【Nano-vLLM源码分析(二)】关键类实现
Block相关
Block Manger是实现vLLM中提出的PagedAttention的关键,PagedAttention通过对KV Cache实现类似虚拟页表的逻辑Block分区与物理Block分区的划分来实现更灵活的显存管理。
BlockManager 相关代码主要负责 KV cache 的 block 分配/回收,以及 prefix cache(前缀块复用):把“完整的 block(长度=block_size 的 token 段)”做 hash,后续遇到相同前缀就直接复用同一段 KV cache,从而跳过重复 prefill。
分配基本单元Block类
- 基础Block的代码如下所示:
1 | |
Block代表的是对物理显存的划分,一个block存储block_size个kv_cache
其记录了Block的一些基本属性,包括
block_id:块编号,对应 KV cache 里的一个 block 槽位。ref_count:引用计数。多个序列如果共享同一前缀块(prefix cache 命中),会共同引用同一个 block;只有当引用计数降到 0 才能回收。hash:该 block 对应 token 内容的哈希(仅对“满块”有效;最后不满的块通常 hash=-1)。token_ids:该 block 的 token 序列副本,用来做安全校验(避免 hash 冲突导致错误复用)。
其主要的方法函数如下:
reset():把 block 变成“已分配但尚未形成可缓存键”的状态:ref_count=1, hash=-1, token_ids=[]update(hash, token_ids):当一个 block 变成“满块”时,记录它的 hash 和 token_ids,允许后续复用。
BlockManager定义
BlockManager的代码如下所示,其主要是维护了一个自己的block列表,然后各个seq按需就自己的block与这里的block建立或销毁映射关系
1 | |
其在初始化时,传入的参数包含了配置一个
BlockManager所管理的单个Block的大小,以及block的数量。以此为基础初始化了以下几个变量:self.blocks: num_blocks 个 Block 元信息对象hash_to_block_id: hash -> block_id 的索引,用于 prefix cache 查找free_block_ids: 空闲 block id 队列(deque),分配时总是取队首 free_block_ids[0]used_block_ids: 已被使用的 block id 集合(注意:可能出现“hash 命中但 block_id 不在 used 中”的情况,代码专门处理了)
首先看如何计算hash的:
compute_hash(cls, token_ids: list[int], prefix: int = -1):其首先需要传入一个prefix,这是上一个block的hash,如果没有上一个block就传入-1,就不管,然后在计算hash的时候需要在这个prefix的基础上再加上各个token_id,进行计算。从而保证一个seq的hash命中的时候这个seq前面的block也是完全相同的
再看allocate相关的函数,主要负责为一个新序列分配 block 表,并尽可能复用已有的相同块:
can_allocate(self, seq: Sequence) -> bool:其判断依据是seq需要的num_blocks是否小于free_block_idsallocate(self, seq: Sequence):其遍历seq的所有block,如果当前这个block的
token_ids数量等于block_size,那么就说明是一个满的block,就通过compute_hash来计算该block的hash值,然后通过hash_to_block_id以及token_ids的比较来判断是否确实之前这个block已经存在了。如果cache未命中,那就取
self.free_block_ids[0]作为要分配出去的block_id,然后调用_allocate_block分配该block。_allocate_block实际做的事情也比较简单,就是调用block.reset()来重置该block,然后将其从free_block_ids中移除,并加入到used_block_ids中
如果cache命中,更新
seq.num_cached_tokens += self.block_size,然后将命中的block的ref_count+1
只要这是一个满的block,就对刚刚命中获取到的或未命中获取的block进行update,并且记录到
hash_to_block_id这个map中最后执行
seq.block_table.append(block_id)记录对应的block_id
再看deallocate相关的函数,主要负责释放序列占用的块(引用计数归零才回收):
deallocate(self, seq: Sequence)倒序遍历
seq.block_table,使得对应block.ref_count -= 1,如果这时block.ref_count == 0,那么就将其从used_block_ids中去除,然后添加到free_block_ids中处理完blocks后设置
seq.num_cached_tokens = 0以及seq.block_table.clear()
再看append相关函数,主要负责decode 阶段追加 token 时的块扩容与封存(形成可缓存 hash):
can_append(self, seq: Sequence) -> bool:其代码就是len(self.free_block_ids) >= (len(seq) % self.block_size == 1),为true的条件是目前seq的长度刚好是self.block_size整数倍+1,并且self.free_block_ids有大于等于一个空闲blockmay_append(self, seq: Sequence):按len(seq) % block_size分三种情况:== 1:刚进入新块断言 last_block.hash != -1:说明上一个块必须已经封存为满块并有 hash
