阅读笔记:Agentic RL 时代的 Infra 重构(Forge、ROLL、Seer、Slime)
最近阅读了知乎上的笔记《Agentic RL 时代的 Infra 重构:以 Forge、ROLL、Seer、Slime 为例》(原文链接),深受启发,所以在此简单记录一下。
概览
Agentic RL 系统总的来看是在最大化如下的训练收益:
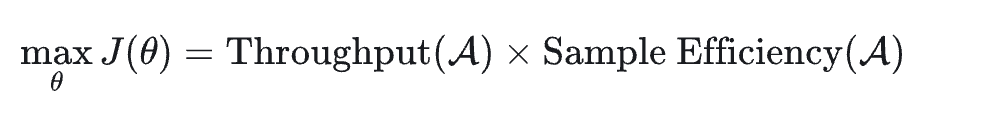
其中 Throughput(吞吐)受到系统中 Rollout、Training、Data Processing 和 I/O 的影响。
Sample Efficiency 指每个样本带来的平均性能收益,取决于数据分布、数据质量、算法效率以及 off-policy 程度。
1. Agentic RL 系统如何处理 Agent
现有系统都不再把 Agent 塞在 RL 系统内部,而是独立处理,作为单独的一层系统抽象来看待。
抽离之后的 Agent 层的作用,是利用数据集中的问题产生轨迹数据,并反哺给训练系统进行训练。
Agent 层最好能够同时支持可自定义 Agent Loop 的白盒 Agent,也支持不暴露 Agent Loop 的黑盒 Agent。
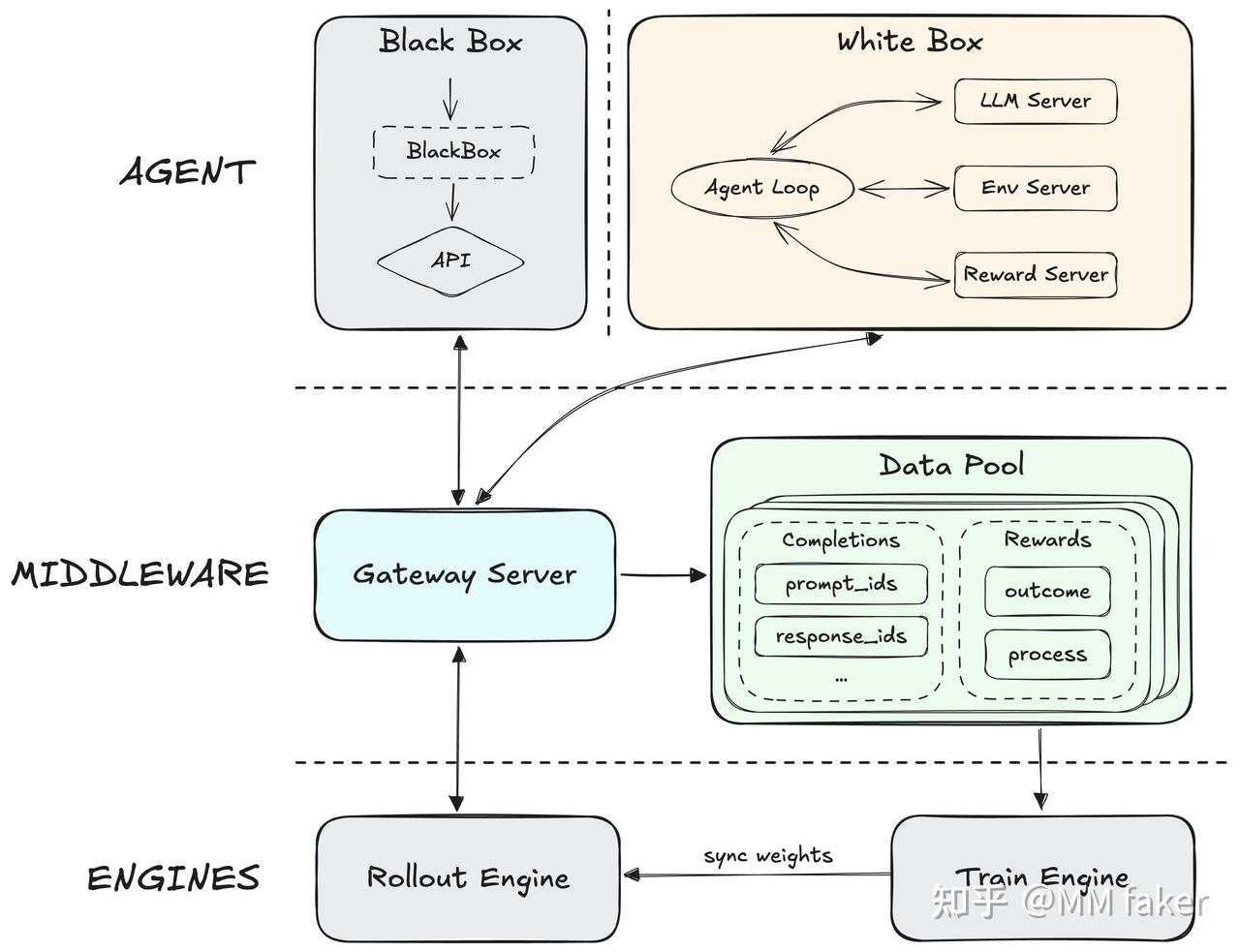
MiniMax 的 Forge 系统如下所示,系统由三个模块组成:
Agent 层:支持白盒与黑盒架构,专注生产轨迹。
Middleware 层:负责连接 Agent 层与 Engines 层;其通过 Gateway Server 给 Agent 提供请求推理转发,并将轨迹数据存储在 Data Pool 中供训练引擎训练。
Engines 层:包括推理与训练引擎。
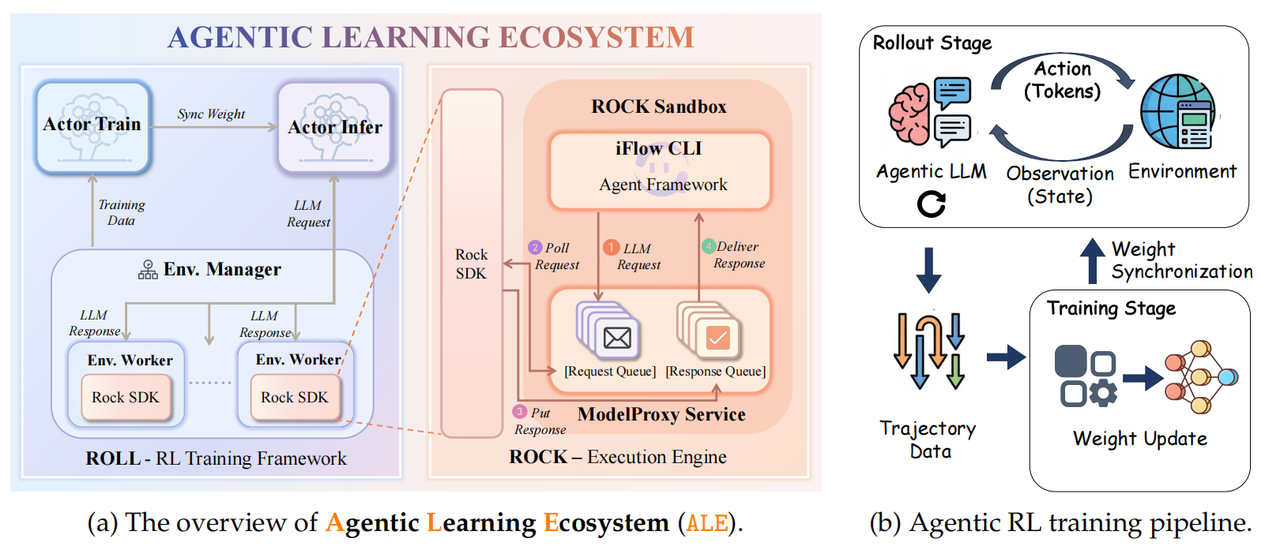
阿里的 ROLL 框架 如下所示,整体设计如下:
ROLL:负责权重优化的后训练框架;
- 包含训练与推理引擎,还存在一个 Env Manager 作为中介层与 Agent 交互,提供请求推理转发与轨迹处理能力。
ROCK:负责生成Sandbox环境并让Agent在其中完成指定的任务;
- 理论上这里的 iFlow CLI 应该可以换成其他 Agent CLI?
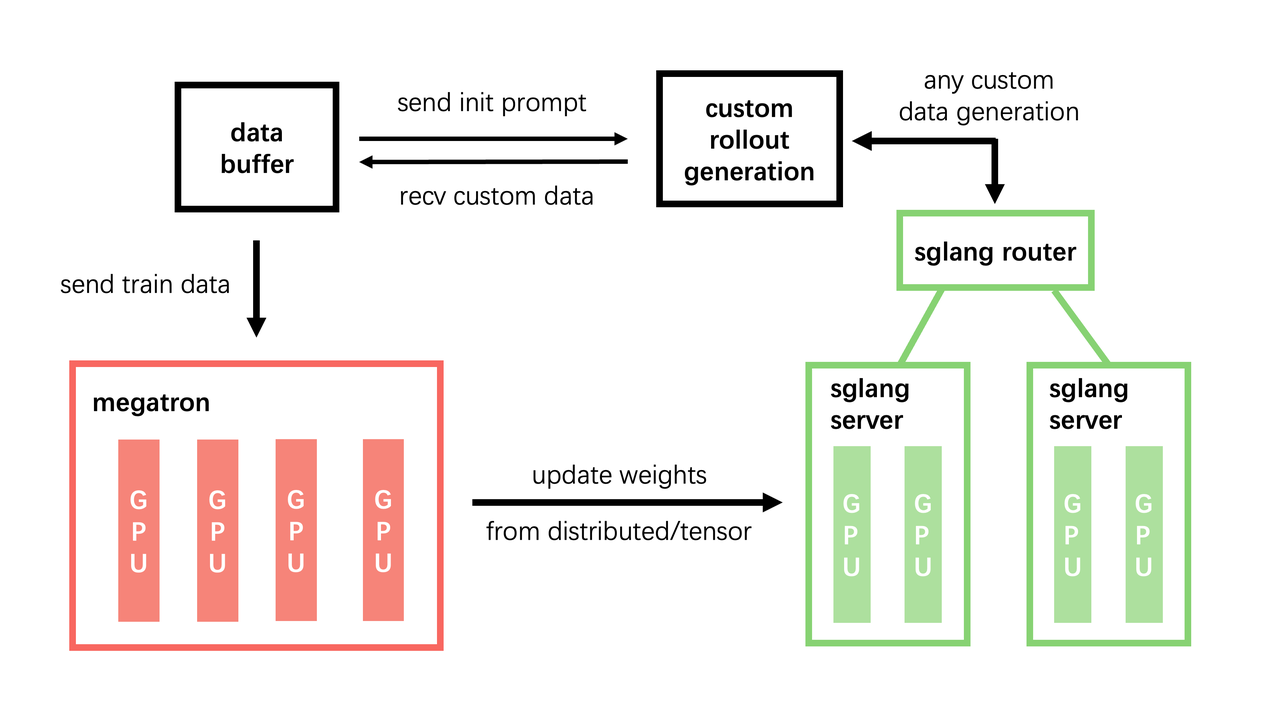
智谱使用的 Slime 框架 如下所示:
- Slime 并没有特别地抽离出一个 Agent 层,而是将 Agent 行为服务化,并将其作为一个 Rollout 服务。这应该与其和 SGLang 结合紧密有关系,也更加轻量化了,但本质上还是将 Agent 相关的事情抽离出来了。
2. 长尾 Rollout 怎么调度
Agentic RL 中任务时长的方差很大,存在长尾任务;严格同步下会放大阻塞,所以往往采用异步策略。
完全异步(即谁先完成谁就先拿去训练)会导致一系列问题需要解决:
off-policy问题,即使用陈旧模型产生的样本
样本偏移问题,即模型学习用到的都是一些短、快的任务样本
训练稳定性问题
Forge使用Windowed FIFO:
假设当前生成队列的头部是 H,训练调度器只能看到一个大小为 W 的窗口:[H, H+W]。
窗口内的任务就是谁先完成谁就先拿去训练,而窗口外的样本轨迹不能被提前拿来训练
ROLL 整体设计是异步的;其引入了 asynchronous ratio,去约束“当前训练策略版本”和“生成该样本的策略版本”之间允许的最大差距。
Slime 在 Token 层与 Sample 层都设置了一道检测点:
记录样本在rollout阶段的log-probability,并且也计算该样本轨迹最新训练引擎中的模型的log-probability,对于偏离过大的token直接mask掉。
还比较样本在生成时的模型版本与当前训练的模型版本,如果差距过大直接剔除掉该样本。
Seer坚持了同步策略,但是使用了其他的方法来减少长尾:
把 Group 拆成单个 request,request 再拆成更细的 chunk 来进行调度,从而使得实例间负载更加均衡,长组也不至于一直绑定在某一台机器上从而把实例长时间拖死。KV Cache 也配合做 chunk 切分。
对于GRPO,让每组中一个request先跑,探测出这个任务的大致允许时间,再使用longest-first的策略来安排组内剩余请求的执行顺序。
GRPO组内相似,所以通过前缀树来做加速。
3. 如何消除前缀冗余与重复计算?
Agentic RL中,同一条轨迹的多轮请求、group内的responses之间都存在大量的共享前缀,如果都当成独立样本处理会带来大量的重复计算,所以需要进行针对性优化。
目前的优化思路都是将请求组织为前缀树的结构,使得共享前缀只需要计算一次。
4. Rollout 推理怎么加速?
Agentic RL 中 Rollout 的主要成本仍大量集中在推理阶段,所以必须进行优化。这里主要存在 speculative decoding 与 MTP(Multi-Token Prediction)加速两类。
Speculative decoding:引入一个参数规模更小、推理成本更低的 draft model来自回归地预测生成,再由原本的大模型进行并行校验并选择合适的生成结果。
MTP(Multi-Token Prediction):在主模型 backbone 上额外挂一个 multi-token prediction head,使模型能够在单次前向中直接预测多个未来位置的 token 分布。
但是在 RL 训练中,由于模型会随着训练一直变化,导致如果还用原本的 draft model 或者 multi-token prediction head 会预测不准,所以需要进行改进。
Forge采用MTP进行加速,但是会在 RL 训练过程中持续训练 detached MTP head;并且用 Top-K KL Loss 保持它与当前训练模型对齐。
Seer 利用 GRPO 组内生成相似的特点,收集组内的 response 并进行组织;decode 时如果发现同组已经有相似的 prefix,就将其作为 draft token 的候选来源。
Slime支持MTP并使用 FP8 rollout inference 来进一步降低 rollout 路径上的 generation 成本,还进行了PD分离。
5. 长时序信用分配与稳定优化
Agentic RL中一条轨迹包含了多次环境交互、工具调用、观察反馈和再决策,如果只关注最终结果,其奖励往往过于稀疏。
Forge设计了三类复合奖励来解决奖励稀疏的问题:
过程奖励: 监督 agent 的中间行为(如惩罚语言混合或特定工具调用错误),提供密集反馈,而不只依赖最终结果。
任务完成时间奖励:将相对完成时间作为奖励信号,激励 Agent 主动利用并行策略、选择最短的执行路径来加速任务。
用于降低方差的后续奖励:Forge使用 Reward-to-Go 来标准化回报,即仅取当前步到结束的累积奖励,从而大幅提高了信用分配的精度,稳定了优化过程。
ROLL 提出要把 agentic task 建模成 Chunked MDP。一个 chunk 指的是从一次环境交互到下一次环境交互之间的一段连续片段,通常以一次工具调用结束。其使得回报不再沿 Token 传播,而是沿 chunk 传播,并使用了一系列算法来适配 chunk 化。
6. 环境可靠性、测试可信度与奖励污染
在 Agentic RL 中,环境清洁度、测试可信度和安全边界,不是训练之外的附属问题,而是 reward 正确性本身的一部分。
ROLL 提出环境必须保持干净,要清除临时文件、历史运行结果、配置文件、测试脚本或测试相关目录等内容。否则 Agent 可能会直接读取或修改测试文件,乃至直接操作 web 根目录来伪造结果,或者修改环境配置以绕过原任务要求。所以其在 Rollout 前都会主动清理环境,并且只在最终评估阶段才加载测试文件。
ROLL还提出需要注意伪阳性样本,即那些测试通过但实际并没有完成的情况,所以其对环境进行了提前筛选,剔除了那些Ground-truth都通过不了以及No-op都能通过的环境,还加入了LLM-as-judge 来验证输出。
ROLL 还有意识地引入了环境的多样性。其会构建不同版本的软件包、使用不同的配置、故意移除某些依赖,或者故意构造部分不可用的环境,来使得模型的训练场景更贴近真实的工程环境。