【Verl源码分析(四)】Verl中使用sandbox进行训练
在强化学习中, 当reward依赖“运行结果”而不是“文本相似度或打分模型”时,就需要sandbox来运行模型rollout的结果进行判别。最典型的场景就是在强化学习场景中加入生成代码的任务,或者是更复杂的有关工具调用的训练场景。
Verl目前已支持将fusin sandbox加入到训练流程中,故本文随着Verl的官方示例来对其一探究竟,其主要是在Eurus-2-RL-Data 数据集上利用Fusion sandbox进行数学与代码能力的增强。
注意查看的是0.4.1.x版本的Verl代码:https://github.com/verl-project/verl/tree/v0.4.1.x
Fusion sandbox简介
Fusin sandbox是字节开发的适用于LLM的多功能code sandbox。其可以通过拉取并运行官方镜像来快速启动一个sandbox环境。其主要包含两个功能:
运行代码:可以向运行的端口,如http://localhost:8080/run_code提交代码,sandbox将会编译并运行这部分代码,然后将运行结果返回。这是最基础的通用能力。
数据集运行判别:其在运行代码能力的基础上进一步封装,将一些典型的代码数据集进行封装,支持直接提交某个数据集某个问题的模型执行结果,然后sandbox自行提取出代码并编译运行,然后将运行结果与这个问题应有的代码进行对比并返回判别结果。此外也支持自行拓展支持的数据集。
在verl中使用到的是fusion sandbox运行代码的功能,关于与数据集中的ground truth的对比就自行实现了,这样更加灵活。
Eurus-2-RL-Data数据集简介
Eurus-2-RL-Data数据集包含了45.5 万道数学题和2.6 万道编程题,具体介绍如下:
- 数学题:其选用的是NuminaMath-CoT题库。题目涵盖了从中国高中数学到国际数学奥林匹克竞赛的各类题型,示例如下,其计算结果要求用latex格式。示例如下:
1 | |
- 编程题:其主要从APPS、CodeContests、TACO和Codeforces 等网站获取题目。题目的难度主要与编程竞赛级别相当。数据集中的ground truth不再是一串结果数字,而是多个输入以及对应预期的输出结果。示例如下:
1 | |
Verl使用sandbox计算奖励的运行示例
关于环境配置可以见之前的博客:https://slipegg.github.io/2026/01/29/Verl-Install-Demo/
我这里使用的是4个4090,所以跑不起来verl官方给的示例脚本examples/ppo_trainer/run_deepseek7b_llm_sandbox_fusion.sh,所以自己调整了一下,运行脚本如下,主要是调整了batch的大小,并且将模型改为了更小的Qwen2.5-0.5B-Instruct。
1 | |
运行结果如下所示,可以正常迭代:
Verl使用sandbox计算奖励的运行流程
这里专门看需要使用sandbox的代码题的处理。其整体处理的流程还是类似的,先从数据集中获取到一批数据,然后rollout角色针对这一批问题进行推理得到答案,对于代码问题就是生成对应的代码,然后进行reward计算,为了验证生成代码的准确性,就需要将代码放入sandbox中编译运行,并得到运行数据集中的输入后得到的输出,将其与数据集中的预期输出进行对比,从而得到reward。然后再依据算法按需计算advantage等,最后进行模型的更新迭代。
这里主要关注在reward计算过程中调用sandbox的一些细节,尤其是其中如何进行任务编排。
奖励函数初始化
在初始化时,需要初始化reward_fn与val_reward_fn。在本示例中,依据配置reward_model.reward_manager=prime加载的是PrimeRewardManager,然后还依据reward_model.sandbox_fusion.max_concurrent=16这一配置设置了全局sandbox api访问并发控制信号量允许的并发限制是16,然后将这一全局并发控制信号传递给reward计算函数,然后再传入到PrimeRewardManager。
1 | |
奖励函数计算
- 在训练流程中,当从
train_dataloader取出一个batch的数据,并且rollout角色对其进行推理后就会调用reward manager(PrimeRewardManager)进行奖励计算。奖励计算的整体流程如下图所示。
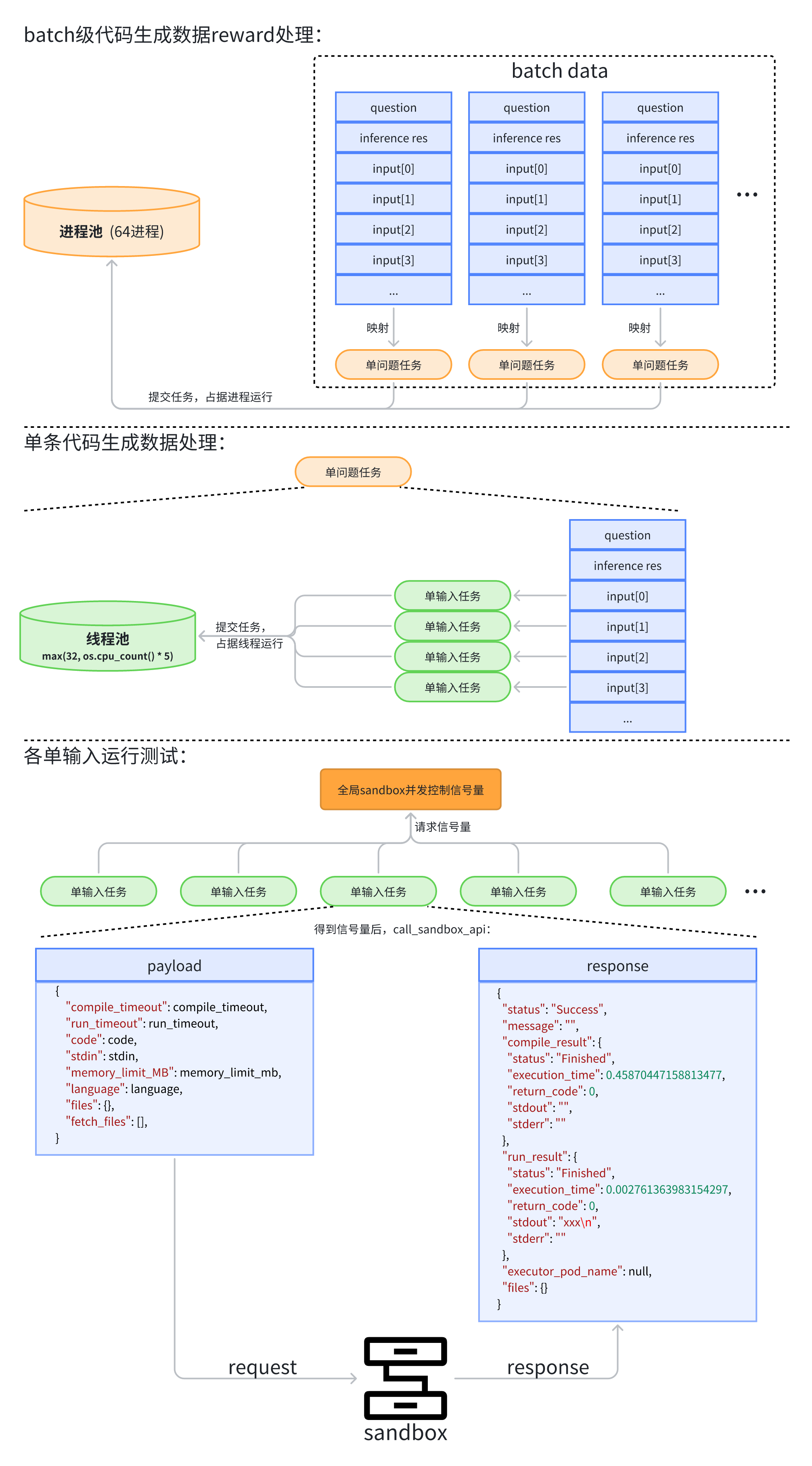
这里采用的
PrimeRewardManager内部在计算时,首先默认会生成一个包含64进程的进程池,然后batch中的每个问题对应的rollout结果都会组成为一个单问题任务,然后提交到进程池中等待进程处理,注意进程池中无空闲进程时任务会排队等待。每个进程对单问题任务处理时会先生成一个线程池,线程池的数量是
max(32, os.cpu_count() * 5),因为需要测试各个输入下的结果,所以这里是给每个问题都专门生成了一个单输入任务,提交后让各线程去处理。
这里有一个明显的优化点:虽然都是同一份代码,但是每个输入都会去重新提交给sandbox一遍,这导致多次重复的代码传递以及编译,实际应该让sandbox考虑支持一次性提交多次输入,以提高效率。
每个单输入任务在处理时,都会先进行数据处理,然后在请求sandbox api时会向全局并发控制信号发起请求,只有获得允许后才会去发起请求,注意这个信息量控制是全局的,其控制了全局最多同时会向sandbox发起多少请求。
在发起sandbox请求时,其首先会生成一个payload,然后将其传递给sandbox进行处理,然后再返回response。