分配一个新物理块,block_table.append(new_block_id)
新块 reset() 后 hash=-1,因为还没满
== 0:刚好填满一个块(封存)断言 last_block.hash == -1:未封存才能封存
取刚填满的最后一个逻辑块 token_ids
取前一个块的 hash 作为 prefix(如果存在)
计算新 hash,
last_block.update(h, token_ids)并写入 hash_to_block_id这一步使得“这个完整块”可被未来的请求复用(prefix cache)
其它:块内部追加(既没开新块、也没填满)
- 断言 last_block.hash == -1:未封存状态维持
Scheduler相关
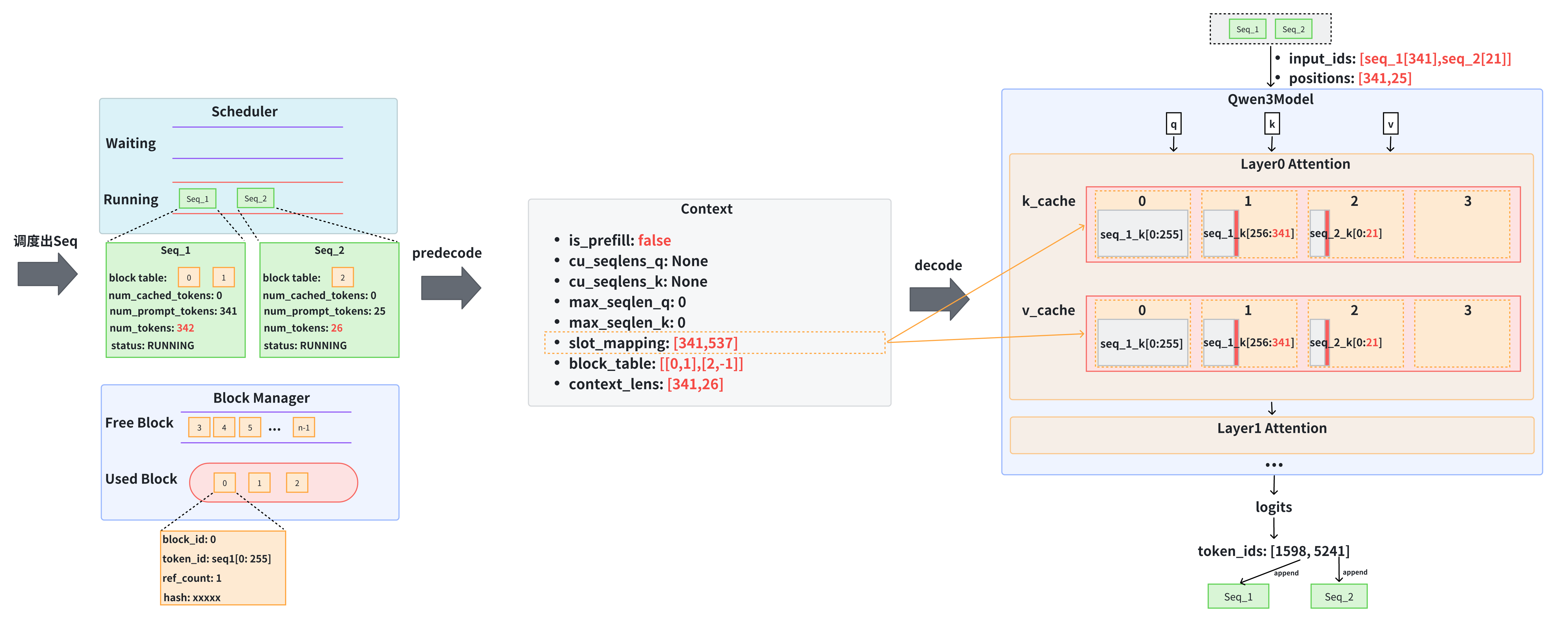
- Scheduler负责调度出当前需要处理哪些seq,其主要包含两个队列,一个队列是waiting队列,一个是正在处理的running队列,队列中的基本任务单元是seq
调度基本单元Sequence类
Sequence类的相关代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82from copy import copy
from enum import Enum, auto
from itertools import count
from nanovllm.sampling_params import SamplingParams
class SequenceStatus(Enum):
WAITING = auto()
RUNNING = auto()
FINISHED = auto()
class Sequence:
block_size = 256
counter = count()
def __init__(self, token_ids: list[int], sampling_params = SamplingParams()):
self.seq_id = next(Sequence.counter)
self.status = SequenceStatus.WAITING
self.token_ids = copy(token_ids)
self.last_token = token_ids[-1]
self.num_tokens = len(self.token_ids)
self.num_prompt_tokens = len(token_ids)
self.num_cached_tokens = 0
self.block_table = []
self.temperature = sampling_params.temperature
self.max_tokens = sampling_params.max_tokens
self.ignore_eos = sampling_params.ignore_eos
def __len__(self):
return self.num_tokens
def __getitem__(self, key):
return self.token_ids[key]
@property
def is_finished(self):
return self.status == SequenceStatus.FINISHED
@property
def num_completion_tokens(self):
return self.num_tokens - self.num_prompt_tokens
@property
def prompt_token_ids(self):
return self.token_ids[:self.num_prompt_tokens]
@property
def completion_token_ids(self):
return self.token_ids[self.num_prompt_tokens:]
@property
def num_cached_blocks(self):
return self.num_cached_tokens // self.block_size
@property
def num_blocks(self):
return (self.num_tokens + self.block_size - 1) // self.block_size
@property
def last_block_num_tokens(self):
return self.num_tokens - (self.num_blocks - 1) * self.block_size
def block(self, i):
assert 0 <= i < self.num_blocks
return self.token_ids[i*self.block_size: (i+1)*self.block_size]
def append_token(self, token_id: int):
self.token_ids.append(token_id)
self.last_token = token_id
self.num_tokens += 1
def __getstate__(self):
return (self.num_tokens, self.num_prompt_tokens, self.num_cached_tokens, self.block_table,
self.token_ids if self.num_completion_tokens == 0 else self.last_token)
def __setstate__(self, state):
self.num_tokens, self.num_prompt_tokens, self.num_cached_tokens, self.block_table = state[:-1]
if self.num_completion_tokens == 0:
self.token_ids = state[-1]
else:
