【论文阅读】Efficient Memory Management for Large Language Model Serving with PagedAttention(vLLM论文)
发表会议:SOSP’23(CCF-A)
团队:UC Berkeley
背景
大模型服务化带来了高昂的运行成本,需要进行推理优化提高吞吐、降低成本
LLM推理过程是一个自回归模型,关键的注意力机制模块需要进行KV Cache,而现有GPU的显存有限,留给KV Cache的空间不多,需要进行细致的KV Cache显存管理。例如,对于13B参数OPT模型,单个Token的KV缓存需要800KB的空间,计算为2(键和值向量)×5120(隐藏状态大小)×40(层数)×2(每个FP16字节)。由于OPT最多可以生成2048个令牌的序列,因此存储一个请求的KV缓存所需的内存可以高达1.6GB,而GPU的显存容量在几十GB的水平。

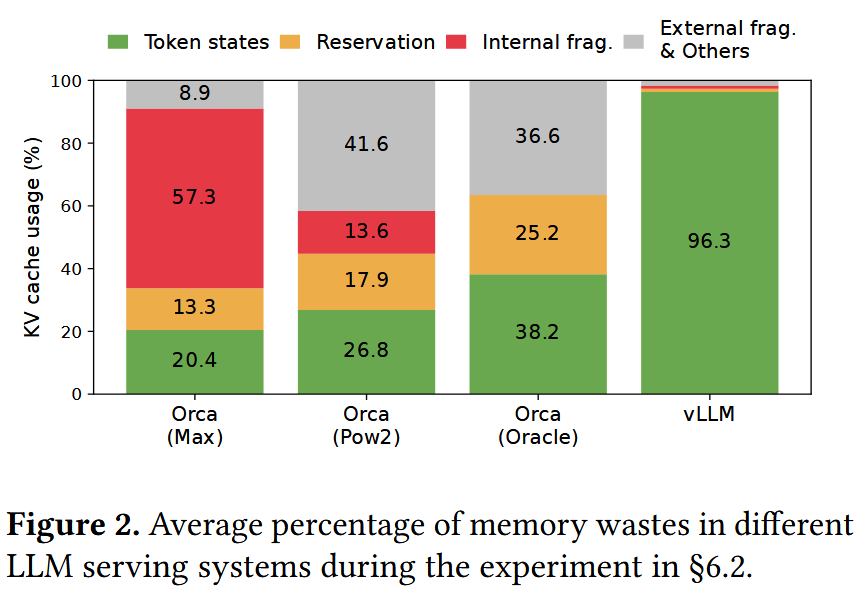
现有的LLM服务无法有效地管理KV Cache,因为它们将KV Cache存储在连续的内存空间中(因为大多数深度学习框架要求张量存储在连续空间中)。而LLM推理因为自回归的特性,KV Cache随着模型生成新的Token,可能会逐渐增长,也可能随着结束Token的出现而消除,并且它的长度与生命周期难以提前获知。这导致现有系统在以下几个方面低效:
