【论文阅读】Search-R1:Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
背景
大语言模型虽然已经具备很强的推理能力,但一旦问题依赖外部知识、最新信息或多跳检索,单靠参数记忆往往不够。常见做法有两类:
RAG,先检索再生成,但RAG 的检索往往是一次性的,不能处理多跳检索;
把搜索引擎当作工具,让模型边想边查。目前这类方法主要依赖prompt注入或者通过sft来增强。其问题在于模型通常并没有在训练中真正学会“如何搜索”。
于是作者提出 Search-R1:把搜索引擎直接放进强化学习环境里,让模型在推理过程中自主决定何时搜、搜什么、如何结合搜索结果来继续推理,最后再将“推理 + 搜索 + 再推理”作为一个完整轨迹来训练。
方法思路
总体流程
整个流程可以概括成下面几步:
输入一个问题后,模型先在
<think>...</think>中进行思考。如果觉得缺少信息,就生成一个
<search>...</search>查询。系统检测到搜索标记后,调用搜索引擎,返回结果,并包装成
<information>...</information>插入上下文。模型继续基于已有推理和新检索内容往下生成。
当模型认为信息足够时,在
<answer>...</answer>中给出最终答案。
这种设计的重点在于:搜索不是固定前置步骤,而是嵌入在推理过程中。模型可以边想边搜,多轮迭代。
下图对其PPO训练和GRPO训练两类流程进行了说明:
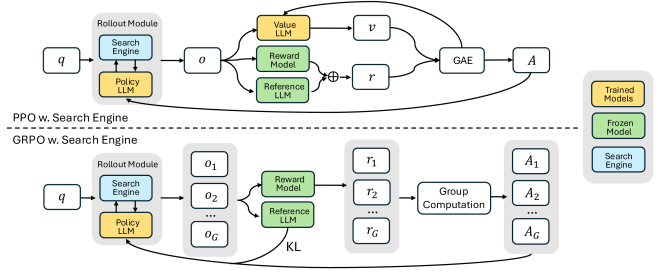
Rollout中的多轮搜索调用
文把搜索引擎视为环境的一部分,在 rollout 时允许模型进行多轮交互。模型每次先生成一段当前 action,如果匹配发现生成了 </search>,就解析出查询词并执行检索,然后将检索的内容追加到结果中,继续推理,如有需要还可以继续search。
为了避免无限search,其还设置了一个最大 action budget这个机制使得 Search-R1 能处理需要分步定位信息、逐步验证结论的复杂问答任务,如果action超过了指定轮数就会直接返回生成的结果。

RL训练设置
强化学习目标函数
论文把目标写成:在给定输入 $x$ 和搜索引擎 $R$ 的条件下,最大化模型生成轨迹的期望奖励,同时加入与参考模型之间的 KL 正则,都是一些经典做法。
- 对于PPO训练,其公式为:
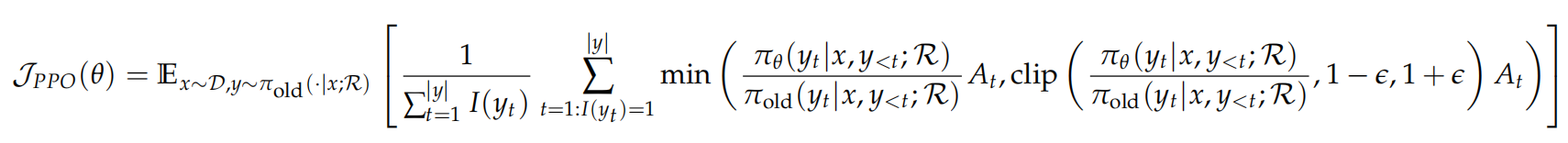
- 对于GRPO训练,其公式为:
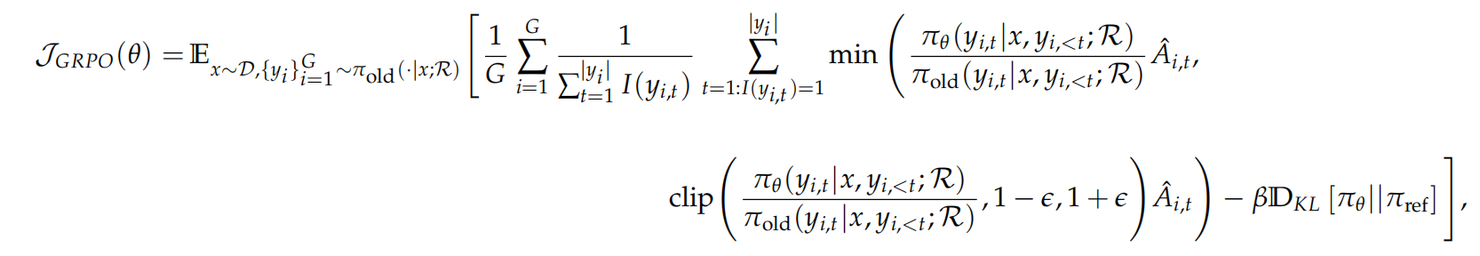
训练Prompt模板
其训练时使用的Prompt模板如下:

奖励模型
只用了结果奖励,对比结果是否正确,没有用过程奖励。虽然这样比较朴素但确实能训起来。
实验效果
实验配置
在 7 个问答数据集上评测,覆盖一般问答和多跳问答两类任务:
General QA:NQ、TriviaQA、PopQA
Multi-Hop QA:HotpotQA、2WikiMultiHopQA、Musique、Bamboogle
基础模型:
Qwen2.5-3B(Base / Instruct)
Qwen2.5-7B(Base / Instruct)
对比方法:
无检索的推理:Direct Inference、CoT
基于检索的推理:RAG、IRCoT、Search-o1
基于微调的方式方法:SFT、另一种R1方法、Rejection Sampling
为了保证公平,论文统一使用:
2018 Wikipedia 作为知识库
top-3 passages 作为默认检索数
NQ + HotpotQA 合并训练集
精确匹配作为评测指标
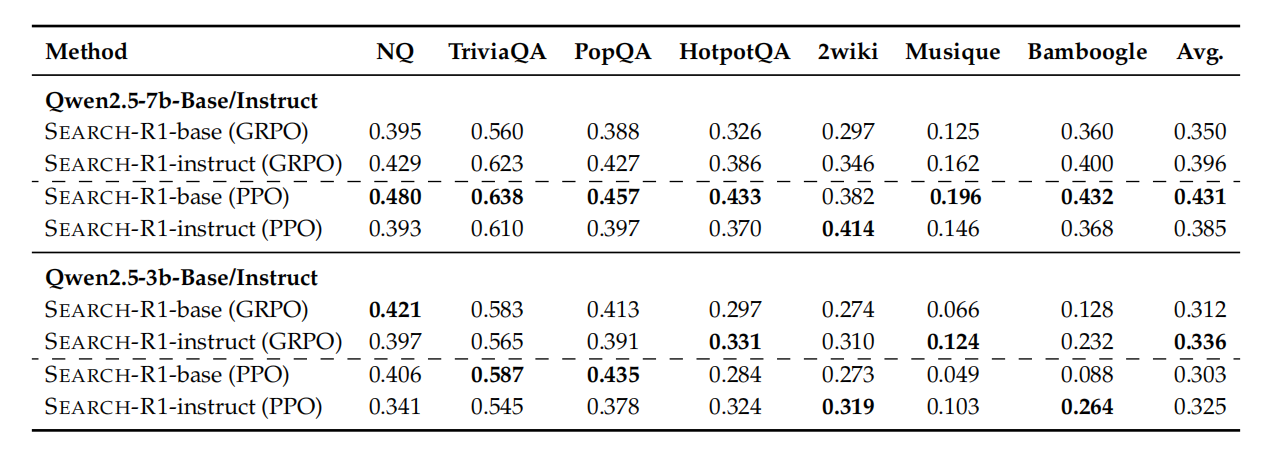
实验结果
整体结果很强,Search-R1 在大多数设置下都优于基线。
下面是PPO的结果:
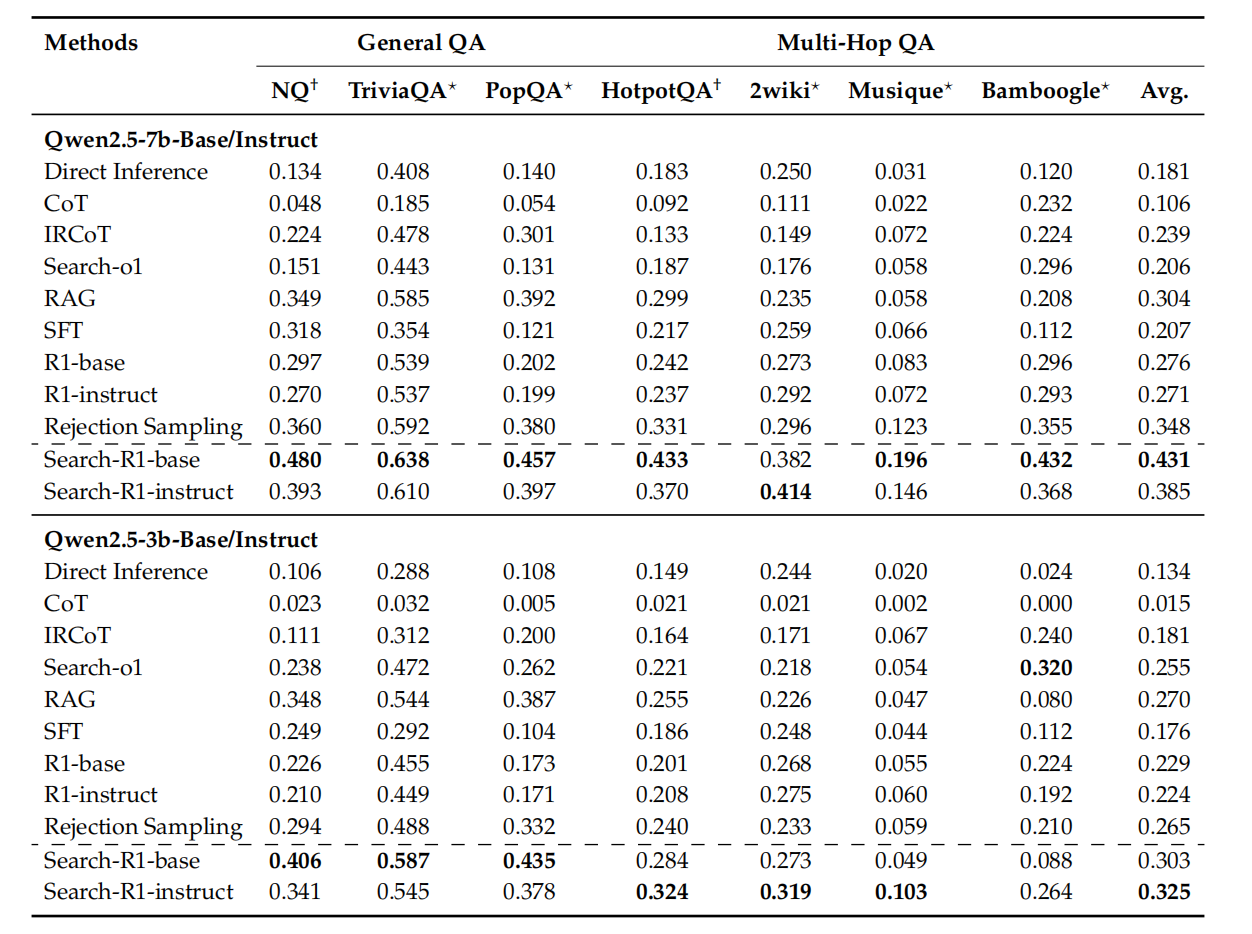
下面是PPO与GRPO对比的结果,PPO明显更强一些:
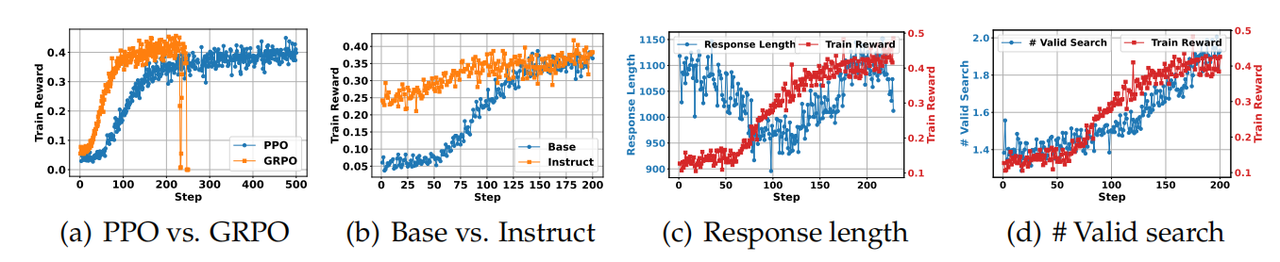
下图是训练的一些细节,可以看到GRPO收敛的更快,但最终奖励差不多。
总结
个人认为主要贡献是跑通了使用强化学习来进行search调用增强的一整个流程,整体的设计并没有说很惊艳的部分,但是有些细节确实是值得注意的,并且也确实是跑出来效果了,RL有时真是力大砖飞。
看这篇论文目前谷歌学术上的引用数已经到了740了,我认为同期应该有很多人在做类似的事情,不过这篇应该是最快且效果最好的那一批,并且其开源了代码也是进一步扩大了其影响力。