self.last_token = state[-1]在状态流转方面其主要就是最开始的WAITING ,然后被调度上台运行后变为RUNNING态,如果在RUNNINF态被抢占,就会转回WAITING ,如果完成就变为FINISHED态
在初始化时会将状态标记为WAITING,然后初始化时tokens都会被记录为num_prompt_tokens,此外也会有token_ids 进行记录,此外初始化时会标记
num_cached_tokens = 0然后还有一些简单的函数,比较关键的有:
num_blocks(self):block的数量,直接使用(self.num_tokens + self.block_size - 1) // self.block_size向上取整获得last_block_num_tokens(self):最后一个block上的token数量,self.num_tokens - (self.num_blocks - 1) * self.block_sizeblock(self, i):block i上的tokens:self.token_ids[i*self.block_size: (i+1)*self.block_size]append_token(self, token_id: int):添加生成的token,添加时self.token_ids.append(token_id),self.last_token = token_id,self.last_token = token_id
Scheduler类
Scheduler类的代码如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71from collections import deque
from nanovllm.config import Config
from nanovllm.engine.sequence import Sequence, SequenceStatus
from nanovllm.engine.block_manager import BlockManager
class Scheduler:
def __init__(self, config: Config):
self.max_num_seqs = config.max_num_seqs
self.max_num_batched_tokens = config.max_num_batched_tokens
self.eos = config.eos
self.block_manager = BlockManager(config.num_kvcache_blocks, config.kvcache_block_size)
self.waiting: deque[Sequence] = deque()
self.running: deque[Sequence] = deque()
def is_finished(self):
return not self.waiting and not self.running
def add(self, seq: Sequence):
self.waiting.append(seq)
def schedule(self) -> tuple[list[Sequence], bool]:
# prefill
scheduled_seqs = []
num_seqs = 0
num_batched_tokens = 0
while self.waiting and num_seqs < self.max_num_seqs:
seq = self.waiting[0]
if num_batched_tokens + len(seq) > self.max_num_batched_tokens or not self.block_manager.can_allocate(seq):
break
num_seqs += 1
self.block_manager.allocate(seq)
num_batched_tokens += len(seq) - seq.num_cached_tokens
seq.status = SequenceStatus.RUNNING
self.waiting.popleft()
self.running.append(seq)
scheduled_seqs.append(seq)
if scheduled_seqs:
return scheduled_seqs, True
# decode
while self.running and num_seqs < self.max_num_seqs:
seq = self.running.popleft()
while not self.block_manager.can_append(seq):
if self.running:
self.preempt(self.running.pop())
else:
self.preempt(seq)
break
else:
num_seqs += 1
self.block_manager.may_append(seq)
scheduled_seqs.append(seq)
assert scheduled_seqs
self.running.extendleft(reversed(scheduled_seqs))
return scheduled_seqs, False
def preempt(self, seq: Sequence):
seq.status = SequenceStatus.WAITING
self.block_manager.deallocate(seq)
self.waiting.appendleft(seq)
def postprocess(self, seqs: list[Sequence], token_ids: list[int]) -> list[bool]:
for seq, token_id in zip(seqs, token_ids):
seq.append_token(token_id)
if (not seq.ignore_eos and token_id == self.eos) or seq.num_completion_tokens == seq.max_tokens:
