
current_microbatch (int, optional):
The current microbatch. Defaults to None.
vp_stage (int, optional):
The virtual pipeline stage. Defaults to None.
is_last_stage (bool, optional):
Whether it is the last stage. Defaults to True.
Also considering virtual stages.
In case of PP/VPP, is_last_stage/is_vp_last_stage.
Returns:
Tensor or list[Tensor]: The output object(s) from the forward step.
Tensor: The number of tokens.
"""
from megatron.core.transformer.multi_token_prediction import MTPLossAutoScaler
if config.timers is not None:
config.timers('forward-compute', log_level=2).start()
if is_first_microbatch and hasattr(model, 'set_is_first_microbatch'):
model.set_is_first_microbatch()
if current_microbatch is not None:
set_current_microbatch(model, current_microbatch)
unwrap_output_tensor = False
if not isinstance(input_tensor, list):
input_tensor = [input_tensor]
unwrap_output_tensor = True
set_input_tensor = get_attr_wrapped_model(model, "set_input_tensor")
set_input_tensor(input_tensor)
if config.enable_autocast:
context_manager = torch.autocast("cuda", dtype=config.autocast_dtype)
else:
context_manager = contextlib.nullcontext()
with context_manager:
if checkpoint_activations_microbatch is None:
output_tensor, loss_func = forward_step_func(data_iterator, model)
else:
output_tensor, loss_func = forward_step_func(
data_iterator, model, checkpoint_activations_microbatch
)
output_tensor, num_tokens = forward_step_calc_loss(
model,
output_tensor,
loss_func,
config,
vp_stage,
collect_non_loss_data,
num_microbatches,
forward_data_store,
cp_group_size,
is_last_stage,
)
if unwrap_output_tensor:
return output_tensor, num_tokens
return [output_tensor], num_tokens- 如下在
TransformerBlock中的Forward的代码中也可以看出,如果没有pre_process,即不是第一层的话,就直接读取自身的input_tensor,如果是第一层的话就读取外部从data_loader中获取的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56class TransformerBlock(MegatronModule):
"""Transformer class."""
def forward(
self,
hidden_states: Union[Tensor, WrappedTensor],
attention_mask: Optional[Tensor],
context: Optional[Tensor] = None,
context_mask: Optional[Tensor] = None,
rotary_pos_emb: Optional[Tensor] = None,
rotary_pos_cos: Optional[Tensor] = None,
rotary_pos_sin: Optional[Tensor] = None,
attention_bias: Optional[Tensor] = None,
inference_context: Optional[BaseInferenceContext] = None,
packed_seq_params: Optional[PackedSeqParams] = None,
sequence_len_offset: Optional[Tensor] = None,
*,
inference_params: Optional[BaseInferenceContext] = None,
):
"""
Perform the forward pass through the transformer block.
This method handles the core computation of the transformer, including
self-attention, optional cross-attention, and feed-forward operations.
Args:
hidden_states (Union[Tensor, WrappedTensor]): Input tensor of shape [s, b, h]
where s is the sequence length, b is the batch size, and h is the hidden size.
Can be passed as a WrappedTensor during inference to avoid an obsolete
reference in the calling function.
attention_mask (Tensor): Boolean tensor of shape [1, 1, s, s] for masking
self-attention.
context (Tensor, optional): Context tensor for cross-attention.
context_mask (Tensor, optional): Mask for cross-attention context
rotary_pos_emb (Tensor, optional): Rotary positional embeddings.
attention_bias (Tensor): Bias tensor for Q * K.T of shape in shape broadcastable
to [b, num_head, sq, skv], e.g. [1, 1, sq, skv].
Used as an alternative to apply attention mask for TE cuDNN attention.
inference_context (BaseInferenceContext, optional): Parameters for inference-time
optimizations.
packed_seq_params (PackedSeqParams, optional): Parameters for packed sequence
processing.
Returns:
Union[Tensor, Tuple[Tensor, Tensor]]: The output hidden states tensor of shape
[s, b, h], and optionally the updated context tensor if cross-attention is used.
"""
inference_context = deprecate_inference_params(inference_context, inference_params)
# Delete the obsolete reference to the initial input tensor if necessary
if isinstance(hidden_states, WrappedTensor):
hidden_states = hidden_states.unwrap()
if not self.pre_process:
# See set_input_tensor()
hidden_states = self.input_tensor- 看
通过
p2p_communicator.send_forward将结果output_tensor传输到下一层(最后一层会自动跳过)如果不是
forward_only模式,就将input_tensor与output_tensorappend进队列存储,并且还会按需清除掉output_tensor
如果
num_warmup_microbatches大于0,那么就需要先通过p2p_communicator.recv_forward来获取上一层PP传递的input_tensor(第一层会自动跳过)。存在micro_batch次数过少而导致没有稳定运行的阶段进入稳定运行steady 阶段:
-2.jpg)
依据接收到的输入或者从data_loader中获取数据进行自己本地模型的前向传播得到结果
output_tensor如果是
forward_only模式:通过
p2p_communicator.send_forward来发送output_tensor到下一层pp如果不是最后一次迭代,还需要继续通过
p2p_communicator.recv_forward来获取上一层PP传递的input_tensor(第一层会自动跳过)。整体与warm up阶段相同
如果不是
forward_only模式:就通过
p2p_communicator.send_forward_recv_backward来发送output_tensor并接受backward结果output_tensor_grad,将
input_tensor与output_tensorappend进队列存储,并且还会按需清除掉output_tensor如果当前的rank是最后一个rank,即
num_warmup_microbatches == 0,并且是最后一次稳态迭代时,才会启动grad sync,因为这时已经到了batch的最后阶段,也确实需要进行梯度同步了再从队列头 pop 出最早的
input_tensor与output_tensor,再结合获取的output_tensor_grad用于做 backward,得到input_tensor_grad如果不是最后一次的稳态迭代,就通过
p2p_communicator.send_backward_recv_forward来发送input_tensor_grad并且获取新输入;如果是最后一次稳态迭代,那么就不需要获取新输入,直接通过p2p_communicator.send_backward发送input_tensor_grad即可
然后进入cooldown阶段,cooldown阶段需要迭代的数量与warmup相同,就是
num_warmup_microbatches:-3.jpg)
如果是cooldown的最后一个阶段,就启动grad sync
从队列头 pop 出最早的
input_tensor与output_tensor,并通过p2p_communicator.recv_backward获取output_tensor_grad使用
input_tensor与output_tensor、output_tensor_grad进行反向传播,获得input_tensor_grad通过
p2p_communicator.send_backward将input_tensor_grad发送给pp上一层
如果定义了
config.finalize_model_grads_func就启用,其主要负责对所有的梯度进行最终整理与同步,通常包括:DP 的 full grad all-reduce / reduce-scatter
sequence parallel 下 layernorm 的 all-reduce
pipeline parallel 情况下 embedding all-reduce(embedding group)
最后如果启用 cuda graph 且 scope 不是 full_iteration,会调用 create_cudagraphs()。
1F1B流水线并行实验
实验依据采用的是GPT3 857m的模型,运行脚本如下所示,值得注意的是,这里设置了pp维度为4,设置batch_size为16,micro_batch_size为2,所以一个batch中存在8个micro_batch,整体与前述的图片中的情况类似。
1 | |
运行命令为:
1 | |
得到的部分运行日志如下所示:
1 | |
Profiler文件
注意这里采用了新UIhttps://ui.perfetto.dev/来查看Profiler文件。
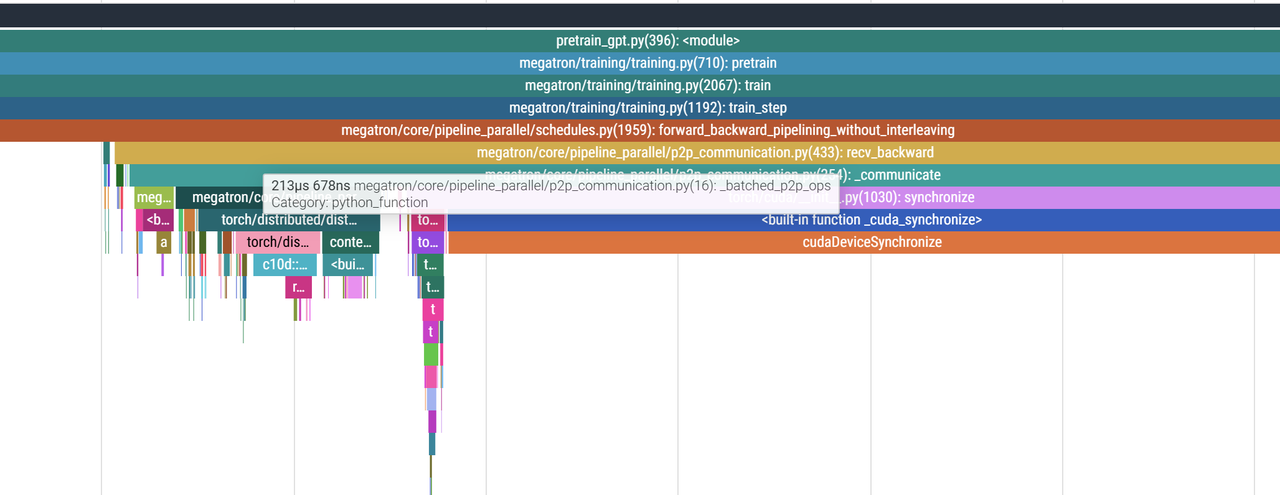
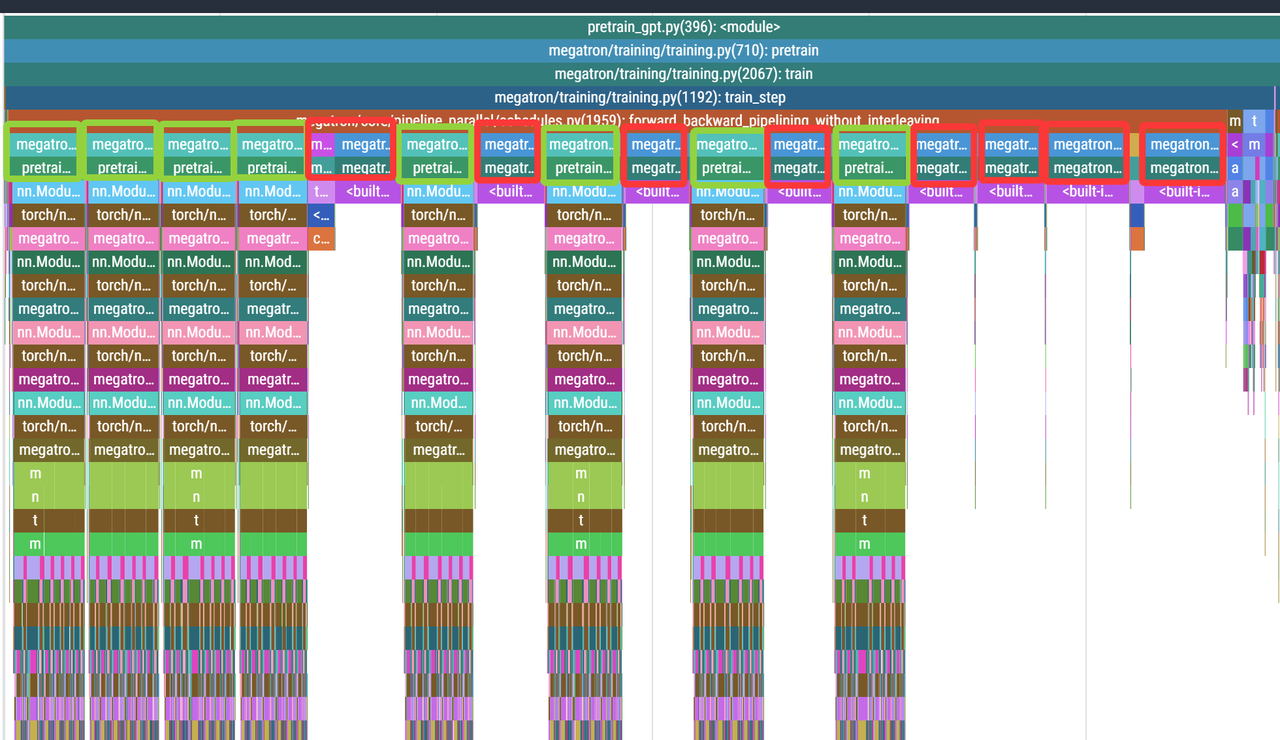
可以看到这里与之前的代码分析基本一致,注意这里是rank 0的分析,所以前面warmup阶段有3个Forward,然后进入steady阶段,有Forward+Backward连续触发了5次,然后最后用3次Backward进行cold down。
细看前面warmup阶段,在两个Forward之间send_forward的P2P通信是batched_p2p_ops,并且紧接着是一个cuda sync。
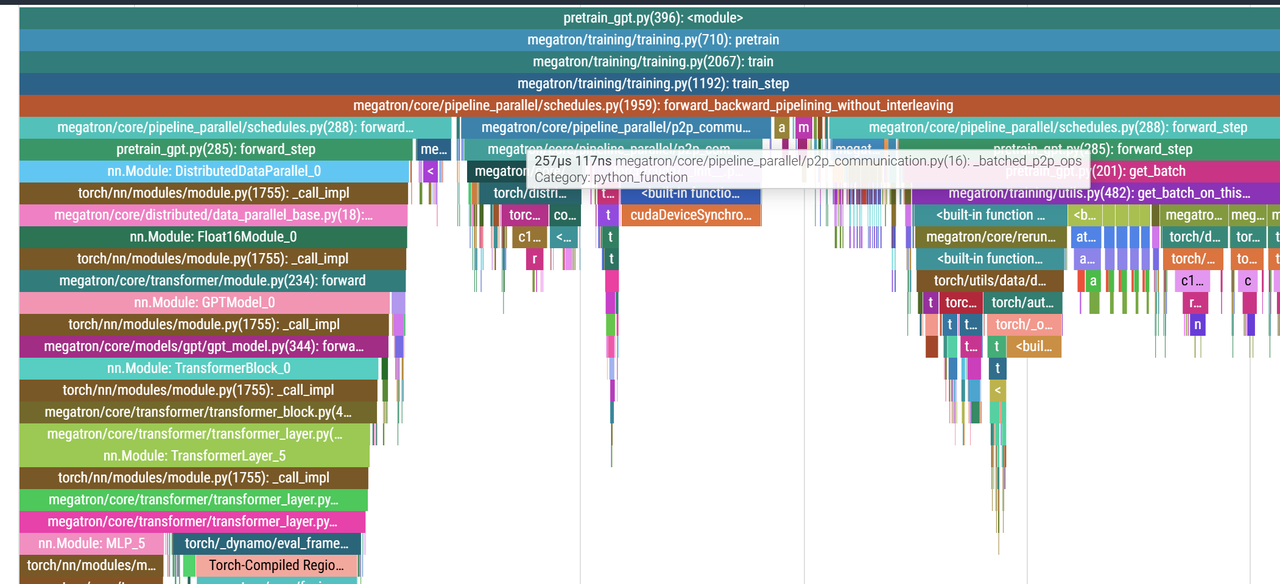
而在steady阶段采用的send_forward_recv_backward也是_batch_p2p_ops:

在最后的cold down阶段采用的recv_backward也是_batch_p2p_ops: