CS336-Assignment5-Alignment and Reasoning RL 作业总结
前言
原作业链接:https://github.com/stanford-cs336/assignment5-alignment
自己写的版本在(注意只写了sft和grpo,没有写Expert Iteration for MATH):https://github.com/slipegg/assignment5-alignment
主要参考资料:
数据集:由于课程作业里提到的数据集是私有数据集,所以没法直接用,这里用的是一个老哥用gptoss自制的数据集https://huggingface.co/datasets/garg-aayush/sft-cs336-assign5-datasets
作业概述
首先是用原始的Qwen2.5-Math-1.5B在数据集问题上进行了Zero-Shot测试:
- 这里的模板比较有意思,模板如下:
1
2
3A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.
User: {question}
Assistant: <think>然后将问题放入到模板中,再放入到vllm中得到模型输出结果,再使用提供的专用的答案判决器来判断格式与答案的正确,其判决主要就是先正则匹配<answer> xxx </answer>中的内容,然后再对匹配出的内容与ground truth进行比较,从而使得0.5与1/2这种表达格式都能够判断为相同。
测试下来结果如下,其实整体还是可以的,可以看到其思考的过程,格式也基本都是一些小错误:
格式正确率:41.8%
答案正确率:17.0%
格式+答案正确率:17.0%
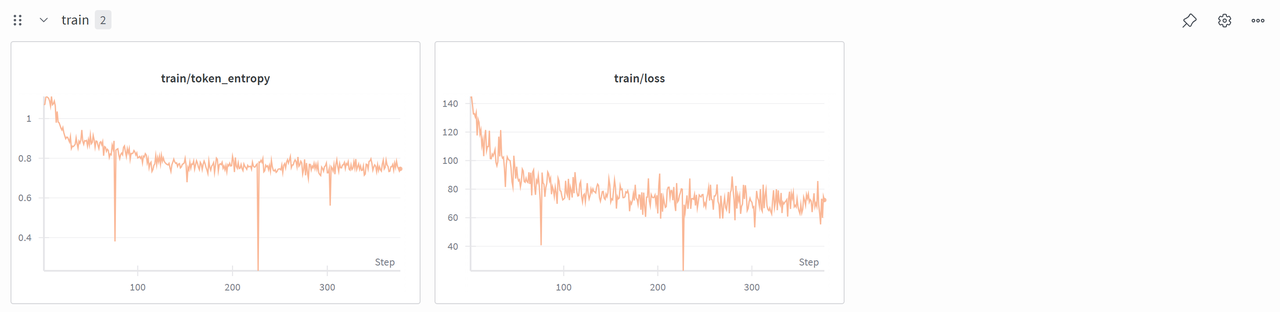
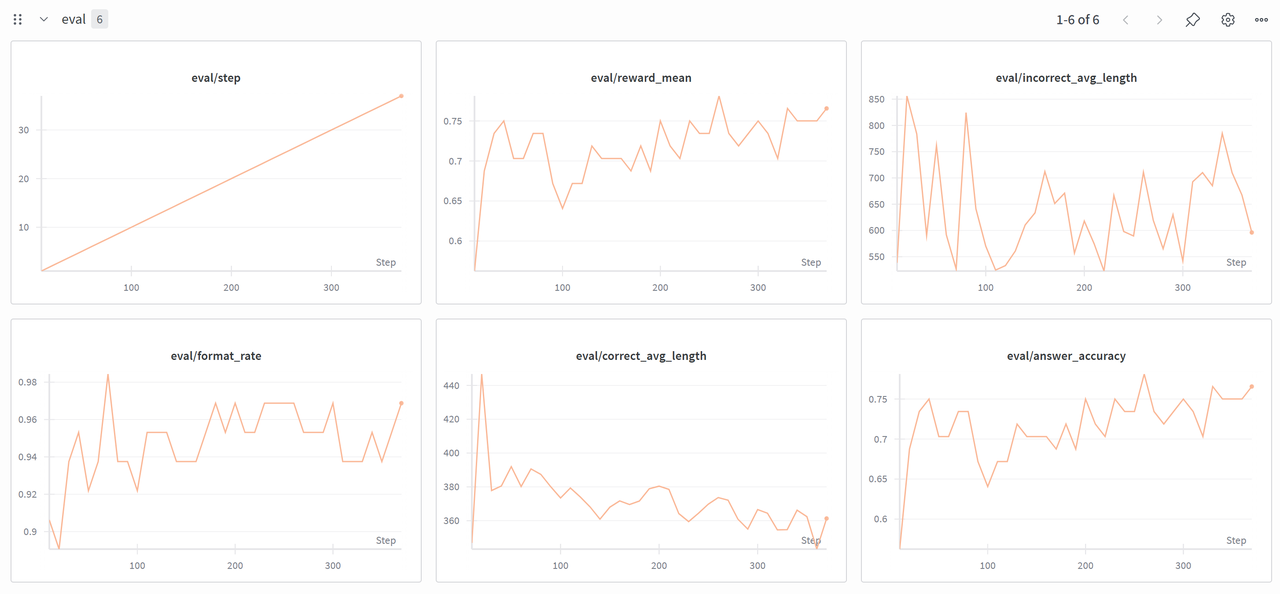
然后对Qwen2.5-Math-1.5B进行sft:
这里数据集在制作时使用了gpt-oss-120b来生成了推理轨迹,这里主要的做法是使用已有的推理轨迹像预训练一样进行训练来让模型学会这种高阶模型的思考路径。
其整体训练流程也比较经典,就是读取推理轨迹数据集,然后向右移动一位作为label,目标是最大化模型输出label的概率。
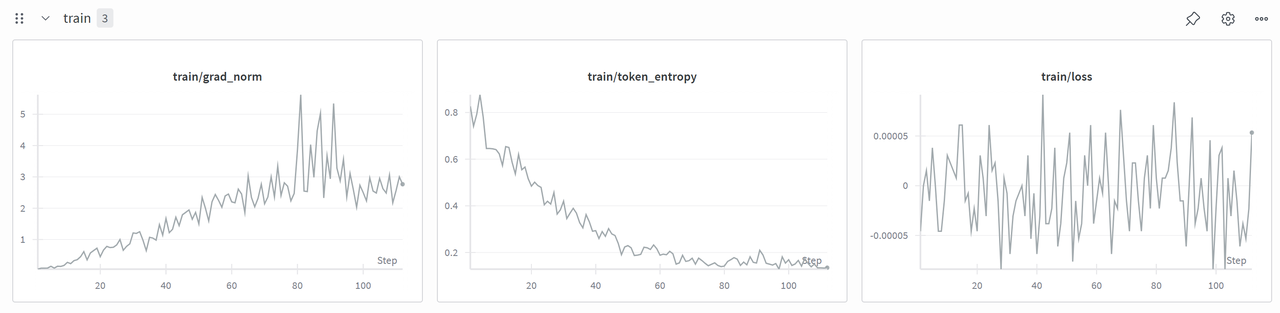
运行结果如下,可以看到其最终的格式正确率可以提升到95%往上,其格式+答案正确率可以提升到75%以上,还是有很大提升的。
然后对Qwen2.5-Math-1.5B使用grpo进行训练:
使用强化学习进行训练不再需要更高深的模型或人类的思考轨迹,而是让模型进行自我探索,然后再依据探索的结果给予其相应的奖励。
在grpo中,每个问题会使用vllm推理得到一组答案,然后使用答案判决器判断每组内每个输出的得分,一个组内的得分会进行归一化,即
(reward_by_group - reward_mean) / (reward_std + advantage_eps),从而得到advantage,注意这里原始的grpo论文是除以了reward_std,但是后面有论文指出不应该除以reward_std,因为除以reward_std会导致模型倾向于输出得分类似的答案。而后依据
advantage,我们需要用actor再次依据prompt进行输出,从而得到重要性采样需要的概率,依据以上这些内容我们就可以计算出loss,其loss实际表示的是要更新的新模型与旧模型之间的概率差距,其整体训练倾向是使得模型输出正advantage的概率越来越高,输出负advantage的概率越来越低。训练过程中比较不同的地方在于推理也需要加入到训练过程中来,从而也就导致了模型权重需要在推理与训练框架中流动。
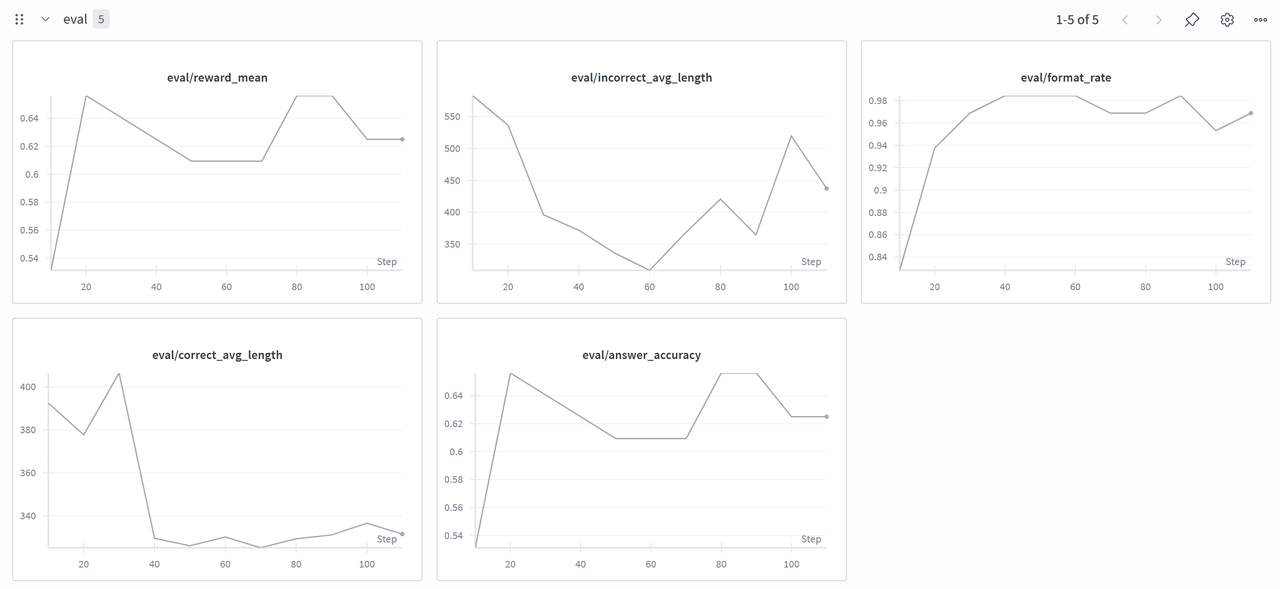
最终训练结果如下所示,注意因为显存不足,所以训了140步左右就memory out了,但是看评测结果最终格式正确率快速上升到了98%,格式+答案正确率来到了62%往上。