seq.status = SequenceStatus.FINISHED
self.block_manager.deallocate(seq)
self.running.remove(seq)在初始化时,其初始化了block_manager,因为scheduler需要block_manager来判断当前还有多少空间可以用来做cache,从而调度出对应的请求。其还依据配置初始化了
max_num_seqs用来限制一次最多同时处理多少seq,还用了max_num_batched_tokens来限制了一次最多处理的token数量。其还用双端队列初deque始化了running和waiting队列其关键的功能函数有以下这些:
is_finished(self):判断是不是所有seq都处理完了add(self, seq: Sequence):添加新seq到waiting队列中preempt(self, seq: Sequence):被抢占的seq状态需要转回WAITING并加入到waiting队列的队头,然后使用block_manager释放seq占据的blockpostprocess(self, seqs: list[Sequence], token_ids: list[int]) -> list[bool]:每执行完一轮都会运行这个函数,目的是为各个seq添加最新生成的token,然后如果这个seq生成完了就将其状态转为FINISHED,然后block_manager释放seq占据的block,并且将其从running队列中删除schedule(self) -> tuple[list[Sequence], bool]:首先处理waiting队列的prefill请求,如果waiting队列不为空,并且没有超过scheduler自身的
self.max_num_seqs及max_num_batched_tokens限制以及block manager的限制,就从waiting队列的队头中不断取出seq放入到running队列中,然后为seq在block manager中分配block,并将seq放入到结果scheduled_seqs中如果没有取到prefill请求就尝试取出decode队列,如果running队列有请求,并且没有超过scheduler自身的
self.max_num_seqs限制以及block manager的限制就从running队列的队头不断取出seq,然后为seq在block manager中按需分配block,并将seq放入到结果scheduled_seqs中;如果超过了block manager的限制就尝试去抢占running队列中队尾的旧seq,如果没有旧seq可以抢占,就抢占自己,也就是把自己再放回waiting队列中。最后将这些scheduled_seqs再按序放入到running的队头,这样子保证下一轮调度时还是基本按照这一次的顺序继续处理,从而高效利用cache
Attention中的KV Cache
Nano-vLLM中的Attention的相关代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73import torch
from torch import nn
import triton
import triton.language as tl
from flash_attn import flash_attn_varlen_func, flash_attn_with_kvcache
from nanovllm.utils.context import get_context
@triton.jit
def store_kvcache_kernel(
key_ptr,
key_stride,
value_ptr,
value_stride,
k_cache_ptr,
v_cache_ptr,
slot_mapping_ptr,
D: tl.constexpr,
):
idx = tl.program_id(0)
slot = tl.load(slot_mapping_ptr + idx)
if slot == -1: return
key_offsets = idx * key_stride + tl.arange(0, D)
value_offsets = idx * value_stride + tl.arange(0, D)
key = tl.load(key_ptr + key_offsets)
value = tl.load(value_ptr + value_offsets)
cache_offsets = slot * D + tl.arange(0, D)
tl.store(k_cache_ptr + cache_offsets, key)
tl.store(v_cache_ptr + cache_offsets, value)
def store_kvcache(key: torch.Tensor, value: torch.Tensor, k_cache: torch.Tensor, v_cache: torch.Tensor, slot_mapping: torch.Tensor):
N, num_heads, head_dim = key.shape
D = num_heads * head_dim
assert key.stride(-1) == 1 and value.stride(-1) == 1
assert key.stride(1) == head_dim and value.stride(1) == head_dim
assert k_cache.stride(1) == D and v_cache.stride(1) == D
assert slot_mapping.numel() == N
store_kvcache_kernel[(N,)](key, key.stride(0), value, value.stride(0), k_cache, v_cache, slot_mapping, D)
class Attention(nn.Module):
def __init__(
self,
num_heads,
head_dim,
scale,
num_kv_heads,
):
super().__init__()
self.num_heads = num_heads
self.head_dim = head_dim
self.scale = scale
self.num_kv_heads = num_kv_heads
self.k_cache = self.v_cache = torch.tensor([])
def forward(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor):
context = get_context()
k_cache, v_cache = self.k_cache, self.v_cache
if k_cache.numel() and v_cache.numel():
store_kvcache(k, v, k_cache, v_cache, context.slot_mapping)
if context.is_prefill:
if context.block_tables is not None: # prefix cache
k, v = k_cache, v_cache
o = flash_attn_varlen_func(q, k, v,
max_seqlen_q=context.max_seqlen_q, cu_seqlens_q=context.cu_seqlens_q,
max_seqlen_k=context.max_seqlen_k, cu_seqlens_k=context.cu_seqlens_k,
softmax_scale=self.scale, causal=True, block_table=context.block_tables)
else: # decode
o = flash_attn_with_kvcache(q.unsqueeze(1), k_cache, v_cache,
cache_seqlens=context.context_lens, block_table=context.block_tables,
softmax_scale=self.scale, causal=True)
return o注意上述的Attention初始化的时候k_cache与v_cache都是空,其实际的初始化是在
ModelRunner初始化时的allocate_kv_cache函数中,代码如下所示1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def allocate_kv_cache(self):
config = self.config
hf_config = config.hf_config
free, total = torch.cuda.mem_get_info()
used = total - free
peak = torch.cuda.memory_stats()["allocated_bytes.all.peak"]
current = torch.cuda.memory_stats()["allocated_bytes.all.current"]
num_kv_heads = hf_config.num_key_value_heads // self.world_size
head_dim = getattr(hf_config, "head_dim", hf_config.hidden_size // hf_config.num_attention_heads)
block_bytes = 2 * hf_config.num_hidden_layers * self.block_size * num_kv_heads * head_dim * hf_config.torch_dtype.itemsize
config.num_kvcache_blocks = int(total * config.gpu_memory_utilization - used - peak + current) // block_bytes
assert config.num_kvcache_blocks > 0
self.kv_cache = torch.empty(2, hf_config.num_hidden_layers, config.num_kvcache_blocks, self.block_size, num_kv_heads, head_dim)
layer_id = 0
for module in self.model.modules():
if hasattr(module, "k_cache") and hasattr(module, "v_cache"):
module.k_cache = self.kv_cache[0, layer_id]
module.v_cache = self.kv_cache[1, layer_id]
layer_id += 1其首先计算了在TP并行下各个worker的head数量
然后其初始化了kv_cache tensor,其形状为:
[2, num_layers, num_kvcache_blocks, block_size, num_kv_heads_per_rank, head_dim],其中2表示 K 和 V 两份,从这里也能看出一个block中的一个元素指的是一个Attention layer中的一个token的所有head的K或V对应的tensor,即大小是num_kv_heads_per_rank×head_dim然后回将对应的kv cache绑定给每一层的k_cache与v_cache上
在Attention的Forward中,只要经过上述的
allocate_kv_cache,就会进入到store_kvcache(k, v, k_cache, v_cache, context.slot_mapping)中,其中slot_mapping是一个一维Tensor,其记录了每个k或v应该具体放置的相对位置,其数量与当前的k的数量N完全一致,故store_kvcache中,其会启用N个warp去根据slot_mapping提供的各个k、v元素需要存储的相对位置与目前计算出来的k、v存储在k_cache与v_cache中然后如果是prefill阶段,就使用flash_attn_varlen_func计算结果