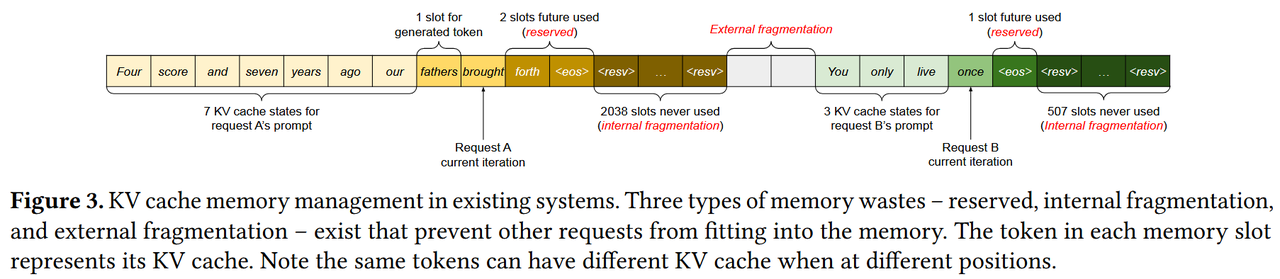
现有系统往往按照最大可能长度进行显存的静态分配,这导致其存在了3个部分的显存浪费:
分配给未来Token生成使用的预留显存(Reserved)
提前分配了但是实际却不需要用到的内部显存碎片(Internal fragmentation)
系统中因为频繁静态分配导致的过小无法被静态分配使用的外部显存碎片(External fragmentation)
现有系统也不能利用显存共享的机会。LLM服务通常会通过并行采样、波束搜索的方式为每个请求生成多个输出,这里的就可以部分共享其前置的KV Cache,但是现有系统因为KV Cache缓存在单独的连续空间所以不能做到共享
为了高效的管理显存,本文提出了一种受操作系统中经典虚拟内存和分页技术启发的高效注意力算力PagedAttention,并以此为基础构建了LLM推理服务vLLM
方法思路
PagedAttention
PagedAttention将K、V进行了分块,每块的K、V数量为B,每块会在物理存储中连续存储。各块之间并不保证连续,如下图所示,其前面的K、V被存储到了3个Block中。
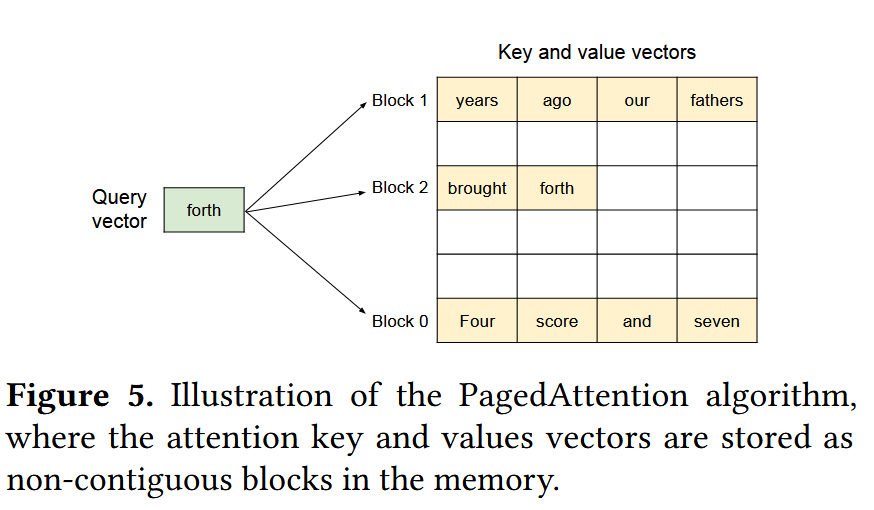
在此分块的背景下,计算Attention的方式也转变为了以Block为单位的分块计算,如下所示。
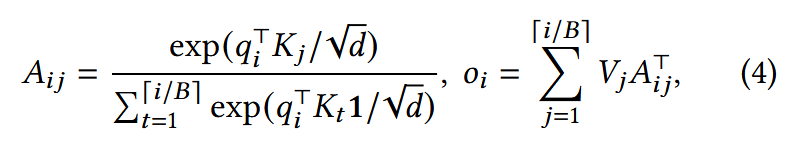
在计算 $Attention= \mathrm{softmax}!\left(\frac{Q K^\top}{\sqrt{d_k}}\right)$时,将当前最新的$q_i$与第j个Block中的 $K_j$直接进行矩阵计算就可以批量得到该Block中各个K对于$q_i$的Attention,即$A_{ij}$。
然后在计算最新输出$o_i$时,对于第j个Block,需要将刚得到的$A_{ij}$与原本缓存该Block的 $V_j$进行矩阵乘,然后进行累加即可得到$o_i$
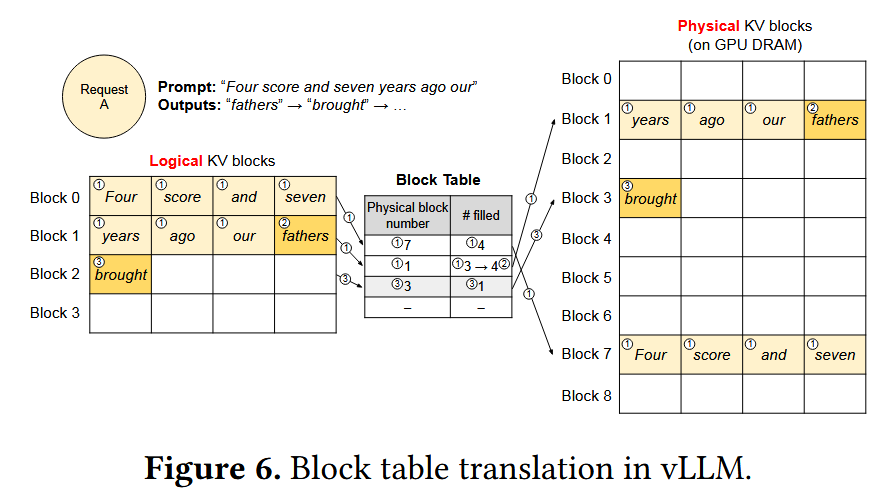
KV Cache管理
系统中存在逻辑 Block和物理Block两个概念,其通过Block Table进行对应,Block Table记录了逻辑Block与物理Block的对应关系以及当前物理Block具体已填充的数量
每个物理Block具有固定的大小,物理Block可以按需灵活分配与释放

复杂解码算法适配
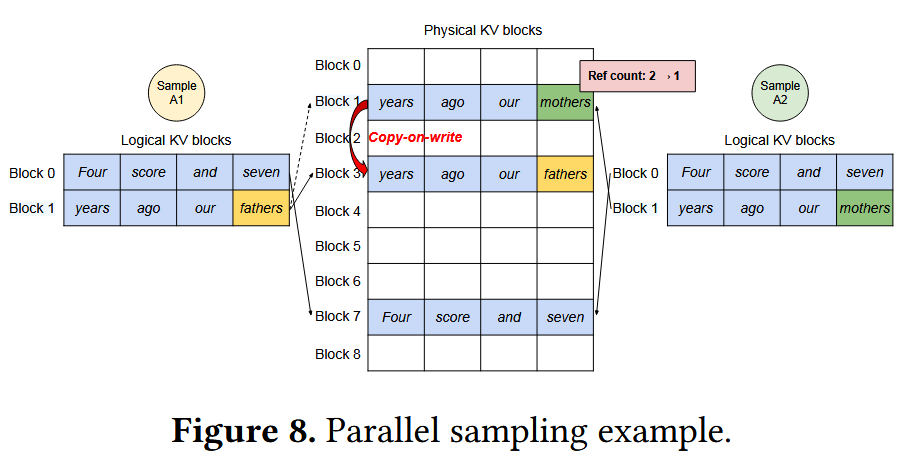
- 平行采样示例:可以让两个Sample一开始的prompt都共享同一个物理KV Cache block,并且注意对该Block设置引用计数器为2,然后当一个Sample开始生成并写入新的Token时,因为观察到引用计数器大于1,所以就采用Copy-on-write的处理方法,将其复制一份再写,同时将原本的引用计数器减一
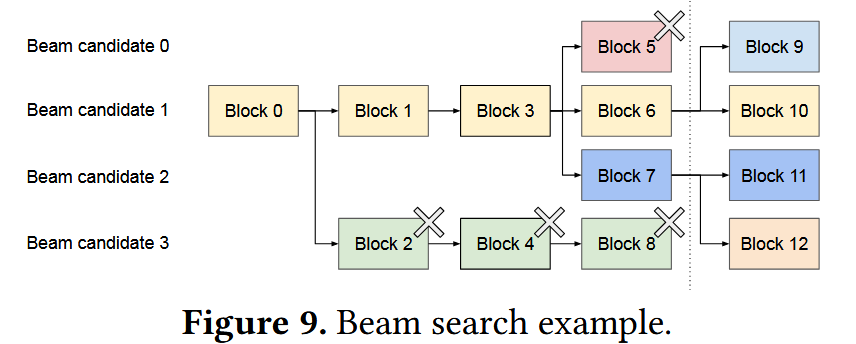
- 波束搜索示例:其保留了top k个最可能的序列,各序列除了prompt外,已生成的序列也可能会共享,通过PagedAttention的技术可以对其做到共享,并且因为block分块,所以在Copy-on-write复制的时候只会复制最新生成的token所在的一个block。
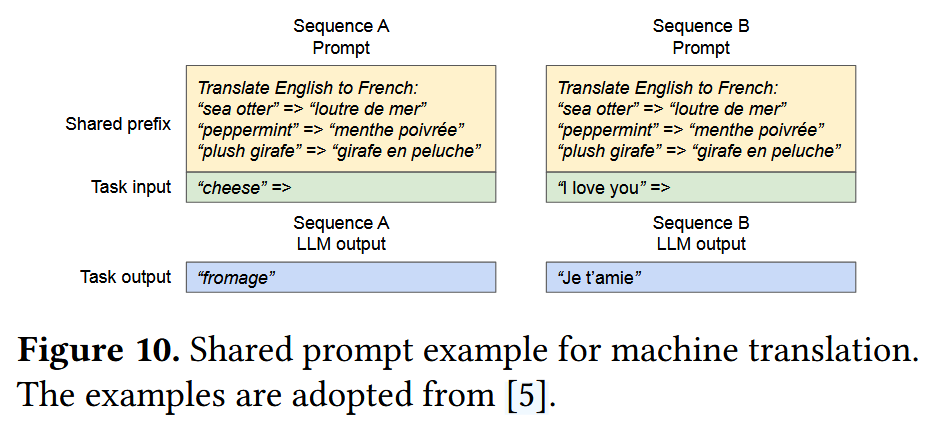
- 共享前缀实例:多个请求共享同一个前缀,所以可以直接使用同一个前缀的物理块
调度与抢占
vLLM对所有请求采用first-come-first-serve(FCFS)调度策略,确保公平,防止饥饿。
当vLLM需要抢占请求时,它确保最早到达的请求被优先服务,最新的请求被优先抢占。
具体在抢占时采用“全有或全无”的策略,驱逐序列块时将序列中的所有块都驱逐,对于波束搜索这类一个请求中包含多个序列的,也是倾向于一起被抢占或重调度
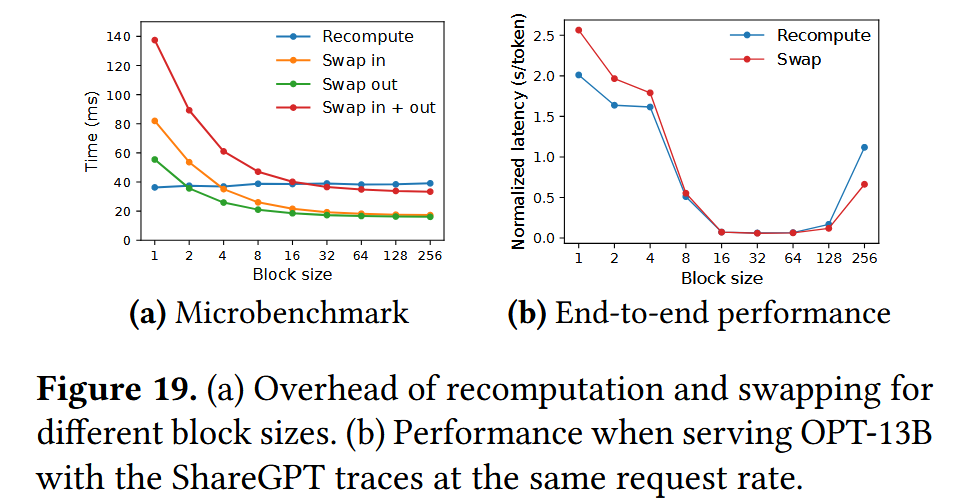
而在恢复时有两种方法,如下图所示,,这两种方法的效率取决Block size以及系统swap速度和计算速度等
与主机CPU内存进行交换
将K、V进行重计算
分布式执行
对于TP并行,其采用的是Megatron-LM风格的TP并行,在分割多头注意力时,每个worker都至少保留完整的一个注意力头
并且整体也适配SPMD的执行策略,虽然访问的是同一个逻辑Block,但是不同worker上对应的物理Block是不同的
实现细节优化
内核级优化:
Fused reshape and block write:KV Cache需要被reshape为block的格式然后被存储到物理显存中,为了加速将其融合为了一个kernel
Fusing block read and attention:其调整FasterTransform中的注意力内核,根据块表读取KV缓存,并动态执行注意力操作。为了确保合并内存访问,还分配一个GPU warp来读取每个块
Fused block copy:其实现了一个内核,将不同块的复制操作批处理到单个内核启动中,以避免大量小数据移动的调用
vLLM使用三种关键方法实现各种解码算法:
Fork: 从现有序列中创建一个新序列。
Append: 将一个新TOken附加到序列中
Free: 删除序列
实验效果
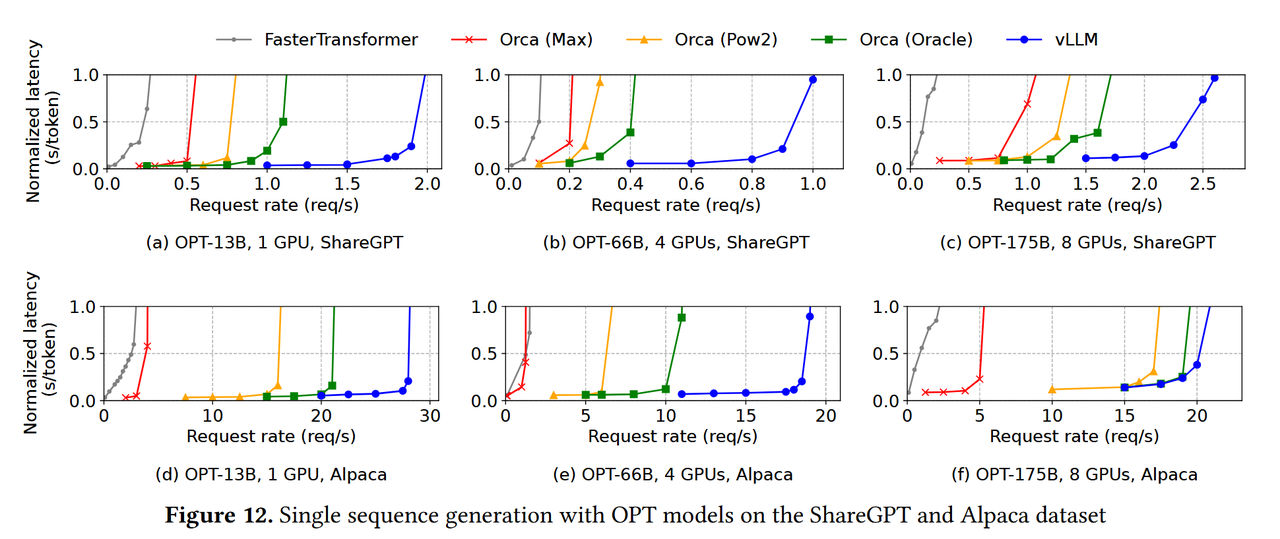
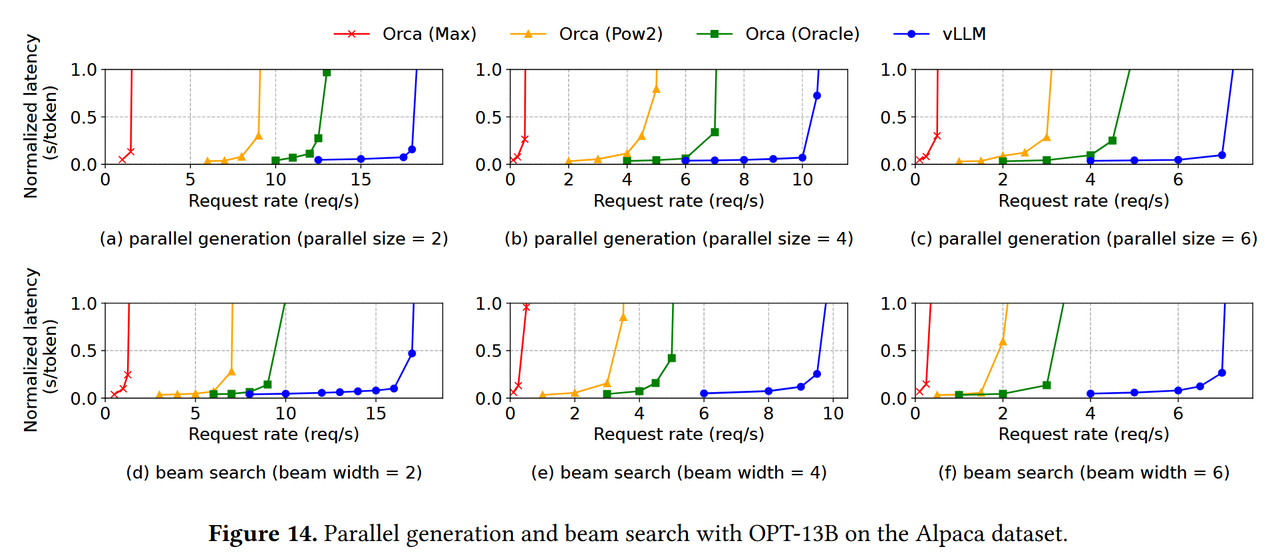
- 由于vLLM出色的显存管理能力,其对比当时其他的FasterTransformer与Orca在单序列生成、多序列生成方面都取得了更好的效果

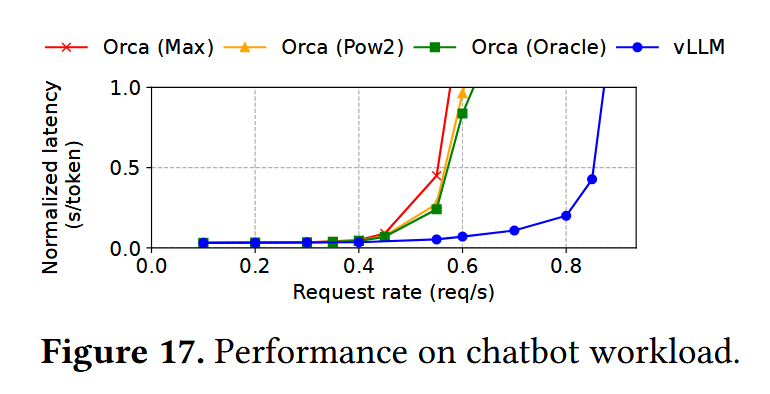
- 整体在ChatBot应用上的表现是Orca的两倍以上
总结
虚拟页表技术是原本CPU内存管理的经典技术了,被挪用到大模型推理场景下进行显存管理确实有点大道至简的感觉
整体思路很好理解,效果也理所当然的很强。不过感觉确实最关键的是将其实现出来并能够支持上到生产环境去使用