【论文阅读】SWE-bench Goes Live!
背景
这篇论文是 GLM-5 中提到的他们构建 Software Engineering (SWE) Environments 时使用的自动化方法。GLM-5 论文中称他们使用该方法在上千个仓库上构建了超过 10k 个可验证环境,横跨了 Python、Java、Go、C、CPP 等多种语言,故拿来研读了一下。
该论文指出,现有的 SWE 数据集存在数据陈旧、代码库覆盖有限、高度依赖人工操作难以有效拓展的问题,故他们提出了 RepoLaunch 流程,依赖 Agent 来全自动构建基准测试环境,并整理出了 SWE-bench-Live 数据集(并承诺后续每月更新),并进一步使用该数据集对各代理框架进行了评测。
方法思路
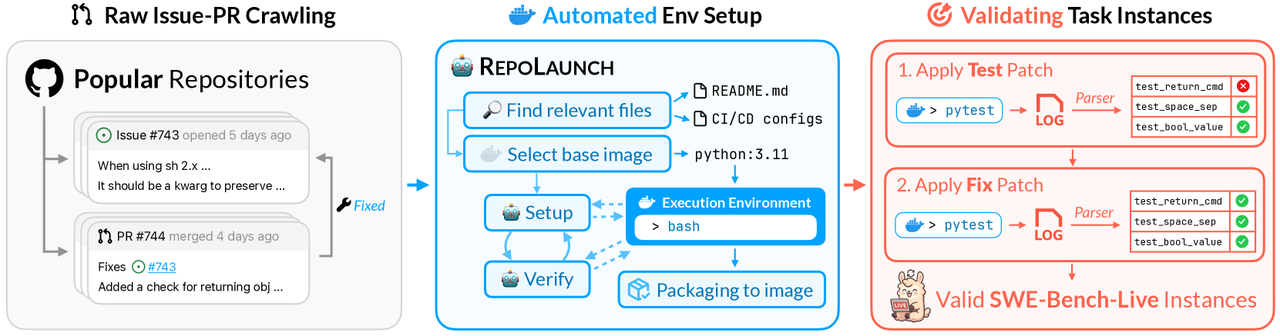
整体构建的流程如上图所示:
爬取了具有开源许可、主要语言为 Python、star 超过 1k、Issue 与 PR 与 fork 都超过 200 个仓库,并从中提取出 Issue 与 PR 对
以构建一个可测试的 Docker 环境为目标,走 RepoLaunch 流程:
确定基础镜像:通过读取 README.md、CI/CD configs 获得使用什么容器镜像
设置执行环境:运行容器获得一个持久化的 bash 会话,Agent 与该 bash 会话交互,Agent 通过 ReAct 以及联网搜索的能力来调整环境
验证执行环境:另起一个 Agent 在环境中运行测试命令,如果测试不通过,就返回上一步继续调整;如果验证成功就认为环境搭建完毕
这里通过设置 pip 中各个库的最新版本为提 Issue 时的库的最新版本来减少版本不兼容问题
- 镜像提交:将容器作为一个 Docker 镜像进行提交
验证问题实例是否有效:
在应用实际 PR 补丁前后都对测试文件进行测试,并且设计了特定框架(例如 tox、pytest)的解析器,以便可靠地解析测试输出,最终得到各个测试项的结果,按照测试项前后是否都成功划分为 FAIL_TO_PASS、PASS_TO_PASS 两类转换
一个问题实例必须至少包含一个使得测试 FAIL_TO_PASS 转换,才能证明这个 PR 也就是这个测试项确实有效,进一步才纳入到数据集中
数据集
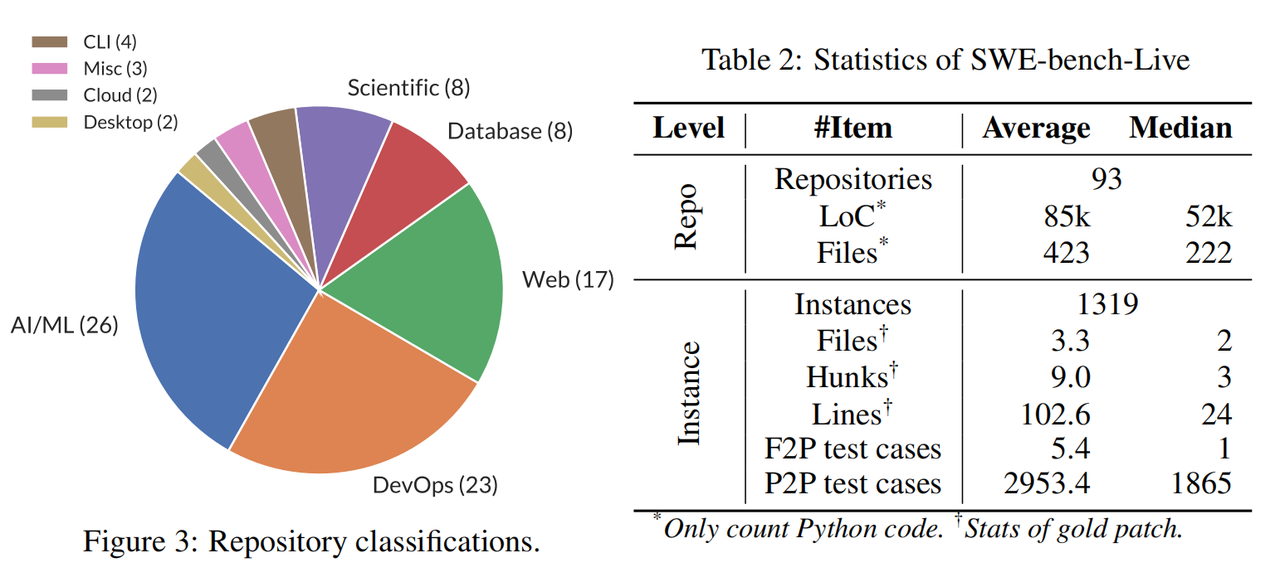
- 最终收集到的数据集情况如下所示:
- 实例级 Docker 镜像托管在 DockerHub 上(https://hub.docker.com/u/starryzhang),名称为:
1 | |
具体评测工程实现如下所示:
获取到修改内容 patch,可以是模型或 Agent 预测出的,也可以是数据集当时采集出来的标准答案
启动题目的容器实例,将测试文件的 patch 应用上去,再应用修改内容 patch
运行数据集中设定的测试命令并获取测试结果
最终解析测试结果,因为数据集中已经记录了 PASS_TO_PASS 以及 FAIL_TO_PASS 的测试样例有哪些,所以只需要记录新的测试中得到这两类测试样例中成功与失败运行的个数,然后组合信息返回 report
1 | |
实验
论文选择了三个代表性的代理框架(Agents)和四种最新的大型语言模型(LLMs)进行评估。
代理框架(Agents):
OpenHands:一个通用的编码代理,与 CodeAct 代理结合使用
SWE-Agent:专门为问题解决任务设计的代理
Agentless:一个轻量级的代理,专注于问题定位和补丁生成
大型语言模型(LLMs):
- GPT-4o
- GPT-4.1
- Claude 3.7 Sonnet
- DeepSeek V3
主要评估指标:
- **Resolved Rate (%)**:成功解决的问题比例
- **Patch Apply Rate (%)**:生成的补丁能够成功应用到代码库的比例
- **Localization Success Rate (%)**:生成的补丁修改的文件与黄金补丁匹配的比例
- 实验结果如下:
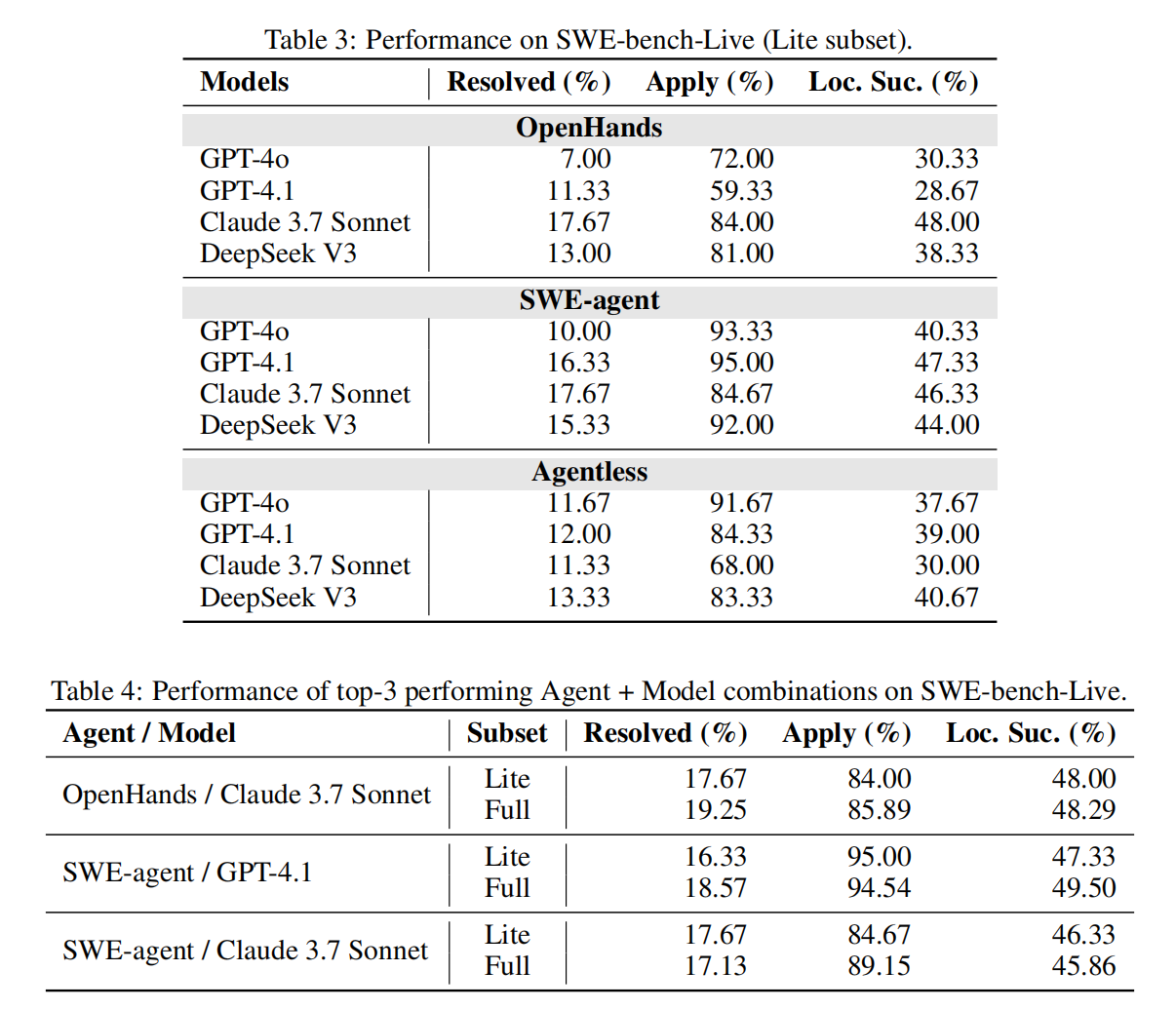

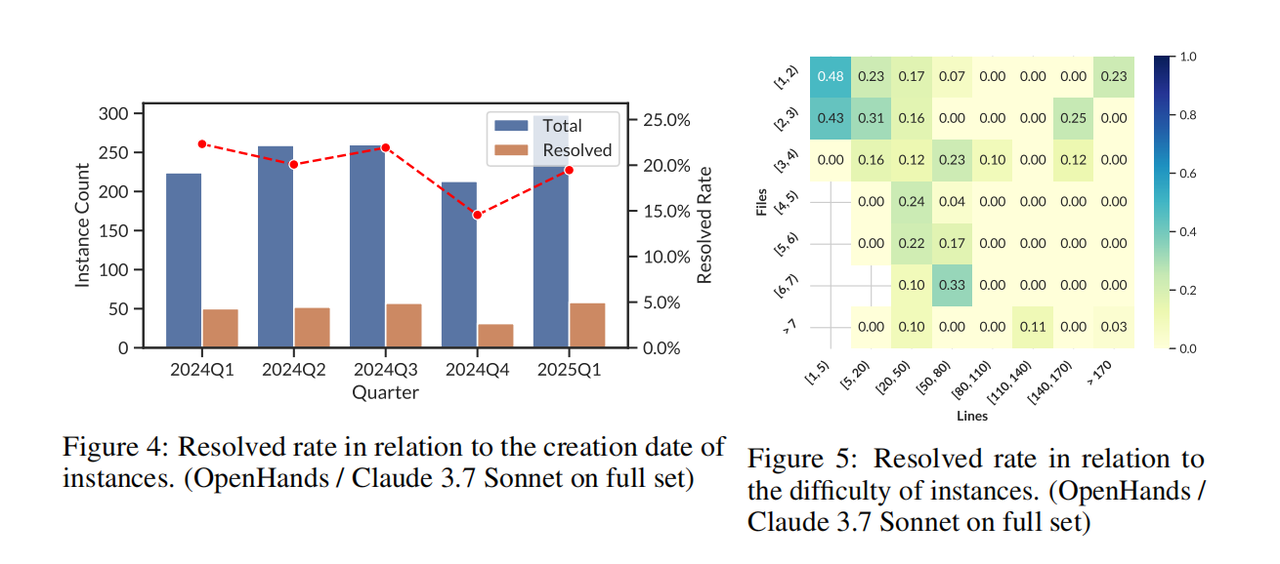
主要洞察为:
当时 Agent 解决该数据集的能力还是不强,基本只有 15% 左右,对于多文件、长上下文修改的能力还是很差
这些 Agent 对于老 SWE-Bench 的解决能力明显强于该数据集,说明可能存在对 SWE-Bench 的过拟合
不同时段仓库的测试结果类似,说明后续进一步拓展数据集来源是可行的
总结
这里提到的用 Agent 参与到 SWE 环境构建流程中的想法确实是一个很好的点,能够快速地把数据 scale up 上去
阅读这篇论文也确实更加清楚了 SWE 数据集的构造流程,构建一个干净的运行环境实在是不容易,但是一个题目一个镜像是真费资源
这里主要都是收集实际场景中的 Issue 与 PR,感觉现在 2026 年应该已经收集得差不多了,肯定有开始用大模型来生成这类数据
Issue 与 PR 构造的数据更多的是提升模型修 bug 的能力而不是从头构建项目的能力,这部分能力应该要如何拓展出来呢,毕竟很多仓库在构建时并没有一个清晰的 plan 文档
不过整体思路还是不算复杂的,但是优点在于确实做出来了,并且做得很早,从而能够形成影响力