如果是decode阶段,就使用flash_attn_with_kvcache计算结果
具体在计算时如何使用kv cache这里都被封装了起来,但是整体而言其行为是可预见的,因为
context.block_tables中记录了各个seq目前已经生成k、v所在的block id,所以获取一个seq前面的k与v的时候直接依据对应的block id去kv cache中按序读取对应的数据即可
ModelRunner相关
Prefill
ModelRunner的
prepare_prefill代码如下所示1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38def prepare_prefill(self, seqs: list[Sequence]):
input_ids = []
positions = []
cu_seqlens_q = [0]
cu_seqlens_k = [0]
max_seqlen_q = 0
max_seqlen_k = 0
slot_mapping = []
block_tables = None
for seq in seqs:
seqlen = len(seq)
input_ids.extend(seq[seq.num_cached_tokens:])
positions.extend(list(range(seq.num_cached_tokens, seqlen)))
seqlen_q = seqlen - seq.num_cached_tokens
seqlen_k = seqlen
cu_seqlens_q.append(cu_seqlens_q[-1] + seqlen_q)
cu_seqlens_k.append(cu_seqlens_k[-1] + seqlen_k)
max_seqlen_q = max(seqlen_q, max_seqlen_q)
max_seqlen_k = max(seqlen_k, max_seqlen_k)
if not seq.block_table: # warmup
continue
for i in range(seq.num_cached_blocks, seq.num_blocks):
start = seq.block_table[i] * self.block_size
if i != seq.num_blocks - 1:
end = start + self.block_size
else:
end = start + seq.last_block_num_tokens
slot_mapping.extend(list(range(start, end)))
if cu_seqlens_k[-1] > cu_seqlens_q[-1]: # prefix cache
block_tables = self.prepare_block_tables(seqs)
input_ids = torch.tensor(input_ids, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
positions = torch.tensor(positions, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
cu_seqlens_q = torch.tensor(cu_seqlens_q, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
cu_seqlens_k = torch.tensor(cu_seqlens_k, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
slot_mapping = torch.tensor(slot_mapping, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
set_context(True, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k, slot_mapping, None, block_tables)
return input_ids, positions其会遍历未缓存的
range(seq.num_cached_blocks, seq.num_blocks),第i个block的起始位置就是seq.block_table[i] * self.block_size,也就是对应block_id * self.block_size,第i个block的结束位置会与是不是这个seq的最后一个block有关,如果不是那么就是满的block,那么就是start + self.block_size,否则就是start + seq.last_block_num_tokens,最终会将其存储在slot_mapping中,slot_mapping的格式就是[block_1_start_idx, block_1_start_idx+1, ..., block_1_end_idx-1,block_2_start_idx, block_2_start_idx+1, ..., block_2_end_idx-1,...]如果
cu_seqlens_k[-1] > cu_seqlens_q[-1]那么就说明有命中block缓存的token,需要专门执行prepare_block_tables,这是为了后续给flash attention使用block tableprepare_block_tables的代码如下所示
1
2
3
4
5def prepare_block_tables(self, seqs: list[Sequence]):
max_len = max(len(seq.block_table) for seq in seqs)
block_tables = [seq.block_table + [-1] * (max_len - len(seq.block_table)) for seq in seqs]
block_tables = torch.tensor(block_tables, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
return block_tables- 其得到目前这批token的最长block_table,对应没达到最长的block_table,将其在后面补-1,最终得到一个GPU中的table,形状为(len(seqs), max_len_block_table)
这些变量都会存储在context中等待后续调用
Decode
ModelRunner的
prepare_decode代码如下所示1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def prepare_decode(self, seqs: list[Sequence]):
input_ids = []
positions = []
slot_mapping = []
context_lens = []
for seq in seqs:
input_ids.append(seq.last_token)
positions.append(len(seq) - 1)
context_lens.append(len(seq))
slot_mapping.append(seq.block_table[-1] * self.block_size + seq.last_block_num_tokens - 1)
input_ids = torch.tensor(input_ids, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
positions = torch.tensor(positions, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
slot_mapping = torch.tensor(slot_mapping, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
context_lens = torch.tensor(context_lens, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
block_tables = self.prepare_block_tables(seqs)
set_context(False, slot_mapping=slot_mapping, context_lens=context_lens, block_tables=block_tables)
return input_ids, positions在decode中,其首先需要将各seq上一步生成的新token也就是
seq.last_token处理好,也就是将这个token append到input_ids,然后再将其位置也放入到positions,再记录一下当前seq的长度,以给后续attention计算时访问对应长度的kv cache,然后再在slot_mapping中记录这个新生成的token在后续计算出k v后需要放置在kv cache中的位置seq.block_table[-1] * self.block_size + seq.last_block_num_tokens - 1,注意这里的seq.last_block_num_tokens就包括了新生成的token然后将计算的结果存储在context中,并且注意同样会使用
prepare_block_tables来将block_tables向量化
计算结果
在
prepare_prefill或prepare_decode后会通过run_model来调用model的前向传播并计算logits1
2
3def run_model(self, input_ids: torch.Tensor, positions: torch.Tensor, is_prefill: bool):
if is_prefill or self.enforce_eager or input_ids.size(0) > 512:
return self.model.compute_logits(self.model(input_ids, positions))- 其中就涉及到上述说的用KV Cache计算attention,最终得到的logits就是下一个token的概率分布
在得到
logits后需要借助Sampler进行采样,从而得到最终输出的token实际调用的代码为:
token_ids = self.sampler(logits, temperatures).tolist() if self.rank == 0 else NoneSampler定义的代码如下:
1
2
3
4
5
6
7
8
9
10
11class Sampler(nn.Module):
def __init__(self):
super().__init__()
@torch.compile
def forward(self, logits: torch.Tensor, temperatures: torch.Tensor):
logits = logits.float().div_(temperatures.unsqueeze(dim=1))
probs = torch.softmax(logits, dim=-1)
sample_tokens = probs.div_(torch.empty_like(probs).exponential_(1).clamp_min_(1e-10)).argmax(dim=-1)
return sample_tokens其首先除以
temperatures,然后通过softmax得到概率分布用Gumbel-Max Trick从 softmax 分布中采样一个 token,其实现等价于按概率采样,但是更加适合GPU进行并行化
总结
下面总结绘制了2个流程图:
- 从调度到prefill结果的过程如下所示:
- prefill结束后进行decode的过程如下所示: